检索增强生成(RAG)技术创新进展:自我检索、重排序、前瞻检索、系统2注意力、多模态RAG
检索增强生成(RAG)提供了一种将ChatGPT/GPT-4等大型语言模型与自定义数据集成的途径,但存在局限性。让我们了解RAG最近的研究创新如何解决其中的一些问题。
大型语言模型(LLM)将彻底改变很多分析领域应用。一个用例是LLM+RAG可以调研大量文档,并在很短的时间内以分析师的一小部分成本找到趋势。但问题是—很多时候你得到的答案只是部分且不完整的。举例来说,您有一个文档,其中包含X公司过去15年的年收入,但这些数据位于不同的部分。在如下图所示的标准检索增强生成(RAG)架构中,RAG通常检索前k个文档,或选择固定上下文长度内的文档。

传统的检索-增强生成在传统的检索-增强生成模型中,方法一般是在生成过程开始时执行一次检索。这种方法包括接收一个初始查询,并根据该查询检索相关文档。然后,模型使用这些文档生成内容。不过,这种方法也有其局限性,尤其是在处理冗长复杂的文本时。
传统RAG方法的局限性包括:
-
单一检索:一旦检索到初始文档,模型就会继续仅根据这组初始信息生成内容。
-
缺乏灵活性:随着生成的进行,模型不会更新或检索新的信息,以适应正在生成的内容不断变化的背景。
-
潜在的过时或不完整信息:如果随着文本的生成,新的信息变得相关,由于模型依赖于最初检索到的文档,因此可能无法捕捉到这些信息。
-
多重检索:利用过去的上下文,以固定的间隔检索额外的信息。这意味着每检索10个单词或1个句子,不管你是否想检索。
另外,标准RAG架构会带来一些问题。一个问题是top-k文档并不包含所有答案——例如可能仅对应于过去5或10年。另一个问题是计算文档块和提示之间的相似性并不总是产生相关的上下文。在这种情况下,可能会得到错误的答案。
让我们看一下RAG最近的一些创新,看看它们如何为上述问题提供解决方案。
1 - 自我反思学习检索(Self-RAG)
Self-RAG让经过微调的语言模型(Llama2-7B和13B)输出特殊标记[检索]、[不检索]、[相关]、[不相关]、[不支持/矛盾]、[部分支持]、[实用性]等,附加到LM生成中,以决定上下文是否相关/不相关、LM从上下文生成的文本是否支持以及生成的实用性。

Self-RAG是一个新的框架,它通过自我反思标记来训练和控制任意的LM。具体来说,在每个语段(如句子),Self-RAG可以:
-
检索:Self-RAG首先解码一个检索标记,以评估检索的效用并控制检索组件。如果需要检索,LM会调用外部检索模块,利用输入查询和上一次生成的信息,找到最相关的文档。
-
生成:如果不需要检索,模型就会像标准LM一样预测下一个输出段。如果需要检索,模型首先生成评论标记,评估检索到的文档是否相关,然后根据检索到的段落生成续篇。
-
批判:如果需要检索,模型会进一步评估段落是否支持生成。最后,一个新的批判标记会评估回复的整体效用。
下图展示了在训练过程中添加到Self-RAG词汇表中的不同类型的反思标记:

Sefl-RAG标记列表。图源:https://selfrag.github.io/
1.1 -?Self-RAG训练
Self-RAG的训练分两步进行:
-
第一步,训练一个简单的LM来对生成的输出(提示或提示+RAG增强输出)进行分类,并在末尾添加相关的特殊标记。这个"批评者模型"是通过GPT-4注释训练出来的。具体来说,GPT-4是使用特定类型的指令进行提示的("给定一个指令,请判断从网上查找一些外部文档是否有助于生成更好的回复")。
-
在第二步中,生成器模型使用标准的下一个标记预测目标,学习生成连续句以及特殊标记,以检索/批判生成。与其他微调或RLHF方法不同的是,其他方法的下游训练可能会影响模型输出并使后代产生偏差,而通过这种简单的方法,模型只需在适当的时候训练生成特殊标记,而不会改变底层LM!这是非常有新意的设计!

