2024 1.13~1.19 周报
一、本周计划
????????确定论文题目,重新思考能加的点子,重点在网络架构部分。主要了解了注意力模块如SE、CBAM、CA,在模型中插入注意力模块。读论文。
二、完成情况
2.1 论文题目
????????基于注意力的Unet盐体全波形反演
????????想法来源:使用的是二维盐体数据,让网络更加关注于盐体部分,在深度学习网络中引入注意力机制,可以简化模型,加速计算。
2.2 为什么要引入 Attention 机制?
????????在深度卷积神经网络中,通过构建一系列的卷积层、非线性层和下采样层使得网络能够从全局感受野上提取图像特征来描述图像,但归根结底只是建模了图像的空间特征信息而没有建模通道之间的特征信息,整个特征图的各区域均被平等对待。????????
????????然而,这些信息对图像能否被正确识别的影响力是不同的,如何让模型知道图像中不同局部信息的重要性呢?——答案就是注意力机制。
2.3?注意力模块
????????Attention的核心思想是:从关注全部到关注重点。Attention 机制很像人类看图片的逻辑,当看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。注意力机制主要有:自注意力(self-attention)、软注意力(soft-attention)、硬注意力(hard-attention)。其已经广泛应用于分类、检测、分割等任务。
????????soft-Attention模块其分类主要有:通道注意、空间注意。soft-Attention是参数化的,因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。与分类、回归训练原理完全一致
- 空间注意力模块?对特征图每个位置进行attention调整,(x,y)二维调整,使模型关注到值得更多关注的区域上。旨在提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。
- 通道注意力模块?旨在显示的建模出不同通道之间的相关性,通过网络学习的方式来自动获取到每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而来强化重要的特征抑制非重要的特征。
????????许多软注意力模块都不会改变输出尺寸,所以可以很灵活的插入到卷积网络的各个部分,但会增加训练参数,从而导致计算成本有所提高,所以越来越多模块注重参数量和精度的平衡,很多轻量型注意模块也随之提出。
2.3.1 挤压和激励注意力(Squeeze-and-Excitation attention, SE)
论文:[1709.01507] Squeeze-and-Excitation Networks (arxiv.org)
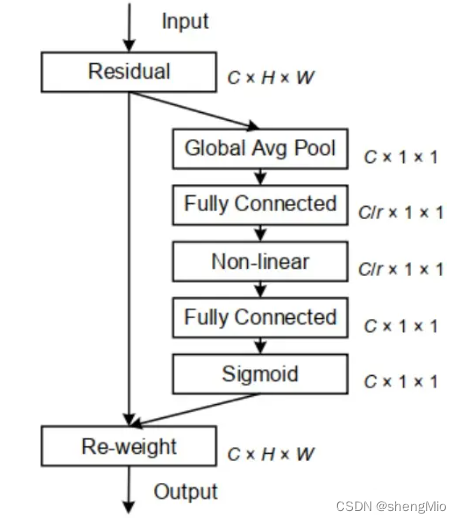
????????受生物学习启发, 作者提出了SE模块,旨在通过使网络能够动态调整各通道的权重(通道注意力),从而重新校准特征来提高网络的表示能力。结构简单且效果显著,通过特征重标定的方式来自适应地调整通道之间的特征响应。
