ZooKeeper
1、ZooKeeper是什么
zooKeeper致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务。
1、高性能
zooKeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,尤其适用于以读为主的应用场景。
2、高可用
zooKeeper一般以集群的方式对外提供服务,一般3 ~ 5台机器就可以组成一个可用的zookeeper集群了,每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都相互保持着通信。只要集群中超过一半的机器都能够正常工作,那么整个集群就能够正常对外服务。
3、严格顺序访问
对于来自客户端的每个更新请求,ZooKeeper都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序。
2、应用场景
ZooKeeper是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调存储服务。
注册中心、配置中心、集群管理、分布式锁、生成分布式唯一ID
(1)维护配置信息
zooKeeper、config、nacos都可以当做配置中心使用。分布式兴起,许多服务使用相同的配置文件,如果配置文件发送变化,运维上需要逐个修改服务的配置文件,非常繁琐。通常会将配置文件部署在一个集群上,提供服务,高效快速且可靠地完成配置项的更改等操作,并能够保证各配置项在每台服务器上的数据一致性。
zookeeper就可以提供这样一种服务,其使用Zab这种一致性协议来保证一致性。现在有很多开源项目使用zookeeper来维护配置,比如在hbase中,客户端就是连接 一个zookeeper,获得必要的hbase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列kafka中,也使用zookeeper来维护broker的信息。在alibaba开源的soa框架dubbo中也广泛的使用zookeeper管理一些配置来实现服务治理。
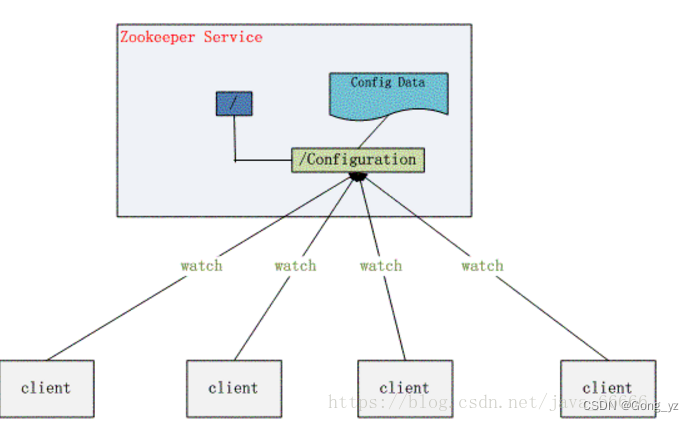
(2)集群管理&注册中心
一个集群有时会因为各种软硬件故障或者网络故障,出现某些服务器挂掉而被移除集群,而某些服务器加入到集群中的情况,zookeeper会将这些服务器加入/移出的情况 通知给集群中的其他正常工作的服务器,以及及时调整存储和计算等任务的分配和执行等。此外zookeeper还会对故障的服务器做出诊断并尝试修复。
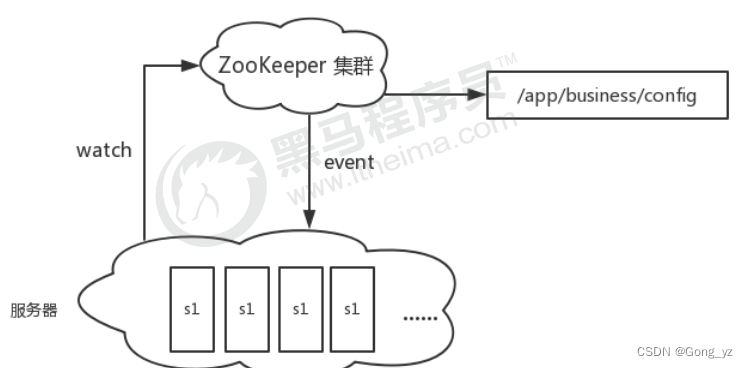
(3)分布式锁
多台服务器上运行着同一种服务,要协调各服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁,如果当前机器挂掉后,释放锁并fail over 到其他的机器继续执行该服务。
(4)生成分布式唯一ID
单库单表型系统中,通常可以使用数据库字段自带的auto_increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的 auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。做法如下:每次要生成一个新Id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新Id,然后把比自己节点小的删除即可。
3、数据模型
zookeeper的数据节点可以视为树状结构(或者目录),树中的各节点被称为znode(即zookeeper node),类似Linux的文件系统,一个znode可以有多个子节点。zookeeper节点在结构上表现为树状;使用路径path来定位某个znode,比如/ns-1/itcast/mysql/schema1/table1,此处ns-1、itcast、mysql、schema1、table1分别是根节点、2级节点、3级节点以及4级节点;其中ns-1是itcast的父节点,itcast是ns-1的子节点,itcast是mysql的父节点,mysql是itcast的子节点,以此类推。
znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。
节点类型:
zookeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
持久化节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
4、Zookeeper使用
参考链接:https://blog.csdn.net/java_66666/article/details/81015302?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 卢煜明: 离诺奖最近的中科院院士与一包泡面引发的科学突破
- 科技云报道:2024年六大科技趋势前瞻,最热门的技术都在这里了!
- 等待队列头实现阻塞 IO(BIO)
- 全景产品发展前景展望
- 数据结构 | 查漏补缺
- ShardingSphere-JDBC学习笔记
- 一款完全免费的批量服务器监控运维工具——牧云主机管理助手
- 基于OpenCv的车道检测
- 查看单元测试用例覆盖率新姿势:IDEA 集成 JaCoCo
- Java使用lambda表达式对集合中的BigDecimal类型的属性求和