1.2 - Self-RAG评估
Self-RAG针对公共卫生事实验证、多项选择推理、问答等进行了一系列评估。共有3种类型的任务。闭集任务包括事实验证和多项选择推理,并以准确性作为评价指标。简短的生成任务包括开放域问答数据集。作者评估了模型生成中是否包含正确答案,而不是严格要求精确匹配。
长篇生成包括传记生成和长篇问答。为了评估这些任务,作者使用FactScore来评估传记——基本上是对生成的各种信息及其事实正确性的衡量。对于长格式的QA,使用了引用精度和召回率。
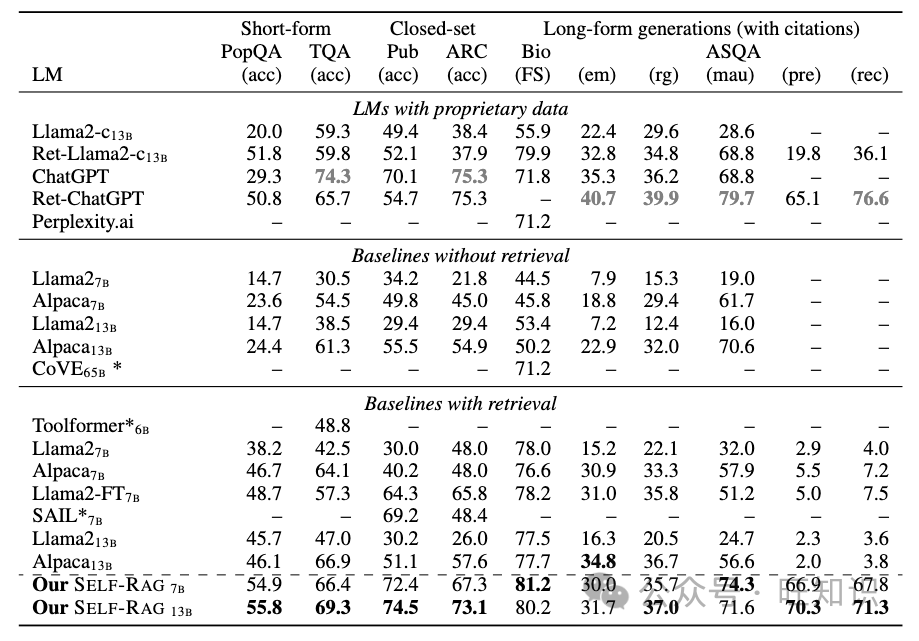
Self-RAG在非专有模型中表现最好,并且在大多数情况下较大的13B参数优于7B模型。在某些情况下它甚至优于ChatGPT。
1.3?-?Self-RAG推理
对于推理,Self-RAG存建议使用vllm—一个用于LLM推理的加速库。
pip安装vllm后,可以加载库并查询,如下:
from vllm import LLM, SamplingParams
model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
def format_prompt(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the difference between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))对于需要检索的查询,可以在下面的示例中以字符串形式提供必要的信息:
paragraph="""Llamas range from 200 to 350 lbs., while alpacas weigh in at 100 to 175 lbs."""def format_prompt_p(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))在上面的示例中,对于第一个查询(与社交媒体平台相关),段落上下文是不相关的,正如检索开始时的[Irrelevant]标记所反映的那样。然而,外部上下文与第二个查询相关(与美洲驼和羊驼相关)。它在生成的上下文中包含此信息,并用[Relevant]标记进行标记。
但在下面的例子中,上下文是“I like Avocado”,它与Prompt无关。如下所示,模型预测对于两个查询均以[Irrelevant]开始,并且仅使用内部信息来回答提示。
paragraph = "I like Avocado."
def format_prompt_p(input, paragraph=paragraph):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))与普通的LLM相比,Self-RAG有如下优势:
-
自适应段落检索:通过这种方式,LLM可以继续检索上下文,直到找到所有相关上下文(当然在上下文窗口内)。
-
更相关的检索:很多时候,嵌入模型在检索相关上下文方面并不是最好的。Self-RAG可能通过相关/不相关的特殊令牌解决这个问题。
-
击败其他类似模型:Self-RAG击败了其他类似模型,并且在许多任务中也令人惊讶地击败了ChatGPT。与ChatGPT未经训练的数据(更多专有的工业数据)进行比较会很有趣。
-
不会改变LM本身:我们知道微调和RLHF很容易导致模型出现偏差。Self-RAG通过添加特殊标记来解决这个问题,并保持文本生成相同。
2 - 重排序模型(Re-ranking Models)
与其他RAG创新相比,重排序是一个简单(但功能强大)的想法。其原理是,首先检索大量文件(例如n=25)。然后,训练一个较小的ReRanker模型,从25个文档中选出前k个(比如3个)文档,并将其作为LLM上下文。这是一项很酷的技术,从概念上讲也很有意义--因为获取前k个上下文的底层嵌入模型并不是针对知识检索训练的,所以针对特定的RAG场景训练一个较小的重排序器模型是很有意义的。
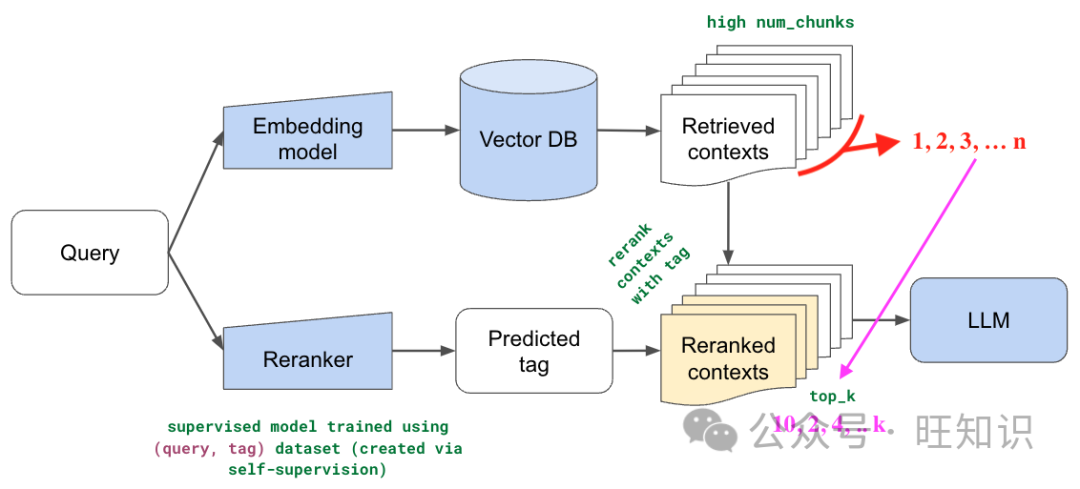
重排序模型。图源:https://github.com/lancedb/vectordb-recipes/blob/main/examples/RAG_re_ranking/main.ipynb
在典型的RAG管道中,LLM上下文窗口是有限的,因此对于一个假设的10000页文档,我们需要对文档进行分块。对于任何传入的用户查询,我们都需要获取前N个相关的分块,而且由于我们的"嵌入"(Embedding)不是100%准确的,搜索算法也不是完美的,因此也可能给出不相关的结果。这是RAG管道的一个缺陷。如何处理?如果您获取的是Top-1,而上下文不同,那么答案肯定不好。另一方面,如果获取更多的数据块并传递给LLM,它就会感到困惑,而且随着数据块数量的增加,它就会脱离上下文。
那么如何补救以上问题呢?在所有可用的方法中,重新排序是最简单的。思路很简单。
-
首先,假设嵌入+搜索算法并非100%精确,那么就可以利用召回的优势,从语料库中获得N(比如25)个相似的相关语块。
-
第二步是使用强大的模型来提高精确度。您可以再次对N个以上的查询进行重新排序,这样就可以改变相对排序,现在可以选择前K个查询(例如3个)作为上下文,其中K<N,从而提高精确度。
3 - 前瞻性主动检索增强生成(FLARE)
FLARE是前瞻性主动检索增强生成(Forward-Looking Active Retrieval Augmented Generation)的缩写。这是一种补充LLM的方法,在模型生成内容的过程中主动纳入外部信息。这一过程大大降低了出现幻觉的风险,确保内容不断得到外部数据的检查和支持。
FLARE用于处理希望答案正确且最新的情况,对于这种情况,通过实时更新的知识中心(互联网)来增强LLM知识是有意义的。一种解决方案是将迭代互联网搜索和LLM知识结合起来。
在此工作流程中,首先用户提出问题,LLM生成初始的部分句子。这部分生成充当互联网搜索查询的种子。然后,该查询的结果将被集成到LLM响应中,并且这个持续搜索和更新的过程将持续下去,直到生成结束。

