爬虫正则+bs4+xpath+综合实战详解
发布时间:2024年01月23日
聚焦爬虫:爬取页面中指定的页面内容
????????????????编码流程:指定url -> 发起请求 -> 获取响应数据 -> 数据解析 -> 持久化存储
数据解析分类:正则、bs4、xpath(本教程的重点)
数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
????????????????????????????????1.进行指定标签的定位
????????????????????????????????2.标签或者标签对应的属性中存储的数据值进行提取(解析)
图片的爬取
图片是以二进制方式存储的,复制图片链接输入浏览器可以得到图片对应的url
import requests
url = 'https://img-blog.csdnimg.cn/09ad194be31144e9b628bcd26916c144.png'
# content返回二进制形式的图片数据
image_data = requests.get(url).content
with open('picture.png', 'wb') as fp:
fp.write(image_data)由于糗事百科停运了,所以找了个美女照片网站
对图片进行检查,看到图片的url都是放在img标签里的,而src后面的值就是它的url
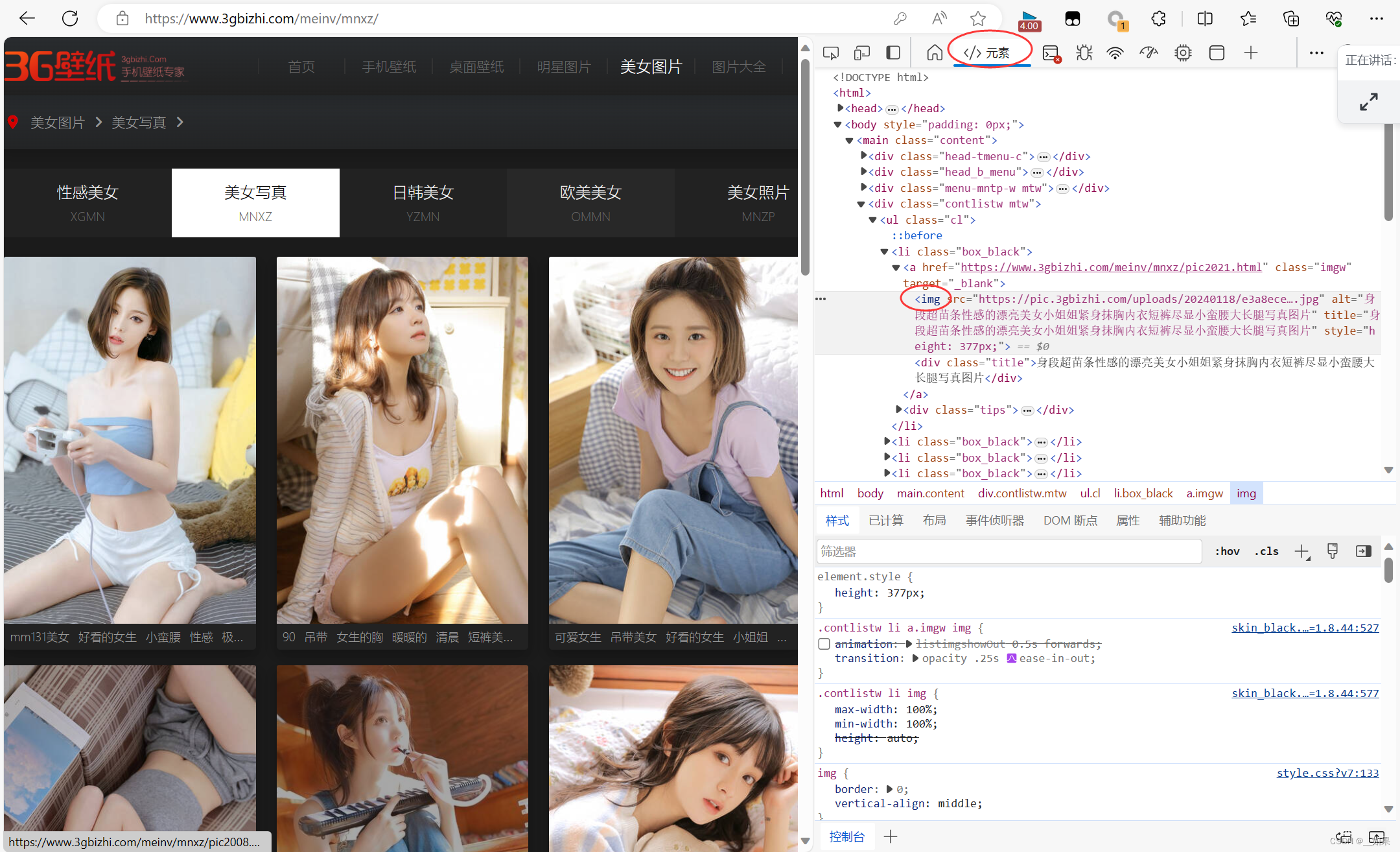
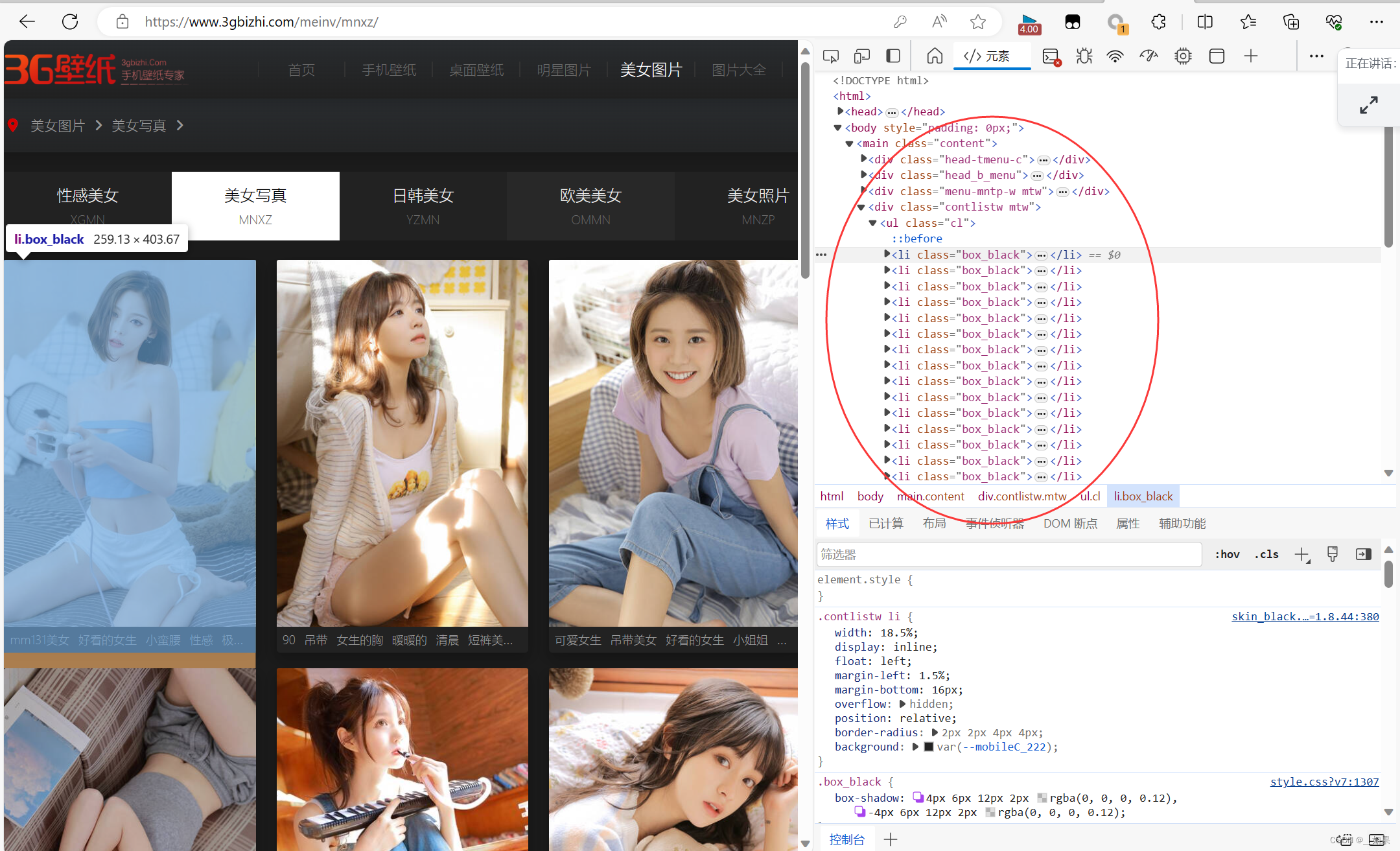
观察图片的层级关系,发现都在<ul class="cl">下,在<li class>中
import re
import requests
import os
if not os.path.exists('./girls_picture'):
os.makedirs('girls_picture')
url = 'https://www.3gbizhi.com/meinv/mnxz/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