????????SE模块通过引入一个Squeeze操作和一个Excitation操作来建模通道之间的关系。在Squeeze阶段,它通过全局平均池化操作(Global Average Pooling, GAP)将卷积层的输出特征图压缩成一个特征向量。然后,在Excitation阶段,通过使用全连接层和非线性激活函数(用Sigmoid激活函数实现特征重标定,强化重要特征图,弱化非重要特征图),学习生成一个通道的权重向量。这个权重向量被应用于原始特征图上的每个通道,以对不同通道的特征进行加权。
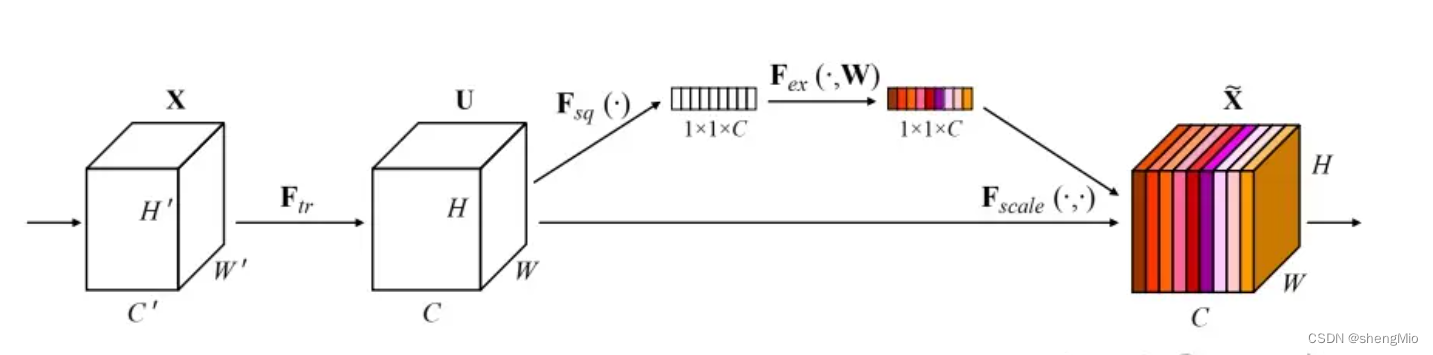
1. Squeeze操作:全局信息嵌入
- 假设输入的特征图为X,其尺寸为C×H×W,其中C是通道数,H和W分别是高度和宽度。
- 在Squeeze操作中,我们对特征图进行全局平均池化,将其压缩成一个特征向量。这可以通过对每个通道的特征图进行平均操作来实现。
- 将池化操作后的特征向量记为
,其中
表示通道c的压缩特征。
????????为了缓解变换输出U的每个单元不能利用该区域之外上下文信息的问题,通过使用全局平均池来生成通道统计信息,来实现将全局空间信息压缩到信道描述符中。通过U的空间维度H×W收缩U来生成统计量,从而z的第c个元素计算为:?????
???
????????在SE模块中,压缩操作是为了降低特征图的维度,将其从C×H×W的三维形状转换为一个C维的特征向量。压缩操作有几个目的和好处:
- 减少计算量:较低维度的特征向量可以显著减少计算量。相比于对整个特征图的每个通道进行操作,只需要对特征向量进行计算,可以加速模型的训练和推理过程。
- 降低参数量:通过压缩特征图,SE模块减少了全连接层的输入维度,从而减少了需要学习的参数量。这有助于减小模型的复杂性,降低过拟合的风险,并提高模型的泛化能力。
- 引入通道间关系:通过对特征图进行全局平均池化操作,SE模块将整个特征图的信息汇总到一个特征向量中。这样做有助于捕捉不同通道之间的关系和交互,从而更好地建模通道之间的重要性。
2. Excitation操作:
- 在Excitation操作中,我们使用一个全连接层和非线性激活函数来学习每个通道的权重,以捕捉通道之间的关系。假设全连接层的参数为
和
,其中
是一个较小的维度。
- 首先,将特征向量C输入到一个全连接层:
,其中
表示非线性激活函数(ReLU)。
- 然后,将全连接层的输出
?输入到另一个全连接层:
,其中
的物理意义是特征变换和特征提取。特征变换和特征提取:将N个D维向量与D×D维权重矩阵相乘可以实现特征变换和特征提取。这种操作可以将输入特征通过线性组合映射到一个新的特征空间,其中权重矩阵表示了特征之间的权重关系。这有助于网络学习输入数据中的重要特征,并提取对任务有用的表示。? 为什么应用sigmoid激活函数?在某些情况下,需要将神经网络输出限制在0到1之间。
- 最终得到的输出
表示每个通道的权重向量。
3. Scale操作:
- 将学习到的权重向量
应用于输入的特征图X上的每个通道。
- 对于每个通道X,将其对应的特征图
与权重
相乘得到加权后的特征图:
。
- 最后,将所有加权的特征图重新组合起来,得到最终的输出特征图
。
整个SE模块的过程可以表示为:
,其中?Pool?表示全局平均池化操作,?ReLU?表示ReLU激活函数,?sigmoid?表示sigmoid激活函数。这个公式可以自动反向传播以进行训练,通过梯度下降法调整
和
的值,以优化模型的性能。通过学习每个通道的权重,SE模块能够自适应地调整特征图。
4. SE模块总结