前瞻性主动检索增强生成示意图。图源:arxiv.org/pdf/2305.06983.pdf
作为示例,用户输入查询是“生成一份关于拜登的摘要”,流程如下:
-
用户查询:任务以用户的请求开始:"生成关于拜登的摘要”。
-
生成初始句子:模型开始制作内容,生成类似"拜登出席会议"这样的开头语。
-
启动重点搜索:此时,模型会激活一个搜索查询:"[搜索(拜登大学)]"。
-
暂停和搜索:内容生成暂时停止。然后,模型深入搜索"拜登大学"。
-
检索和整合:接下来,模型与检索器通信,获取"拜登大学"的相关数据。它能有效地检索和整合诸如"宾夕法尼亚大学"等信息。
-
继续搜索和更新:这一过程并未就此结束。模型再次启动搜索,这次是"[搜索(拜登学位)]"。按照同样的协议,它将检索并整合新的数据,例如有关他的法律学位的信息。
这种生成和检索相结合的迭代过程确保了人工智能模型能够生成信息充分、准确的摘要,并动态地纳入相关的最新信息。
4 - 系统2注意力(S2A)
系统2注意力(S2A)由META发布,试图用更多的技巧来解决虚假上下文的问题。S2A不会像Self-RAG或重新排名那样将上下文标记为相关/不相关,而是会重新生成上下文以消除噪声并确保保留相关信息。

