Pix2Pix理论与实战
?本文为🔗365天深度学习训练营?中的学习记录博客
?原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习框架Pytorch 1.8.0+cu111
一、引入
? 在之前的学习中,我们知道GAN网络可用作图像的生成,但GAN的一个问题是它无法对生成模型生成的数据进行控制,为了解决这个问题,我们学习了条件GAN,它 提出了将在生成模型和判别模型中都加入条件信息来引导模型的训练,实现了生成内容的可控。
? 我们今天所要学习的?Pix2Pix是一个以CGAN为基础,用于图像翻译的通用框架,旨在将一个图像域中的图像转换成另一个图像域中的图像,它实现了模型结构和损失函数的通用化,并在诸多图像翻译数据集上取得了令人瞩目的效果。
二、背景知识
2.1、图像翻译
图像内容:是指图像中呈现出来的视觉信息或图案,它可以包括物体、场景、人物等。图像内容是通过像素的排列和颜色等信息来呈现的,是图像的可视化表达。
图像域:是指图像在空间中的范围或维度。在二维图像中,图像域通常由横轴和纵轴组成,表示图像的宽度和高度。图像域的概念在图像处理和计算机视觉领域中经常被使用,用于描述图像的空间特征和位置信息。
图像翻译:是将一种语言的图像内容翻译成另一种语言的过程。这可以涉及到将图像中的文本、标志、物体等翻译成目标语言。图像翻译通常使用计算机视觉和自然语言处理技术,结合图像识别和机器翻译的方法来实现。
2.2、CGAN
CGAN引入了条件的概念。在普通的GAN中,生成器是无条件地生成数据,而在CGAN中,生成器的输出受到条件信息的影响。这个条件信息可以是类别标签、文本描述等,使得生成器能够按照给定条件生成相应的数据。
具体来说,CGAN的训练过程中,生成器的输入不仅包括一个随机噪声向量,还包括一个条件向量,用于指导生成过程。判别器则需要判断输入的数据是真实数据还是生成器生成的数据,并考虑条件信息。通过这种方式,CGAN可以更有针对性地生成符合特定条件的数据,例如生成特定类别的图像。
CGAN的应用包括图像生成、图像转换、风格迁移等领域。通过引入条件信息,CGAN使得生成模型更具有控制性,能够更灵活地生成符合用户需求的数据。
2.3、U-Net
U-Net是一种用于图像分割任务的卷积神经网络架构,由医学图像分割领域的研究者提出,其结构特点使得它在分割任务中表现出色。U-Net的名字来源于其网络结构的形状,其整体形状类似字母 "U"。
以下是U-Net网络的主要特点和组成部分:
-
编码器-解码器结构: U-Net采用了编码器-解码器的结构。编码器部分用于捕获图像的上下文信息,通过卷积和池化操作逐渐减小空间分辨率。解码器部分则通过上采样和反卷积操作将编码器提取的特征图还原到原始图像的分辨率,以保留更多的空间信息。
-
跳跃连接(Skip Connections): U-Net引入了跳跃连接,将编码器的某一层的特征图与解码器对应层的特征图相连接。这种结构有助于传递更多的局部信息,帮助解码器更好地还原细节。
-
U形结构: U-Net的整体结构形状呈现出“U”字形,由一个下采样路径和一个上采样路径组成。这样的结构使得网络能够同时关注图像的全局信息和局部细节,适用于图像分割任务。
-
最后的卷积层: U-Net的最后一层是一个卷积层,用于生成最终的分割结果。这一层通常采用 1x1 的卷积核,生成与输入图像相同分辨率的分割图。
-
应用领域: U-Net最初设计用于医学图像分割,如肺部和细胞图像的分割。然而,由于其优越的性能,U-Net被广泛应用于其他图像分割任务,包括道路分割、人体分割等。
总的来说,U-Net网络通过其独特的结构,特别是编码器-解码器结构和跳跃连接,使其在图像分割任务中表现出色,成为一个重要的图像分割模型。
三、Pix2Pix解析

? 生成器G用到的是Unet结构,输入的轮廓图编码再解码成真是图片,判别器D用到的是作者自己提出来的条件判别器PatchGAN,判别器D的作用是在轮廓图
的条件下,对于生成的图片
判断为假,对于真实图像判断为真。?
3.1、损失函数
根据CGAN可以写出损失函数:
?生成器的作用是迷惑鉴别器,产生一个跟真图像相似的图像。Pix2Pix使用L1 loss生成高质量图像。
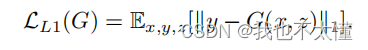
最终的目标函数为: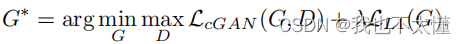 ?
?
3.2、模型结构?