????????SE模块可以被理解为一种自动学习特征权重和重要性的机制。在Squeeze阶段,通过全局平均池化操作,将输入特征进行压缩,以捕捉全局的特征统计信息。在Excitation阶段,通过一对全连接层和激活函数,对压缩后的特征进行非线性映射和调整,以学习特征之间的权重关系。这样,SE模块能够自适应地选择和强调重要的特征,提高特征的判别能力。
? ? ? ? 想法:在压缩部分SE使用最简单的全局平均池化,可以试试更复杂的方法进行改进,以提高更多的性能。
2.3.2?卷积注意力模块(convolutional block attention module, CBAM)
论文:[1807.06521] CBAM: Convolutional Block Attention Module (arxiv.org)
主要内容:
-
给定中间特征图,BAM按顺序推导出沿通道和空间两个独立维度的注意力图,然后将注意图相乘到输入特征图进行自适应特征细化。
-
这个模块轻量级且通用,CBAM可以无缝集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端训练。
????????在原有通道注意力的基础上,衔接了一个空间注意力模块(Spatial Attention Modul, SAM)。SAM是基于通道进行全局平均池化以及全局最大池化操作,产生两个代表不同信息的特征图,合并后再通过一个感受野较大的7×7卷积进行特征融合,最后再通过Sigmoid操作来生成权重图叠加回原始的输入特征图,从而使得目标区域得以增强。
实验结论:
????????作者最终通过实验验证先通道后空间的方式比先空间后通道或者通道空间并行的方式效果更佳。
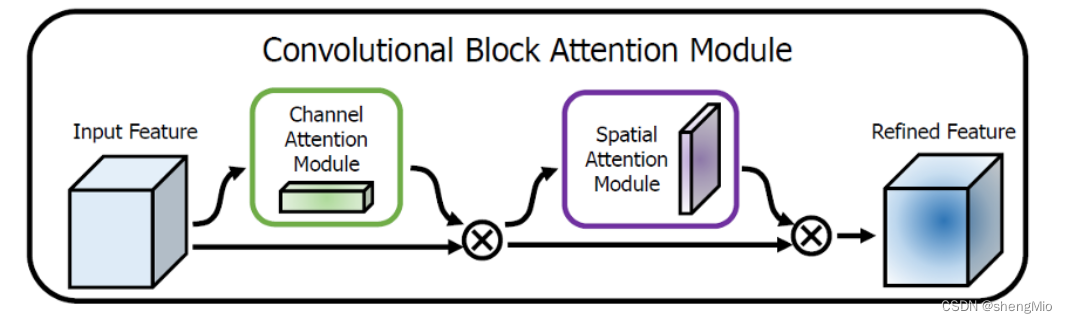
????????CBAM依次推断出一个1D的通道注意图Mc,尺寸为Cx1x1,和一个2D的空间注意力图Ms,尺寸为1xHxW。
其中 ? 表示元素乘法,F''是最终的细化输出。
?1.?通道注意力模块
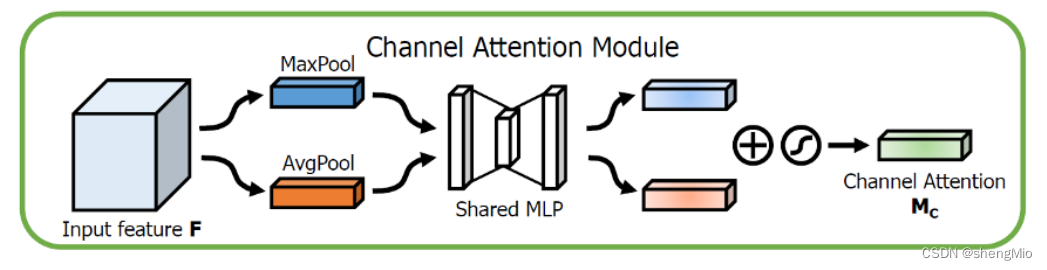
通道注意力聚焦在“什么”是有意义的输入图像,为了有效计算通道注意力,需要对输入特征图的空间维度进行压缩,对于空间信息的聚合,常用的方法是平均池化。但有人认为,最大池化收集了另一个重要线索——关于独特的物体特征,可以推断更细的通道上的注意力。因此,平均池化和最大池化的特征是同时使用的。
和
,分别表示平均池化特征和最大池化特征。
????????输入是一个 H×W×C 的特征 F,先分别进行一个空间的全局平均池化和最大池化得到两个 1×1×C 的通道描述。接着,再将它们分别送入一个共享网络,共享网络由一个多层感知器(MLP)组成,其中有一个隐含层。为减少参数开销,隐藏层的激活大小设为R/C=r×1×1,其中R为下降率。然后,再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc。最后,拿权重系数和原来的特征 F 相乘即可得到缩放后的新特征F'。
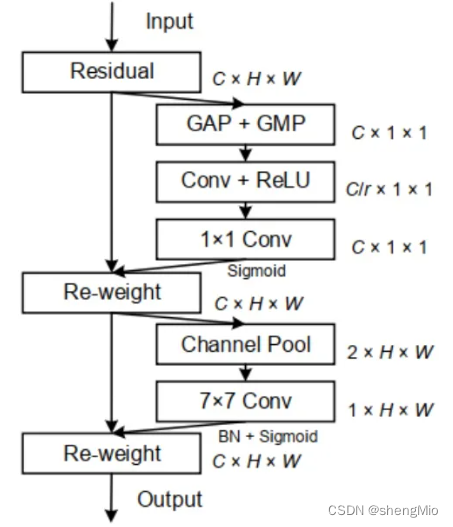
2. 空间注意力模块
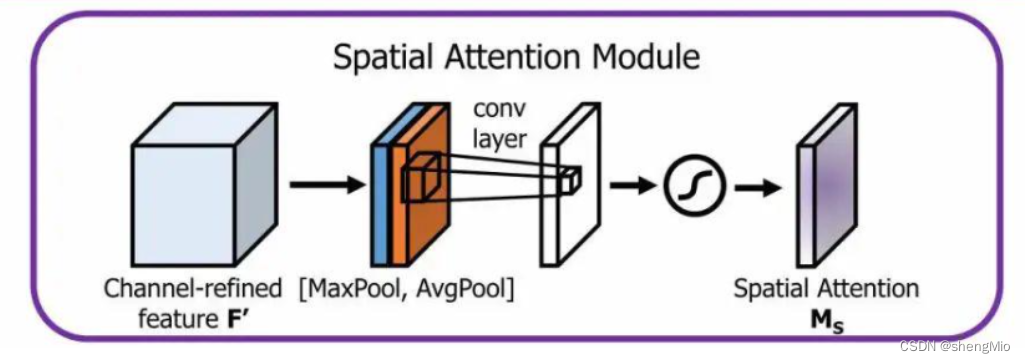
