实验算法设计
发布时间:2024年01月20日

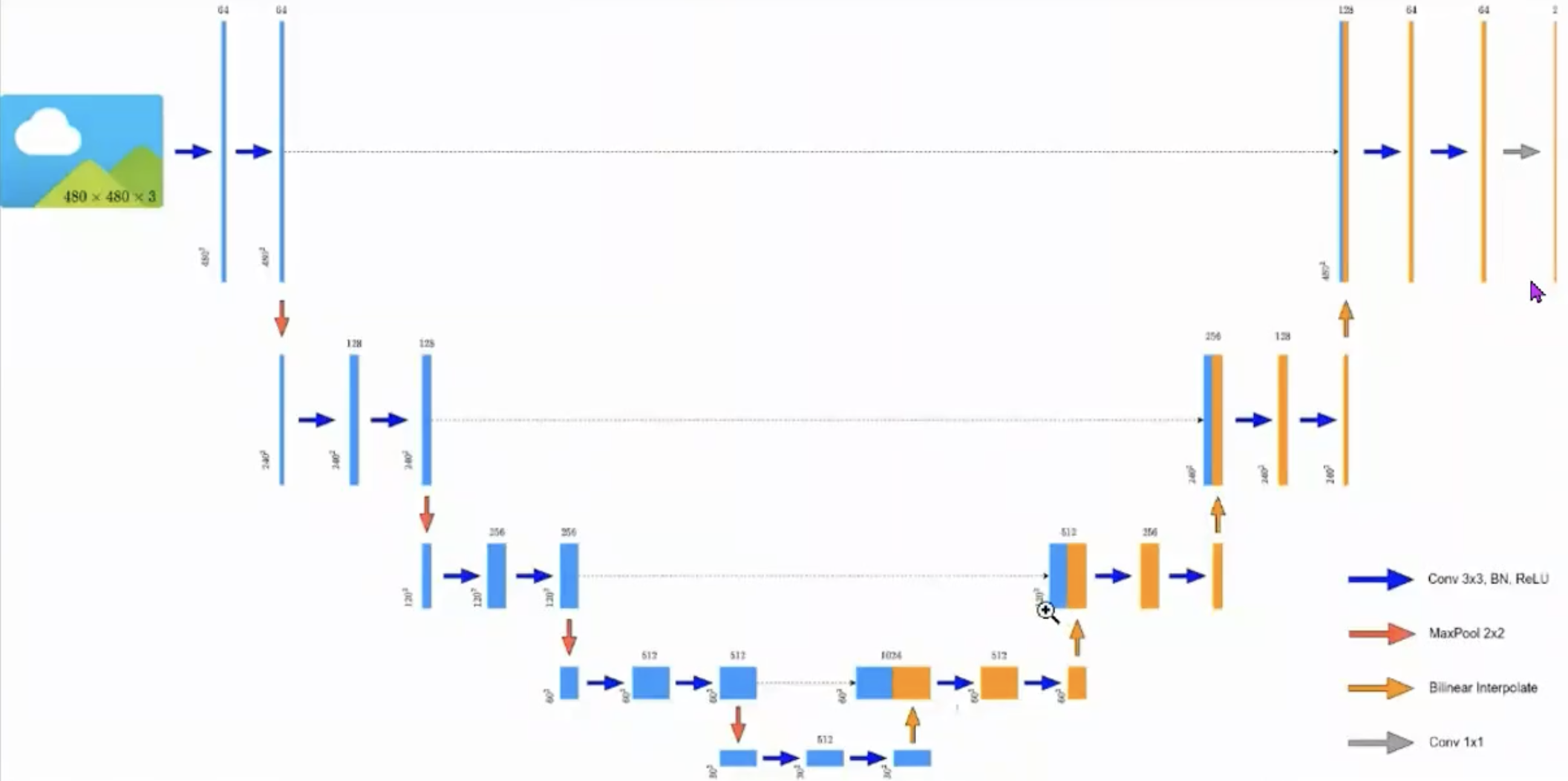
Unet

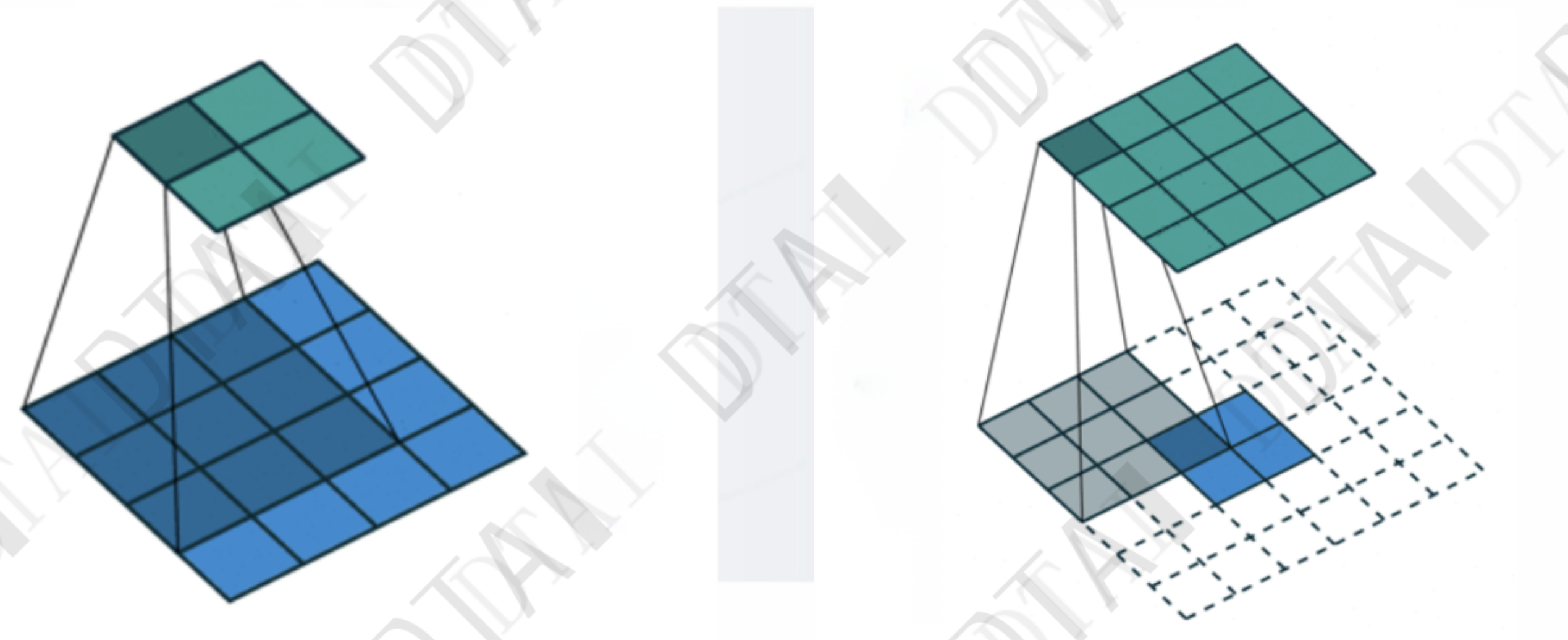

- 可以用双线性差值替换,效果差不多,参数更少。
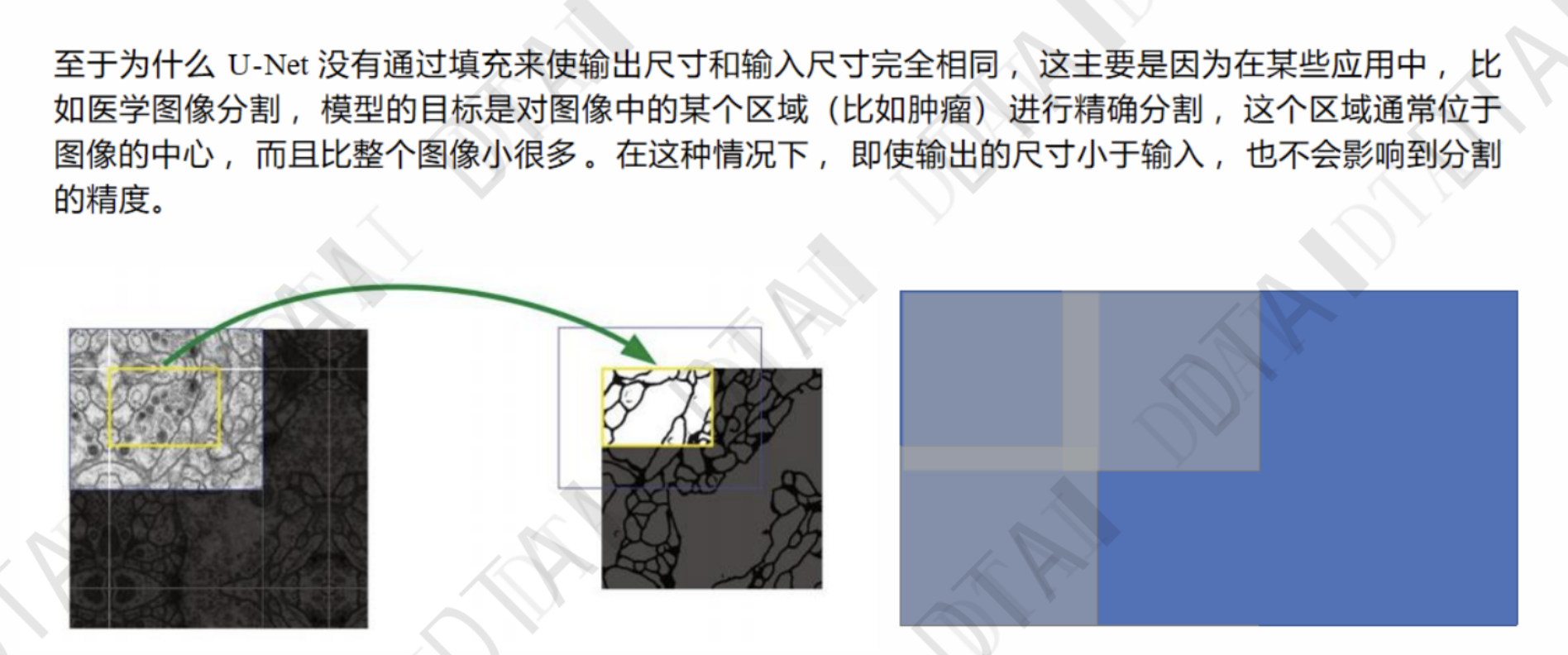
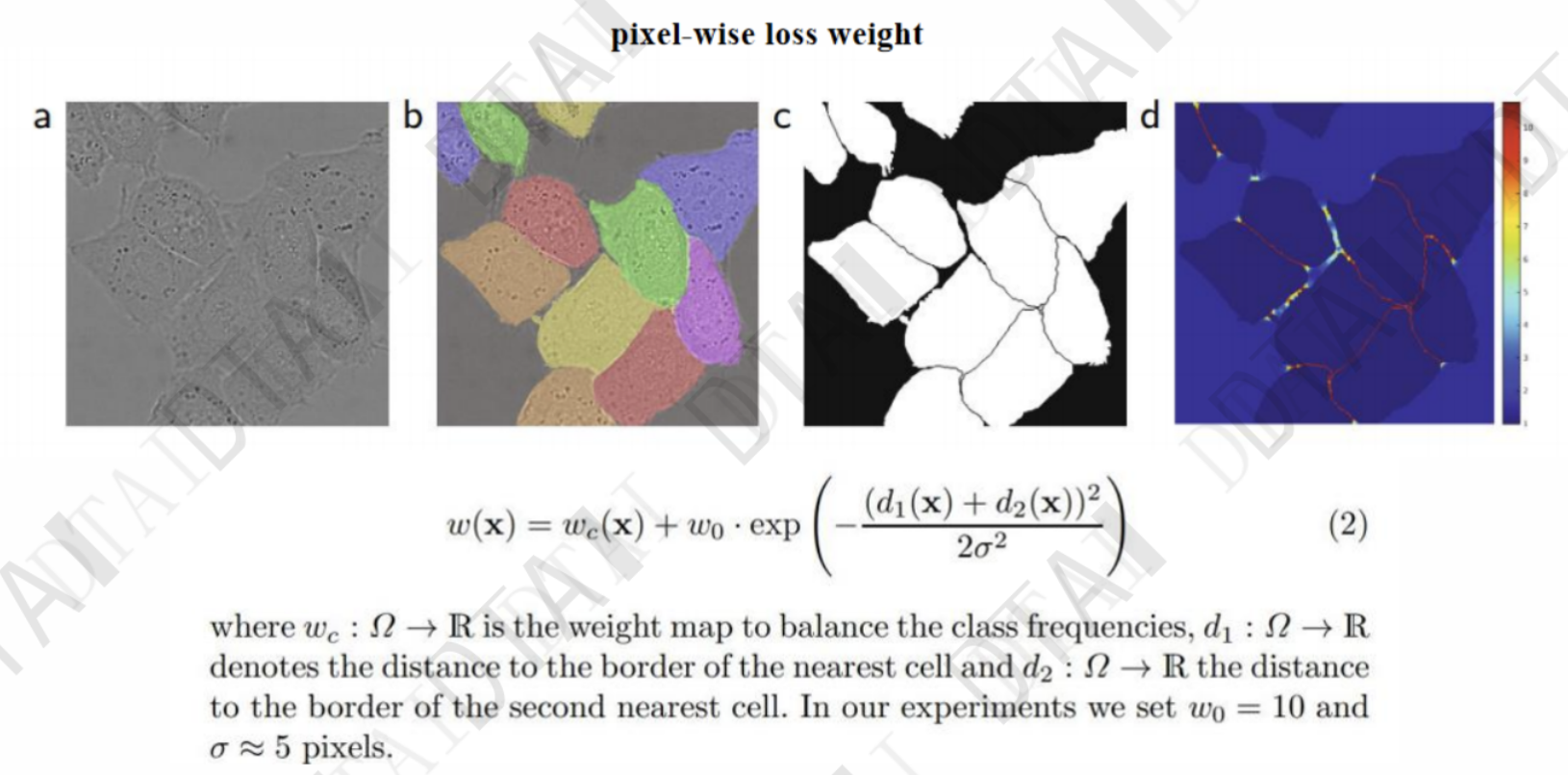
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels= None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3,padding=1,bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3,padding=1,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super(Down,self).__init__(