LLM受到虚假相关性的不利影响。图源:arxiv.org/pdf/2311.11829.pdf
S2A通过要求LLM重新生成上下文的特定指令来工作,提取有利于为给定查询提供相关上下文的部分,如下所示。

图源:arxiv.org/pdf/2311.11829.pdf
总体而言,根据多项评估,S2A的准确度比传统RAG实现高出约15%。

S2A提升问答事实性。图源:arxiv.org/pdf/2311.11829.pdf

S2A提升数学问题准确率。图源:arxiv.org/pdf/2311.11829.pdf
5 - 多模态RAG
最后,我们讨论最令人兴奋的RAG方向之一,它可能会导致行业用例的爆炸式增长,即可以跨不同类型的数据(文本、视觉、音频等)进行搜索的多模态RAG。
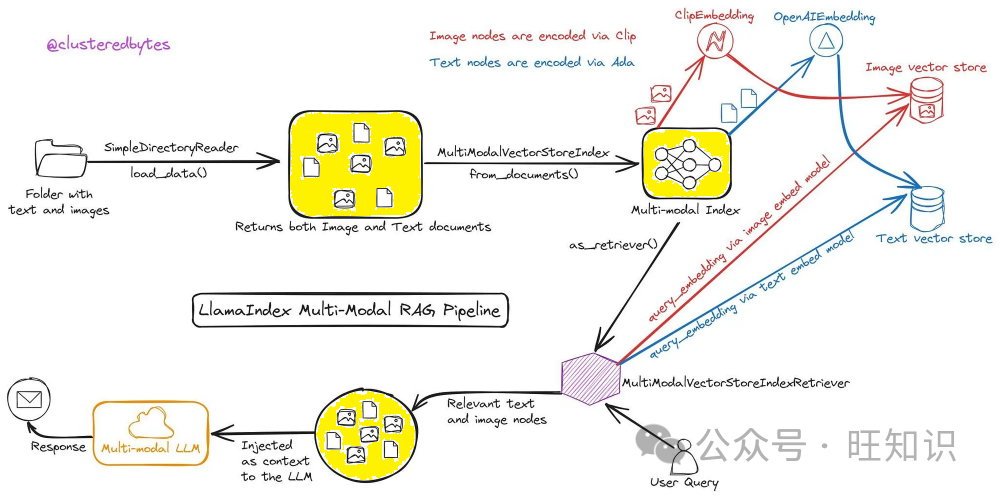
上面的架构使用对比语言图像预训练(CLIP)嵌入,可以同时生成图像和文本的嵌入。嵌入可用于提取与问题最相似的前k个上下文(图像+文本)。下一步是将这些上下文和输入结合起来,并输入到GPT-V或LLaVa等多模态模型中,以合成最终响应。
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HTML学生个人网站作业设计:游戏网站设计——超级英雄(11页) HTML+CSS+JavaScript 简单DIV布局游戏介绍网页模板代码 DW学生游戏网站制作成品下载
- 基于STM32F103的病房监控系统的设计
- PHP函数里面写JQ CSS HTML的写法案例
- SecOC中新鲜度值和MAC都按照完整的值来生成,但是在发送和认证的时候只会截取一部分。这边截取的部分一般取多长?由什么参数设定?
- 广州市生物医药及高端医疗器械产业链大会暨联盟会员大会召开,天空卫士数据安全备受关注
- Sqlmap参数设置
- k8s pod基础 1
- 2024年现货白银趋势分析
- 【C++】C++的IO流
- 开源堡垒机JumpServer结合内网穿透实现远程访问