空间注意力聚焦在“哪里”是最具有信息量的部分,这是对通道注意力的补充。为了计算空间注意力,沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符。然后应用卷积层生成大小为R×H×W?的空间注意力图Ms(F),该空间注意图编码了需要关注或压制的位置。
具体来说,使用两个池化操作聚合成一个feature map的通道信息,生成两个2D图:?大小为1×H×W,
大小为1×H×W。σ表示sigmoid函数,f7×7表示一个滤波器大小为7×7的卷积运算。
输入H×W×C 的特征 F',先分别进行一个通道维度的平均池化和最大池化得到两个1×H×W的通道描述,并将这两个描述按照通道拼接在一起。然后,经过一个 7×7 的卷积层,激活函数为Sigmoid,得到权重系数 Ms。最后,拿权重系数和特征 F'相乘即可得到缩放后的新特征。
import torch.nn as nn
# 定义一个包含CBAM模块的卷积层
class CBAMBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
super(CBAMBlock, self).__init__()
self.in_channels = in_channels
self.reduction = reduction
# 通道注意力计算
self.channel_attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels, kernel_size=1, padding=0),
nn.Sigmoid()
)
# 空间注意力计算
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1, stride=1),
nn.BatchNorm2d(in_channels // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels // reduction, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_channels // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, 1, kernel_size=1, stride=1),
nn.Sigmoid()
)
def forward(self, x):
# 计算通道注意力系数
channel_att = self.channel_attention(x)
out = x * channel_att
# 计算空间注意力系数
spatial_att = self.spatial_attention(out)
out = out * spatial_att
return out
?2.3.3?坐标注意力(Coordinate Attention, CA)
论文:[2103.02907] Coordinate Attention for Efficient Mobile Network Design (arxiv.org)
????????通道注意力(例如,SE注意力)对于提升模型性能具有显著效果,但它们通常会忽略位置信息,而位置信息对于生成空间选择性attention maps是非常重要。因此在本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。?