nn.MaxPool2d(2,stride=2),
DoubleConv(in_channels, out_channels)
)
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor)-> torch.Tensor:
x1 = self.up(x1)
diff_x = x2.size()[2] - x1.size()[2]
diff_y = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1),
)
class Unet(nn.Module):
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64
):
super(Unet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x)
return {"out":logits}
数据集
-
test测试集
- 1st_manual标签
- 2nd_manual更加细致的标签
- images原图
- mask掩码,感兴趣的区域
-
training训练集
- 1st_manual
- images
- mask
-
数据处理部分
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
class DriveDataset(Dataset):
def __init__(self, root: str, train: bool, transforms=None):
super(DriveDataset, self).__init__()
self.flag = "training" if train else "test"
data_root = os.path.join(root, "DRIVE", self.flag)
assert os.path.exists(data_root), f"path '{data_root}' does not exist."
self.transforms = transforms
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
for i in self.manual:
if not os.path.exists(i):
raise FileNotFoundError(f"file {i} does not exist.")
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
for i in self.roi_mask:
if not os.path.exists(i):
raise FileNotFoundError(f"file {i} does not exist.")
def __getitem__(self, idx):
img = Image.open(self.img_list[idx]).convert("RGB")
manual = Image.open(self.manual[idx]).convert("L")
manual = np.array(manual) / 255