response = requests.get(url, headers=headers)
page_text = response.text
# 使用聚焦爬虫对页面的信息进行解析
ex = '<li class="box_black">.*?<img src="(.*?)" alt.*? </li>'
img_src_list = re.findall(ex, page_text, re.S)
new_img_src_list = []
for i in img_src_list:
i = i[51:]
new_img_src_list.append(i)
print(new_img_src_list)
for src in new_img_src_list:
image_data = requests.get(src, headers=headers).content
image_name = src.split('/')[-1]
image_path = 'girls_picture' + '/' + image_name
with open(image_path, 'wb') as fp:
fp.write(image_data)
print(image_name + '下载成功')
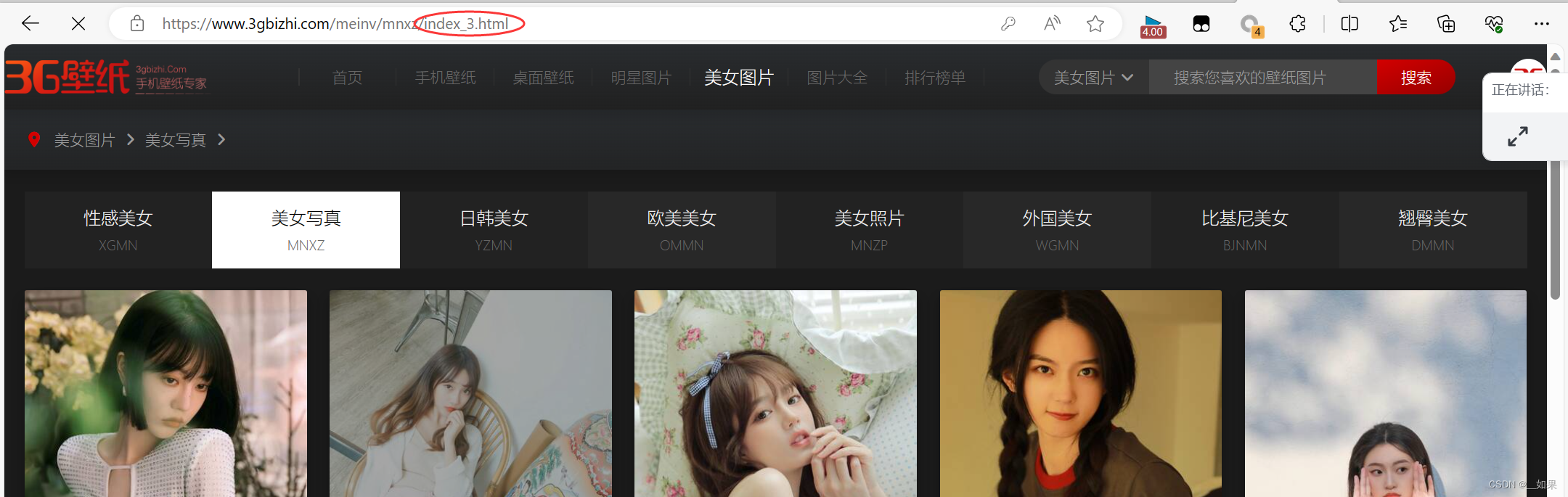
多页爬取
我们发现翻页的url变动是有规律的,因此只需for循环更改index后面的数字
import re
import requests
import os
if not os.path.exists('./girls_picture'):
os.makedirs('girls_picture')
url = 'https://www.3gbizhi.com/meinv/mnxz/index_%d.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
for i in range(1, 4):
new_url = format(url % i)
response = requests.get(new_url, headers=headers)
page_text = response.text
# 使用聚焦爬虫对页面的信息进行解析
ex = '<li class="box_black">.*?<img src="(.*?)" alt.*? </li>'
img_src_list = re.findall(ex, page_text, re.S)
new_img_src_list = []
for i in img_src_list:
i = i[51:]
new_img_src_list.append(i)
print(new_img_src_list)
for src in new_img_src_list:
image_data = requests.get(src, headers=headers).content
image_name = src.split('/')[-1]
image_path = 'girls_picture' + '/' + image_name
with open(image_path, 'wb') as fp:
fp.write(image_data)
print(image_name + '下载成功')
文章来源:https://blog.csdn.net/m0_73202283/article/details/135765424
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024/1/14周报
- 前端Vue日常工作中--Vue实例属性
- metagpt学习实践
- 201.【2023年华为OD机试真题(C卷)】最长子字符串的长度(一)(滑动窗口算法-Java&Python&C++&JS实现)
- Go 语言为什么不支持并发读写 map
- python实现贪吃蛇游戏
- Android Studio 如何设置中文
- Python从入门到精通秘籍七
- Making Large Language Models Perform Better in Knowledge Graph Completion
- Agilent安捷伦E4407B频谱分析仪26.5GHz