????????CA通过精确的位置信息对通道关系和长程依赖进行编码,使网络能够以较小的计算成本关注大的重要区域,主要包括坐标信息嵌入和坐标注意力生成两个步骤。

????????与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,CA将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
1. Coordinate信息嵌入
????????全局池化方法通常用于通道注意编码空间信息的全局编码,但由于它将全局空间信息压缩到通道描述符中,导致难以保存位置信息。为了促使注意力模块能够捕捉具有精确位置信息的远程空间交互,本文按照以下公式分解了全局池化,转化为一对一维特征编码操作:
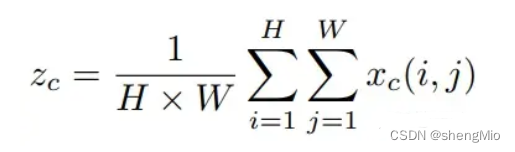
????????具体来说,给定输入,首先使用尺寸为(H,1)或(1,W)的pooling kernel分别沿着水平坐标和垂直坐标对每个通道进行编码。因此,高度为的第通道的输出可以表示为:
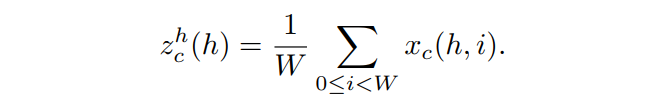
同样,宽度为的第通道的输出可以写成:
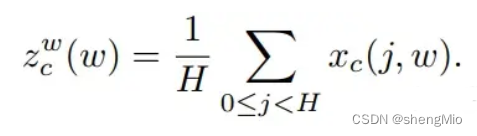
????????上述2种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这与在通道注意力方法中产生单一的特征向量的SE Block非常不同。这2种转换也允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
2. Coordinate Attention生成
????????本文方法可以通过上述的变换可以很好的获得全局感受野并编码精确的位置信息。为了利用由此产生的表征,作者提出了第2个转换,称为Coordinate Attention生成。这里作者的设计主要参考了以下3个标准:
- 首先,对于Mobile环境中的应用来说,新的转换应该尽可能地简单;
- 其次,它可以充分利用捕获到的位置信息,使感兴趣的区域能够被准确地捕获;
- 最后,它还应该能够有效地捕捉通道间的关系。
通过信息嵌入中的变换后,该部分将上面的变换进行concatenate操作,然后使用卷积变换函数对其进行变换操作:

式中为沿空间维数的concatenate操作,为非线性激活函数,为对空间信息在水平方向和垂直方向进行编码的中间特征映射。这里,是用来控制SE block大小的缩减率。然后沿着空间维数将分解为2个单独的张量和。利用另外2个卷积变换和分别将和变换为具有相同通道数的张量到输入,得到:
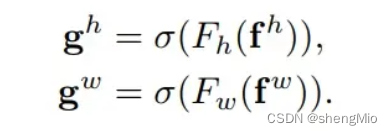
这里是sigmoid激活函数。为了降低模型的复杂性和计算开销,这里通常使用适当的缩减比(如32)来减少的通道数。然后对输出和进行扩展,分别作为attention weights。
最后,Coordinate Attention Block的输出可以写成:

2.4 论文?