roi_mask = Image.open(self.roi_mask[idx]).convert("L")
roi_mask = 255 - np.array(roi_mask)
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
mask = Image.fromarray(mask)
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
def __len__(self):
return len(self.img_list)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = DriveDataset.cat_list(images, fill_value=0)
batched_targets = DriveDataset.cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
@staticmethod
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., : img.shape[-2], : img.shape[-1]].copy_(img)
return batched_imgs
- 代码文件不全,参考一下就行
transformer
整体网络架构
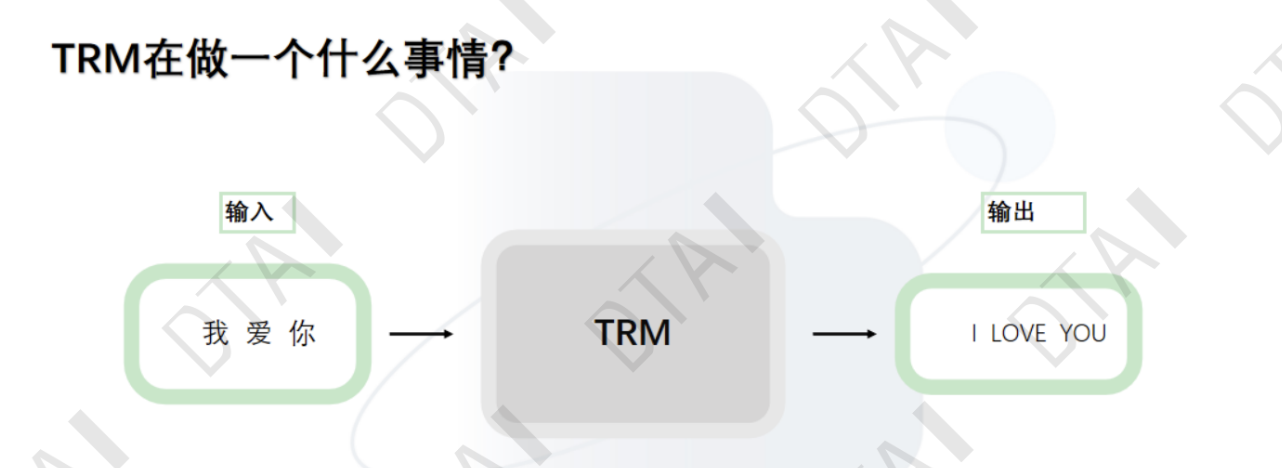

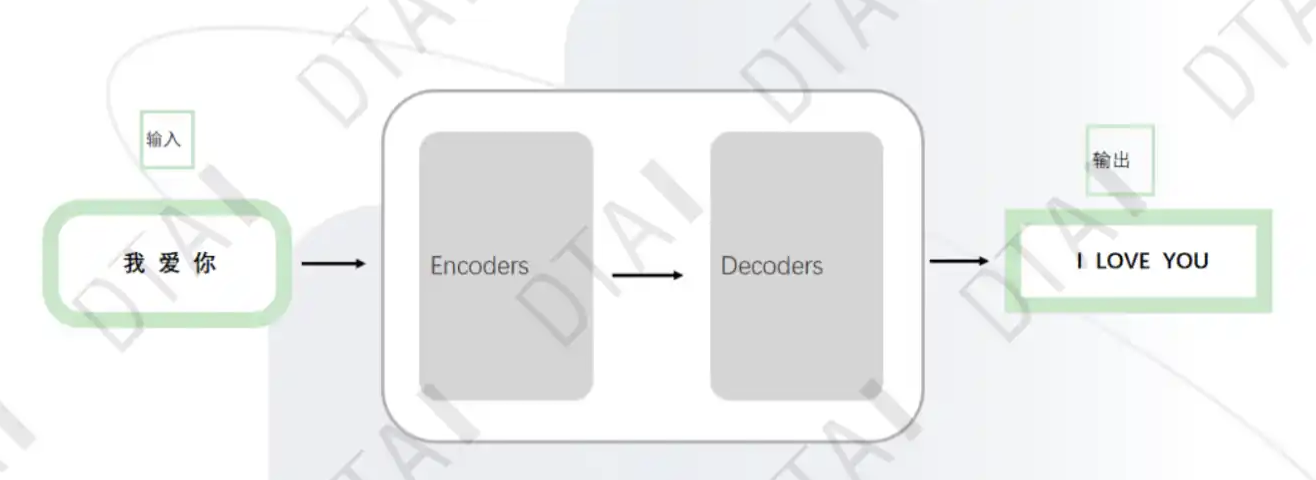
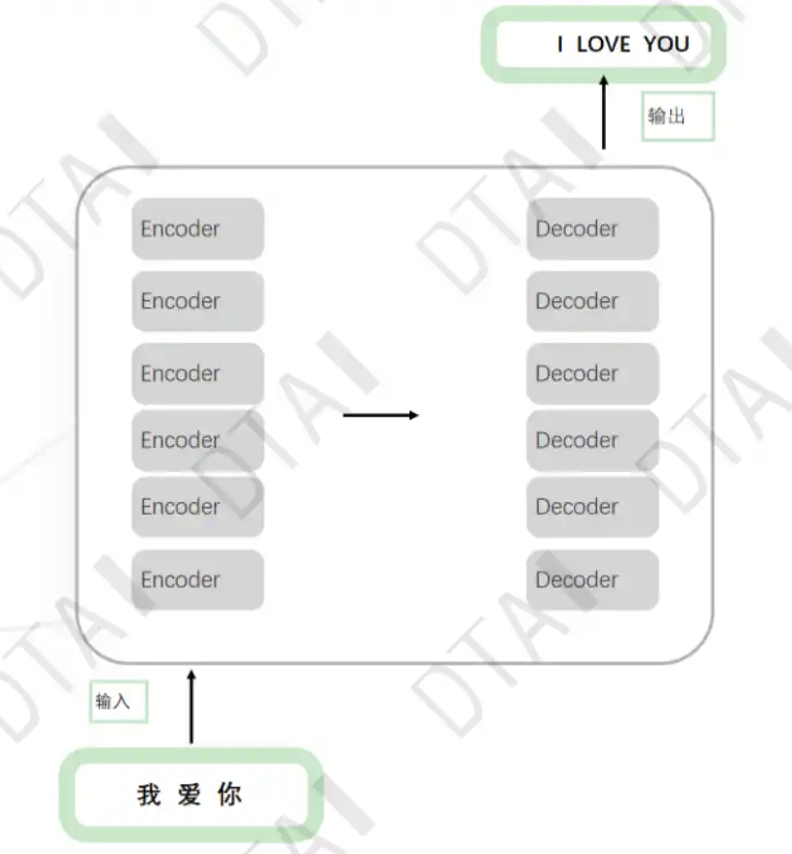
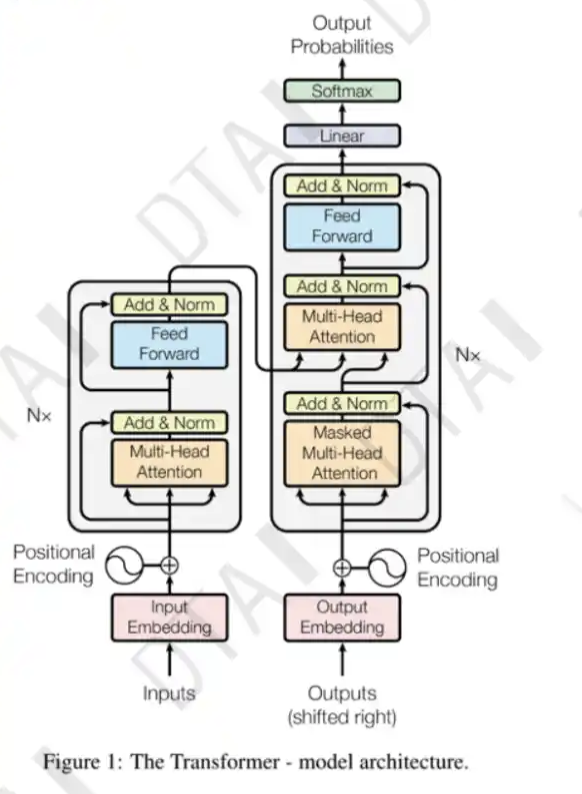
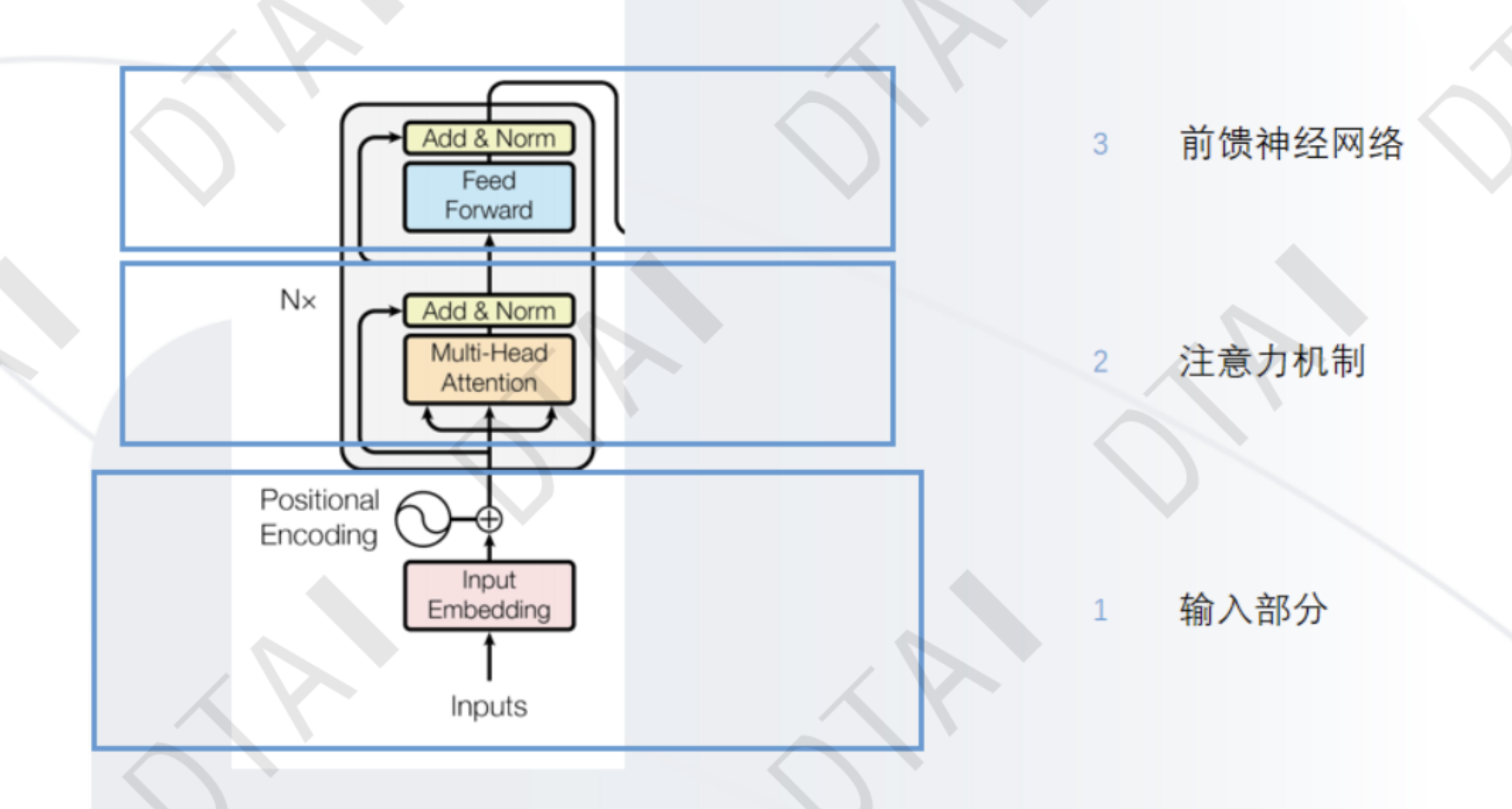
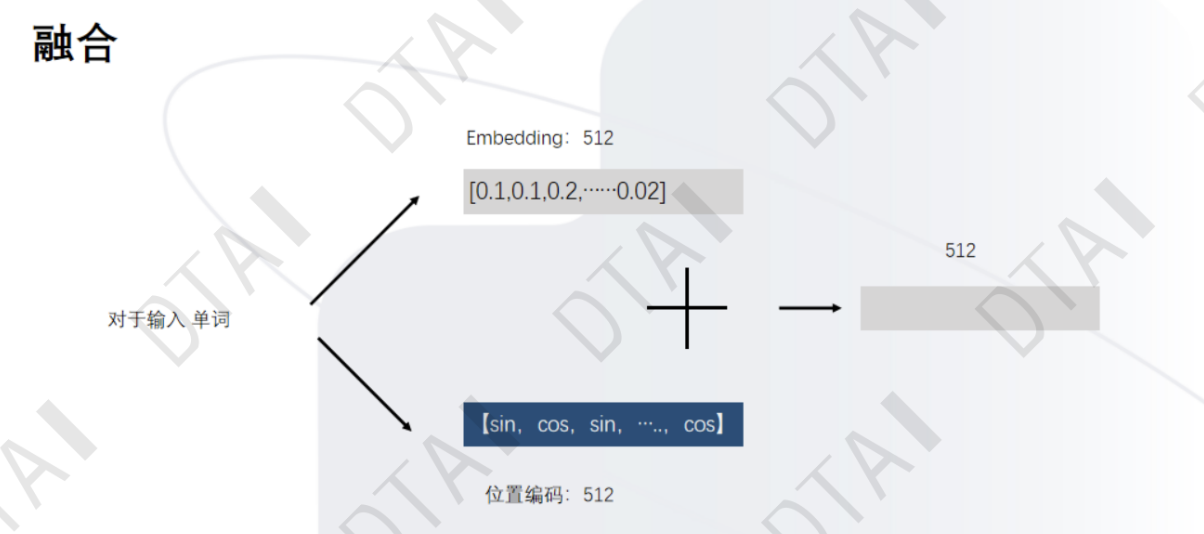
- Embedding
位置编码
- 它能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。
