ChatGPT 论文:Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models (二)
发布时间:2024年01月09日
3 实验
3.1 实验设置
数据集
Spider:复杂文本到SQL问题的跨领域数据集。
Spider-Syn:使用同义词替换Spider问题中的模式相关词汇,评估系统的鲁棒性。
Spider-DK:在Spider示例中添加领域知识,评估跨领域泛化能力。
Spider-Realistic:去除列名的明确提及,模拟更现实的文本-表格对齐设置。
模型
使用Codex(基于GPT-3的变体)和ChatGPT (gpt-3.5-turbo)来评估不同ICL策略。
Codex在1到10-shot范围内提供结果,而ChatGPT因最大上下文长度限制仅提供1到5-shot的结果。
评估指标
使用执行准确度作为所有实验的评估指标。
Baseline
主要分为Few-shot和Zero-shot上的实验,包括:
Few-shot
- Random sampling ?: 从样本池中随机选择示例。
- Similarity sampling (S)
- Diversity sampling (D): 从样本池的k-Means聚类中选择多样化示例。
- Similarity-Diversity sampling (SD): 根据算法1选择示例。
- SD + schema augmentation (SA): 通过架构知识增强指令(语义增强或结构增强)。
- SD + SA + Voting: 根据算法2描述的综合策略。
Zero-shot
- Baseline - DB as text-seq: 文本到SQL任务的标准提示,其中结构化知识被线性化为文本序列。
- Baseline - DB as code-seq: 通过将结构化知识源线性化为多个SQL CREATE查询来改进指令。
- Baseline - DB as code-seq + SA: 通过架构知识增强指令。
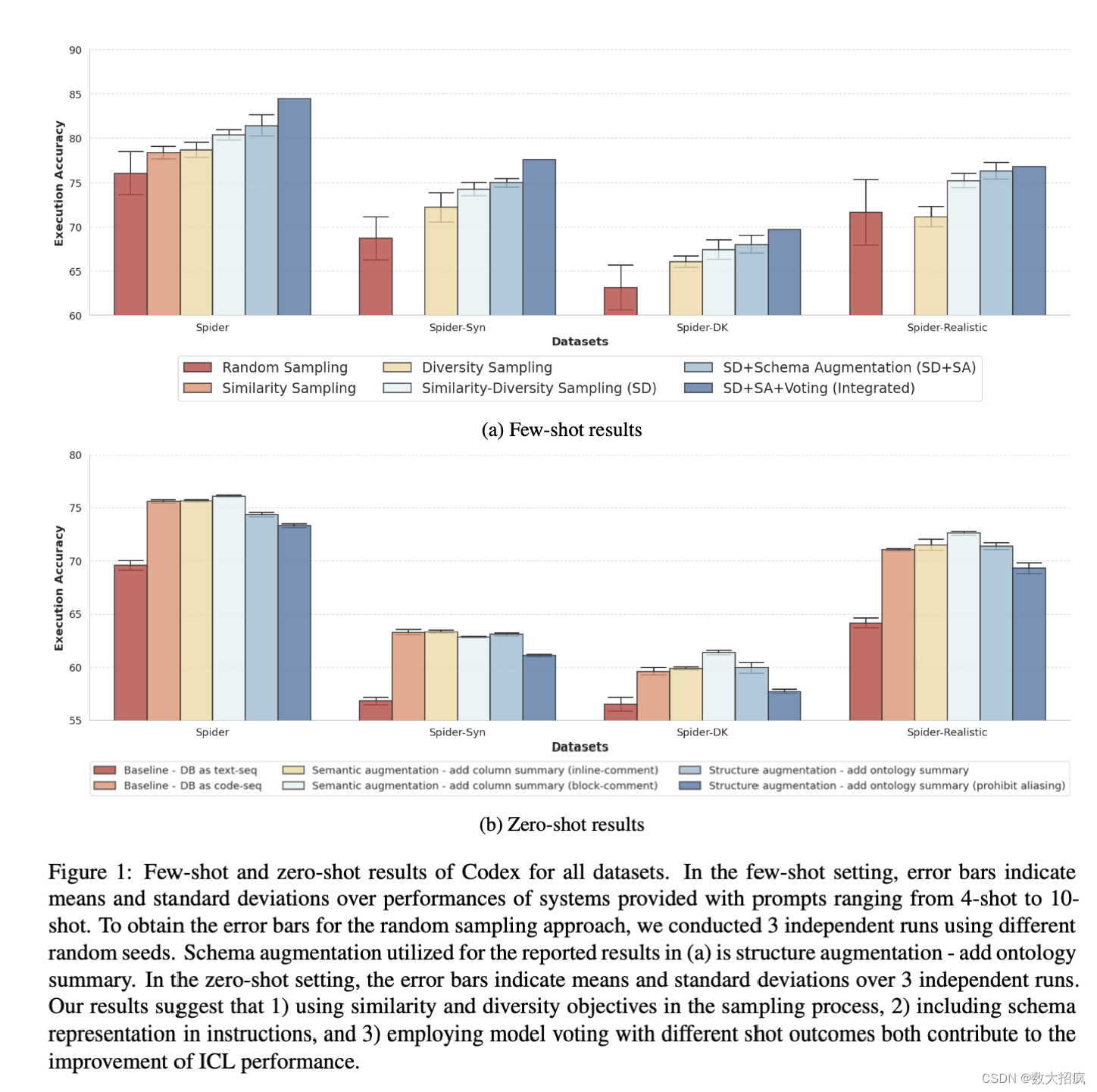
3.2 主要结果
在code-davinci-002和gpt-3.5-turbo模型上测试了不同示例选择策略的效果。主要发现如下:
- 相似性和多样性目标的采样过程:结合相似性和多样性目标在采样过程中可以获得更好的性能。
- 架构表示的增强:在指令中加入架构表示(就是Listing 5中的最下面的那几行注释)可以提高性能。
- 投票集成策略:结合不同示例数量模型的结果进行投票,可显著提高整体性能。
- 架构增强在零次学习中的效果:将数据库转换为文本序列和CREATE查询的两种提示线性化方法进行了比较。后者显示出明显的性能提升。
- 两种架构增强技术的对比:一种在表中的每列中添加语义信息,另一种加入实体关系知识。结果表明,结构增强(添加本体概要)在Few-shot设置中为Codex带来更大的改进,而语义增强(作为块注释添加列概要)在Zero-shot设置中对Codex以及Few-shot设置中对ChatGPT更有益。
研究显示,通过探索和实施不同的提示设计策略,可以显著提高LLMs在文本到SQL任务中的性能。这些策略不仅包括示例选择的优化,还包括架构表示的增强和投票集成方法的应用。通过这些策略,为利用LLMs在文本到SQL领域中的应用提供了有力的实证支持。
文章来源:https://blog.csdn.net/rkjava/article/details/135468456
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HiEV洞察|蔚来NIO Phone的前途,藏在车手互联的技术栈里
- PyTorch 内 LibTorch/TorchScript 的使用
- 个人电脑蓝屏问题的几个解决方法
- 可直接将视频转文字的工具,速到快到离谱!
- 【Java】猜数字小游戏
- 多节点 docker 部署 elastic 集群
- 漏洞复现--用友GRP-U8-FileUpload任意文件上传
- openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证
- 第四十一章 XML 映射参数摘要
- 基于Python Django的大数据招聘数据分析系统,包括数据大屏和后台管理