- 标题:U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation????????U-MixFormer:具有混合注意力的类UNet变换器用于有效的语义分割
- 背景:全卷积网络(FCN)的引入普及了编码器-解码器结构,其中编码器提取高级语义,解码器将它们与空间细节相结合。但传统的CNNs很难捕捉到长期的上下文。这一限制促使人们对基于视觉变换器的分割方法产生了兴趣。
- 主要思想:作者提出了一种新的Transformer解码器U-MixFormer,它基于U-Net结构,用于高效的语义分割。除了传统的对跳跃连接的依赖之外,该方法通过利用编码器和解码器阶段之间的横向连接作为注意力模块的特征查询来区别于以前的转换器方法。此外,作者还创新地将来自不同编码器和解码器阶段的层次特征图混合,形成一个统一的表示形式,用于Key和Value,从而产生作者独特的_mix-attention_模块。
????????传统上,U-Net架构以其对称的基于CNN的编码器-解码器结构为特征,一直是语义分割的首选。这源于U-Net具有 有效捕捉和传播层次特征的特性。此外,它的横向连接起着重要作用,促进了编码器和解码器之间多级特征的流动。我们假设,利用U-Net架构的这些固有优势可以有效地细化特征,然后可以将其分层集成到转换器-解码器阶段。????????
? ? ? ? 论文提出了一种新型的UNet-like变换解码器U-MixFormer。U-MixFormer基于U-Net的基本原理,在其专用的混合注意力模块中自适应地将多阶段特征作为关键和值进行集成。该模块确保了特征的逐渐传播,并在解码器阶段连续地重新混合它们,有效地管理这些阶段之间的依赖关系,以捕获上下文并细化边界。这可以像传统的细胞神经网络一样强调层次特征表示,并增强Transformers的全局上下文理解能力。据我们所知,这是第一项将U-Net的固有优势与视觉转换器的变革能力协同起来的工作,特别是通过一个新颖的注意力模块,有效地协调语义分割的查询、键和值。
2.4.1 主要贡献总结如下:
1. 基于U-Net的新型解码器结构
????????基于U-Net的新型解码器架构我们提出了一种新的强大的转换器解码器架构,该架构以U-Net为动力,用于高效的语义分割。利用U-Net在捕获和传播分层特征方面的熟练程度,我们的设计独特地使用Transformer编码器的横向连接作为查询特征。这种方法确保了高级语义和低级结构的和谐融合。
2. 优化特征合成,增强上下文理解
????????为了提高我们的类UNet转换器架构的效率,我们将多个编码器和解码器输出作为键和值的集成特征进行混合和更新,从而产生了我们提出的混合注意力机制。这种方法不仅为每个解码器阶段提供了丰富的特征表示,而且还增强了上下文理解。
3. 兼容不同的编码器
????????我们演示了U-MixFormer与基于变压器(MiT和LVT)和基于CNN (MSCAN)编码器的现有流行编码器的兼容性。