- 它的值应该是有界的;它必须是确定性的

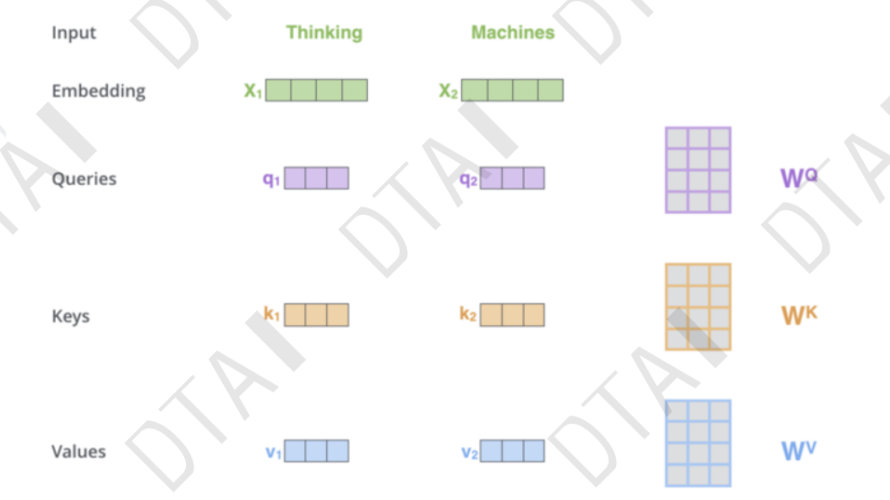
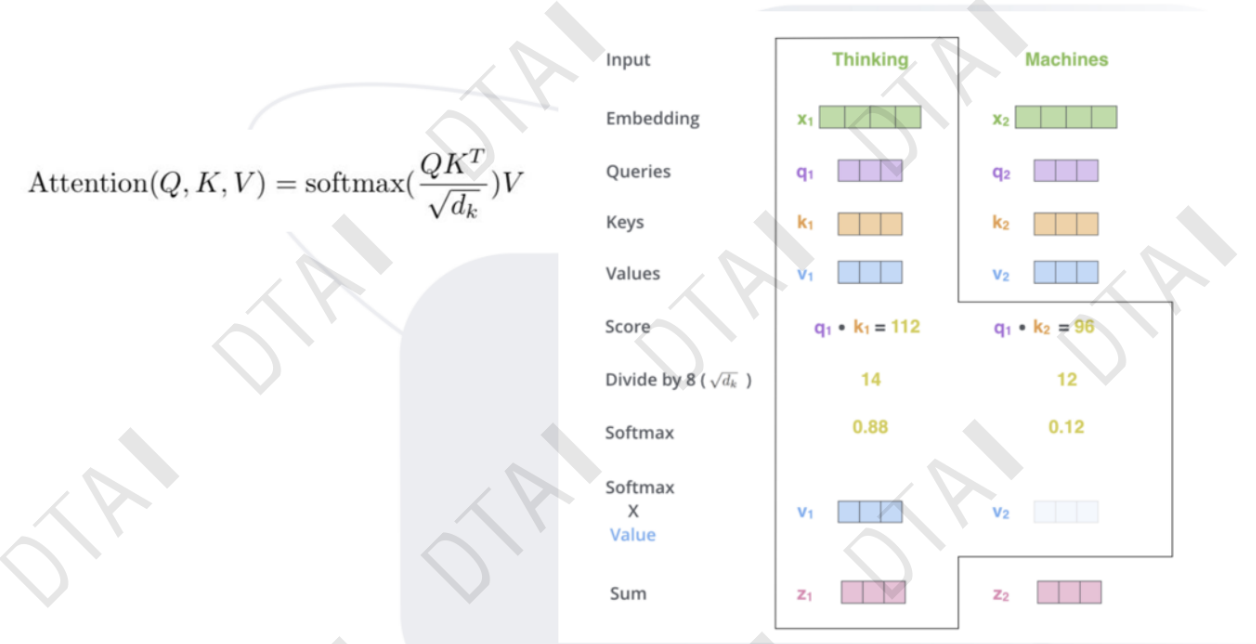
注意力机制:从众多信息中选出对当前任务目标更加关键的信息
- 基本的注意力机制
- 在TRM中怎么操作

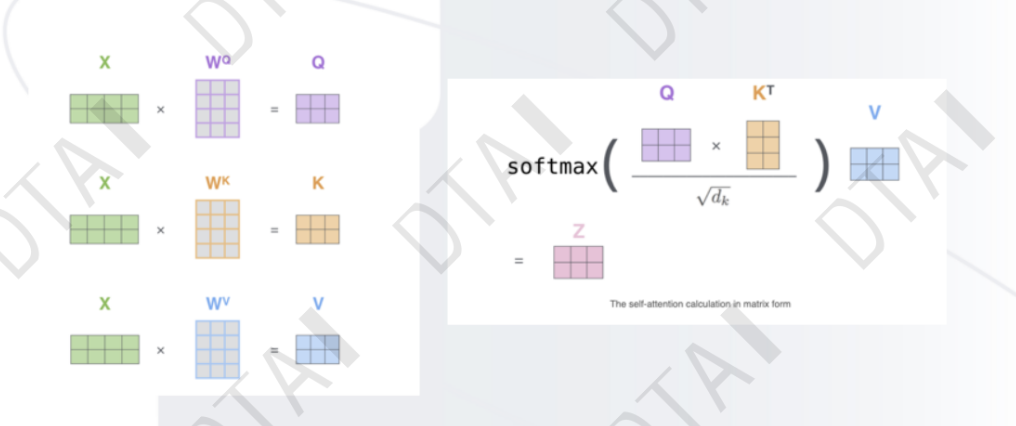
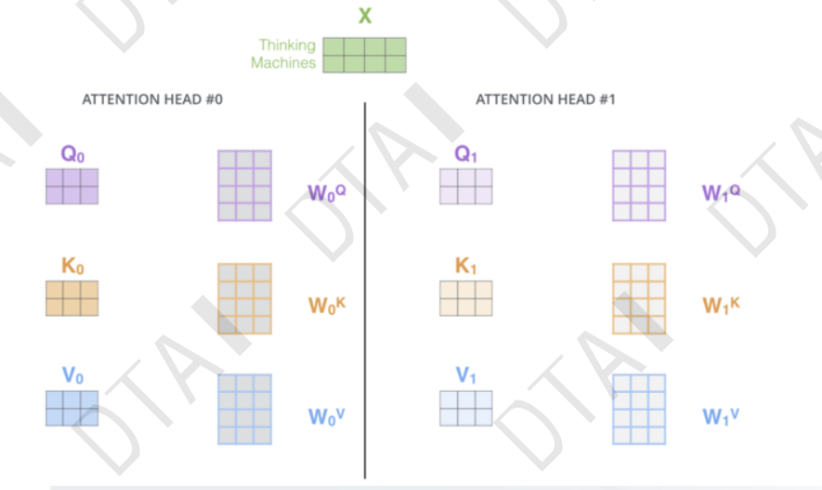
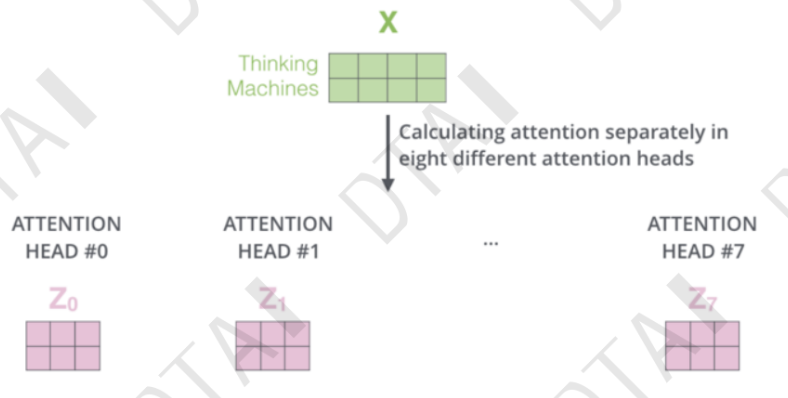
前馈神经网络
- 前馈网络(feed-forward network)是一种常见的神经网络结构,由一个或多个线性变换和非线性激活函数组成。它的输入是一个词向量,经过一系列线性变换和激活函数处理之后,输出另一个词向量。
- 前面都是线性变化(矩阵乘法),表达能力不够
- 更加深入的特征提取
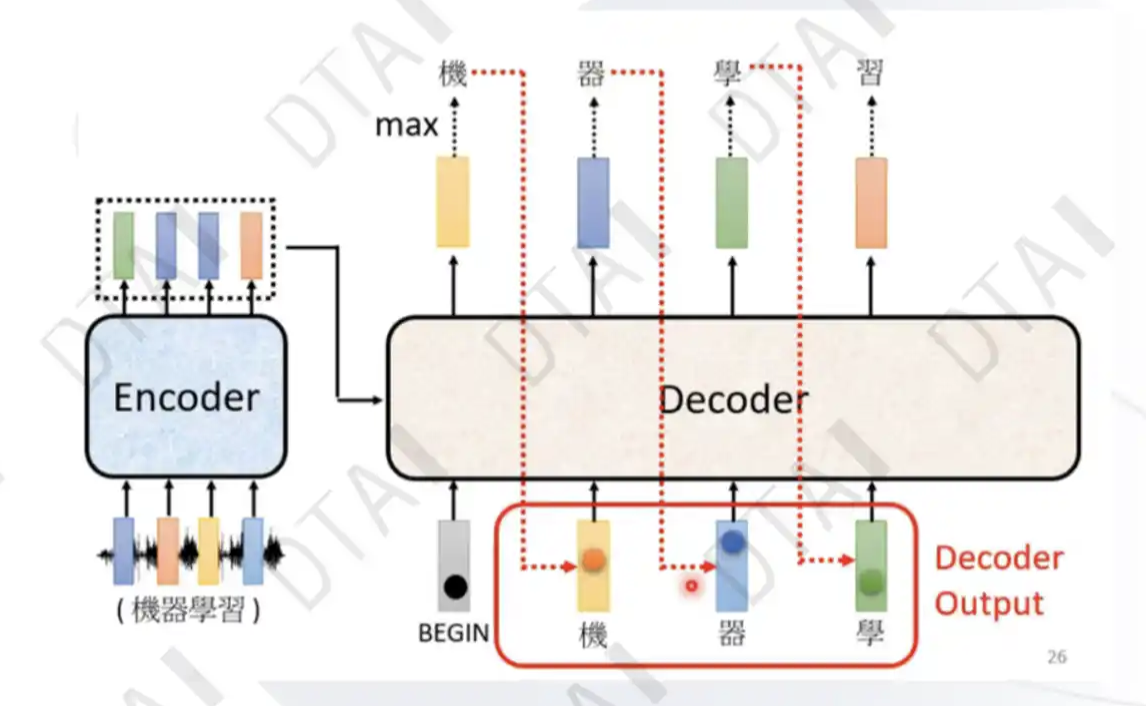