?生成器:
Pix2Pix生成器的结构是基于U-Net的编码器-解码器结构,并在此基础上进行了一些改进。下面是Pix2Pix生成器的主要组成部分和结构特点:
-
编码器(Encoder): Pix2Pix生成器的编码器部分负责捕获输入图像的上下文信息。通常采用卷积层和池化层,逐渐减小输入图像的空间分辨率,同时提取图像的特征。
-
U-Net结构: 生成器的整体结构采用了U-Net结构,包括编码器和解码器。U-Net结构的特点是具有跳跃连接,将编码器的某一层的特征图与解码器对应层的特征图相连接。这有助于保留更多的局部信息,帮助生成器还原细节。
-
解码器(Decoder): 解码器部分通过上采样和反卷积操作将编码器提取的特征图还原到原始图像的分辨率。这一部分的目标是逐渐生成与目标图像相似的输出。
-
跳跃连接: 跳跃连接是U-Net结构的一个关键特点,在解码器的每一层都连接了相应编码器层的特征图。这样的连接有助于传递更多的局部信息,改善生成图像的质量。
-
生成层: 生成器的最后一层是一个卷积层,输出生成的目标图像。在Pix2Pix中,通常使用tanh激活函数来确保输出的像素值在[-1, 1]范围内。
判别器:
传统GAN蚕蛹整张图作为判别器的输入导致生成的图像普遍比较模糊。Pix2Pix将输入图像分块,然后将这些图像块依次传递给判别器。这种方法被命名为PatchGAN。
四、代码运行
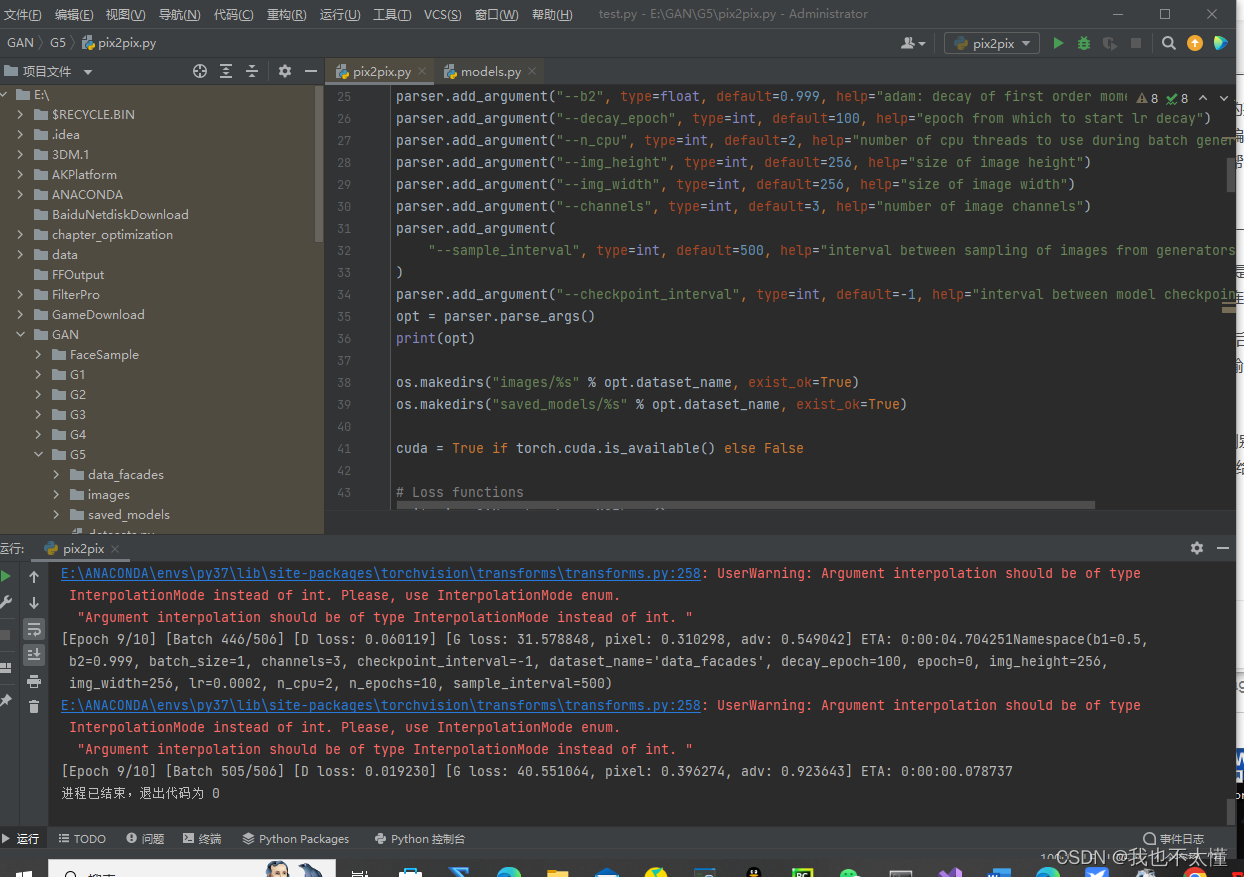
 ?
?
?Pix2Pix的缺点及总结:
? 作者在论文中也承认,使用这样的结构其实学到的是到
的一对一映射。也就说,pix2pix就是对ground truth的重建:输入轮廓图→经过Unet编码解码成对应的向量→解码成真实图。这种一对一映射的应用范围十分有限,当我们输入的数据与训练集中的数据差距较大时,生成的结果很可能就没有意义,这就要求我们的数据集中要尽量涵盖各种类型。
? ?Pix2Pix通过生成对抗网络(GAN)进行图像到图像的转换。它通过对抗训练,结合条件生成,以学习输入图像和目标输出图像之间的映射关系。生成器的目标是生成逼真的目标图像,而判别器的任务是区分真实目标图像和生成器生成的伪造图像。Pix2Pix借用了U-Net结构,包括编码器和解码器,以及跳跃连接,以便更好地捕获局部信息。这种方法在图像生成和转换任务中取得了成功,广泛应用于图像翻译、语义分割到真实图像等领域。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 成为一名成功的互联网产品经理需要掌握哪些技能?
- 【金融数据分析】计算2023年沪深300行业涨跌幅
- 秒杀相关问题及答案(2024)
- 自然语言处理(NLP)
- zblog主题_zblog主题模板多功能门户百科资讯网站自适应模板
- 【7-zip密码】7-Zip如何取消文件加密的密码
- 【Golang】IEEE754二进制01字符串转为Float
- docker 使用
- 2024云服务器租用推荐,全网TOP10等你选!
- 2023 安洵杯-PWN-【seccomp】