4. 基准测试经验
????????如图1所示,UMixFormer在计算成本和语义分割方法的准确性方面达到了最先进的水平。它始终优于轻量级、中等重量甚至重型编码器。ADE20K和Cityscapes数据集证明了这一优势,在具有挑战性的Cityscape-C数据集上表现显著。
2.4.2 相关工作
编码器架构
SETR是第一个采用ViT作为语义分割编码器的架构。因为ViT只将输入图像划分为块,所以SETR产生单比例编码器特征。PVT和Swin-Transformer在编码器级之间重复地将特征图分组为新的非重叠补丁,从而分层生成多尺度编码器特征。这两种方法还通过减少键和值的空间维度(PVT)或将具有移位窗口的补丁分组(Swin-Transformer)来提高自注意模块的效率。SegFormer重用PVT的效率策略,同时去除位置编码并将特征图嵌入到重叠的补丁中。与前面提到的方法相反,SegNeXt和LVT的编码器采用了卷积注意力机制。
解码器架构
DETR是第一种部署用于语义分割的Transformer解码器的方法。随后的工作(Strudel等人2021;Cheng、Schwing和Kirillov 2021;Cheg等人2022)适应了DETR,但也依赖于对象可学习查询,这在计算上是昂贵的,尤其是当与多尺度编码器特征相结合时。相比之下,FeedFormer直接利用编码器阶段的特征作为特征查询,从而提高了效率。FeedFormer解码高级编码器特征(用作查询的特征)和最低级别编码器特征(用于键和值的特征)。然而,这种设置单独处理特征图,而没有特征图在解码器级之间的增量传播,从而错过了进行更多增量细化以改进对象边界检测的机会。此外,其他最近的基于MLP或CNN的解码器(Xie等人,2021;郭等人,2022)也缺乏解码器特征的增量传播。
UNet-like Transformer
人们已经尝试将UNet架构从基于卷积神经网络(CNN)的框架转变为基于Transformer的框架。TransUNet是首次成功将Transformer引入医学图像分割的方法,它使用ViT与他们的CNN编码器相结合。Swin-UNet,这是第一个完全基于Transformer的UNet类似架构。该设计具有用于编码器和解码器的重型Swin Transformer阶段,保留了它们之间的横向连接作为跳接连接。与Swin-UNet相比,我们采用轻量级解码器阶段,使其适合更广泛的下游任务。此外,我们将横向连接解释为 Query 特征而不是跳接连接,并融入了一种独特的注意力机制。
?
2.4.3 模型结构
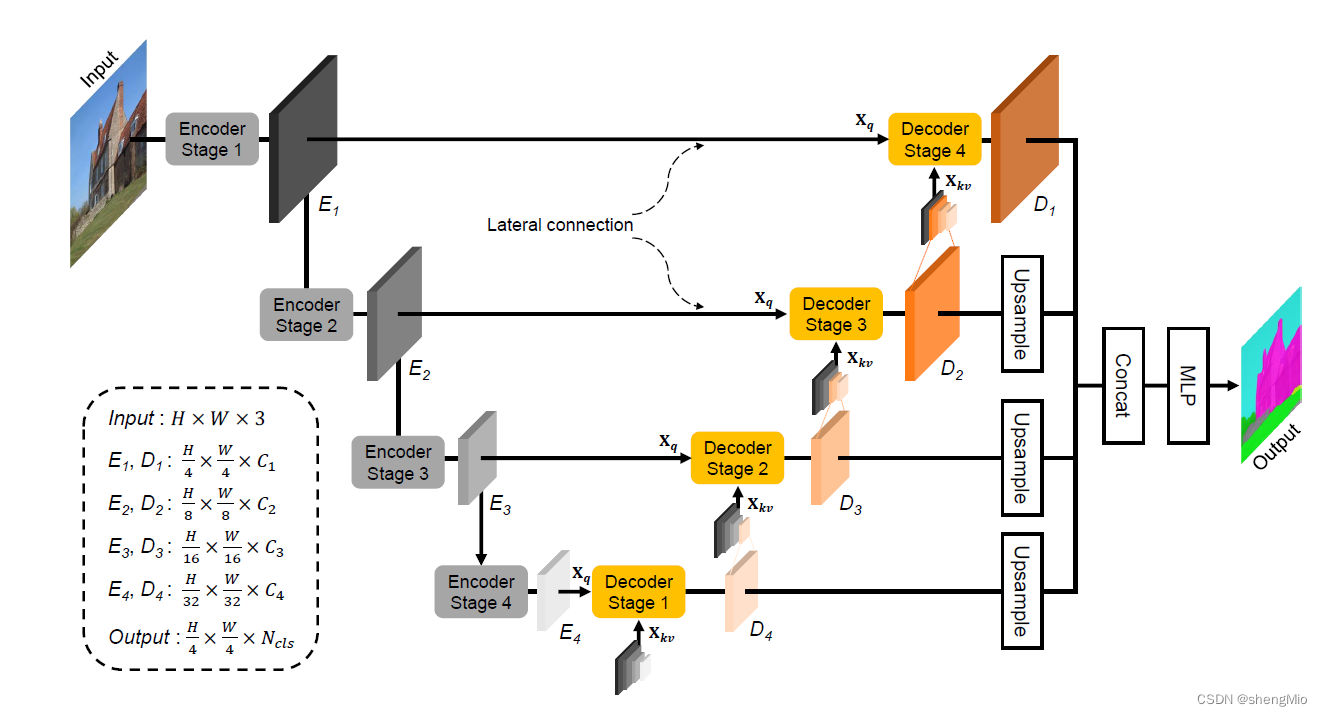
图2:U-MixFormer架构:编码器(左)从输入图像中提取多分辨率特征图。U-MixFormer解码器(右)通过使用我们的混合注意力机制将横向编码器输出作为Xq与先前解码器级输出融合到Xkv中。最后,来自所有解码器级的特征图被级联,并且MLP预测输出。?