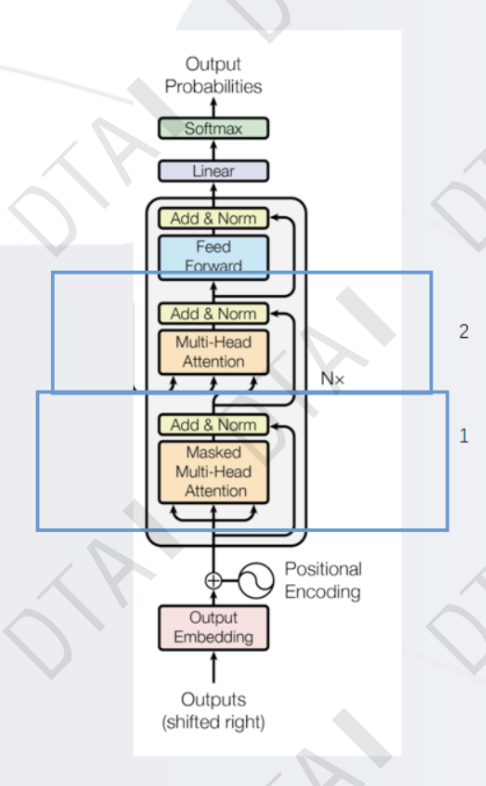
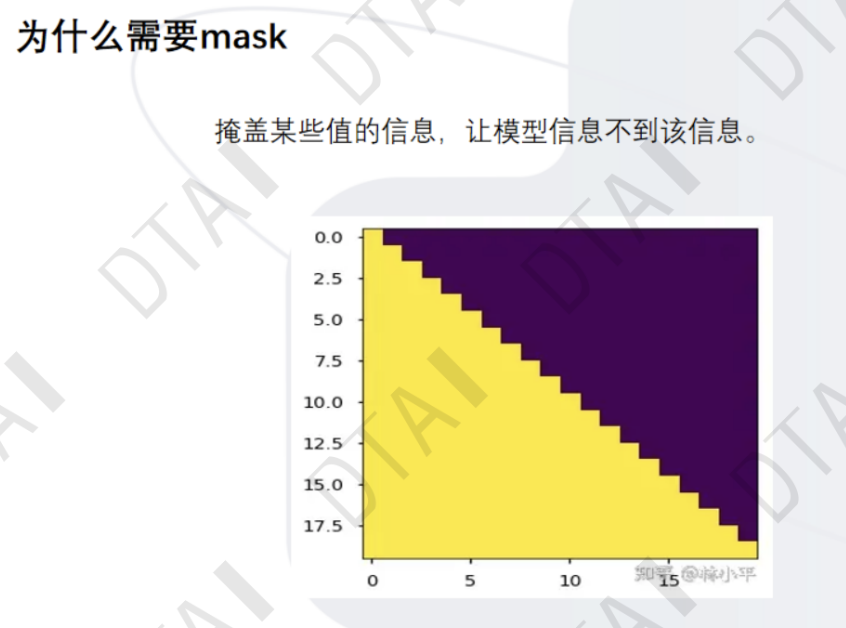

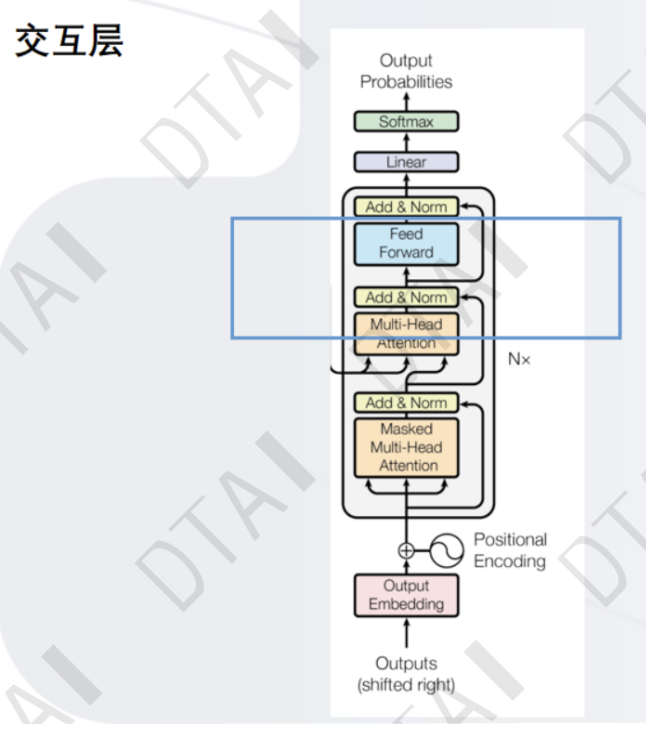
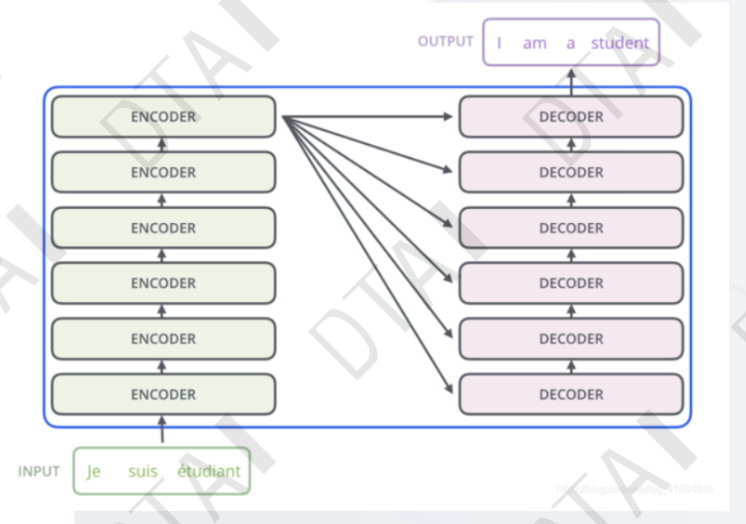
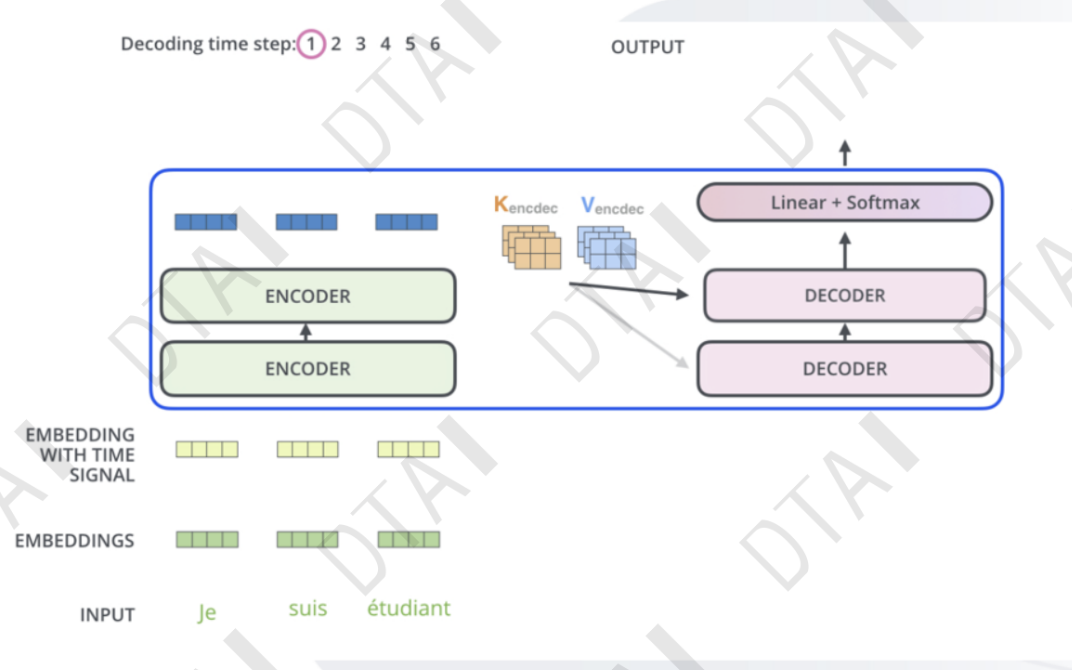
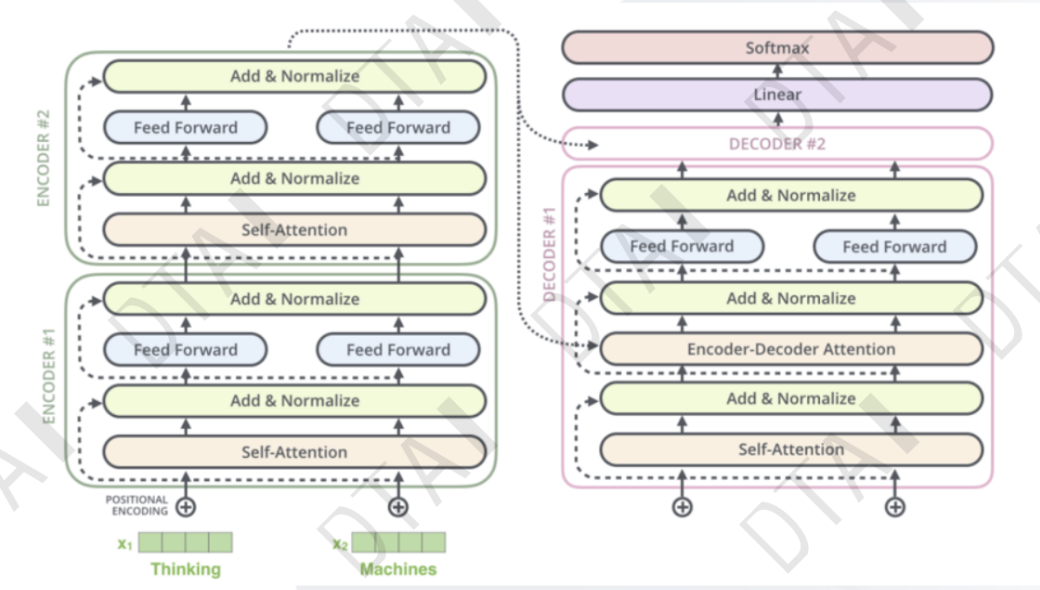
编码器:将输入文本序列编码为一系列隐藏表示,通常使用多层自注意力机制和前馈神经网络。
解码器:接收编码器的输出和部分已生成的序列,使用自注意力机制和注意力机制来生成下一个词或字符。
文章来源:https://blog.csdn.net/qq_61735602/article/details/135702675
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!