????????一般来说,我们的解码器由多个阶段i∈{1,…,N},因为有编码器阶段。为了清晰起见,图2提供了该体系结构的可视化概述,并举例说明了一个四阶段(N = 4)分层编码器,如MiT、LVT或MSCAN。
????????首先,编码器处理输入H×W×3(channel)的图像。四个阶段i∈{1,…, 4}生成分层、多分辨率特征Ei
????????其次,我们的解码器阶段依次生成精细的特征D4-i+1通过执行混合注意,其中的特征用于查询Xq i 等于各自的横向编码器特征图。键和值的特性Xkv i 由编码器和解码器阶段混合给出。值得注意的是,我们的解码器反映了编码器级输出的尺寸。
????????第三,使用双线性插值对解码器特征进行上采样,以匹配D1的高度和宽度。
????????最后,对拼接后的特征进行MLP处理,以H/4 ×W/4 × 3预测分割图。
2.4.4 Mix-Attention混合注意力
Transformer 块中使用的注意力模块计算查询Q,键K和值V的缩放点积注意力,如下所示:

其中dk为键的嵌入维数,Q、K、V由所选特征的线性投影得到。我们方法的核心是选择要投射到键和值上的特征,这导致了我们提出的混合注意机制。传统的自注意力、交叉注意和新型混合注意之间的比较从左到右如图3所示。

2.4.5 总结
????????在本文中,我们提出了U-MixFormer,建立在为语义分割而设计的U-Net结构之上。UMixFormer开始与最上下文编码器的特征图,并逐步纳入更精细的细节,建立在U-Net的能力,以捕获和传播分层特征。我们的混合注意设计强调合并特征图的组件,将它们与越来越细粒度的横向编码器特征对齐。这确保了高级上下文信息与复杂的低级细节的和谐融合,这是精确分割的关键。我们在流行的基准数据集上展示了我们的U-MixFormer在不同编码器上的优势。
展望:
U-Net的固有结构,它需要通过横向(或残余)连接来保存信息。虽然这些连接对于捕获分层特征至关重要,但在推理阶段会带来开销。为了解决这一限制,我们的目标是在未来的工作中探索模型压缩技术,如修剪和知识蒸馏。这些方法有望在保留UMixFormer的准确性优势的同时潜在地提高推理速度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 说说产品经理能力模型
- 【教学类-06-16】20231213 (按比例抽题+乱序or先加再减后乘)X-Y之间“加法减法乘法+-×混合题”
- 在简历上写了“精通”后,拥有工作经验的我被面试官问到窒息
- weston 3: wayland通信总结(1)
- 【网络安全】upload靶场pass1-10思路
- 2024年四川省众创空间和科技企业孵化器申报条件及各区县奖励补助
- JVM 内存布局
- 【MAUI】完整的登录界面~源码
- 「HarmonyOS」验证码多TextInput输入框焦点自动跳转问题
- C语言学习第二十八天(关于单链表操作的一些OJ题目)