书生·浦语大模型--第三节课笔记--基于 InternLM 和 LangChain 搭建你的知识库
发布时间:2024年01月15日

大模型开发范式
LLM的局限性:时效性(最新知识)、专业能力有限(垂直领域)、定制化成本高(个人专属)
两种开发范式:
- RAG(检索增强生成):外挂知识库,首先匹配知识库文档,交给大模型。优势:成本低,实时更新,不需要训练。但受限于基座模型,知识有限,总结性回答不佳。
- Finetune(微调):轻量级训练微调,可个性化微调,是一个新的个性化大模型。但是需要在新的数据集上训练,更新成本仍然很高,无法解决实时更新的问题。
RAG
- 基本思想
LangChain框架:
通过组件组合进行开发,自由构建大模型应用。将私人数据嵌入到组件中。
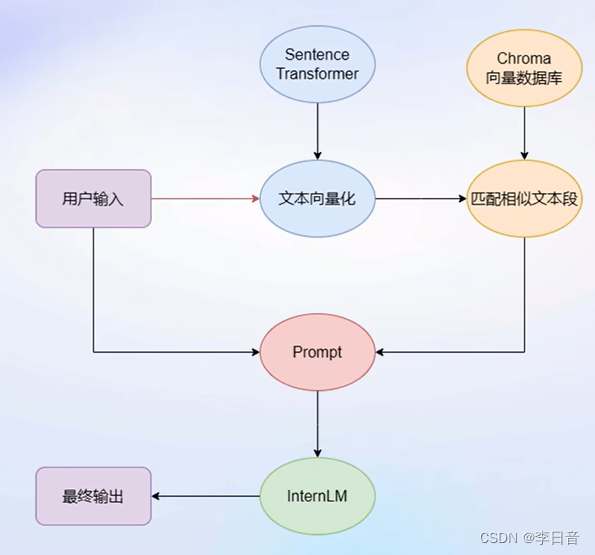
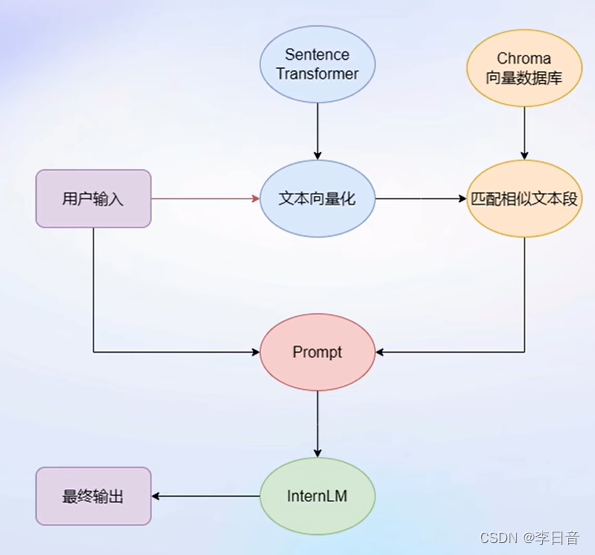
步骤:首先,Unstructed Loader 组件加载本地文档,将不同格式的文档提取为纯文本格式。通过Text Splitter组件对提取的纯文本进行分割成Chunk。再通过开源词向量模型Sentence Transformer来将文本段转化为向量格式,存储到基于Chroma的向量数据库中,接下来对用户的每个输入会通过Sentence Transformer转为为同样维度的向量,通过在向量数据库中进行相似度匹配找到和用户输入的文本段,将相关的文本段嵌入到已经写好的Prompt Template中,最后交给LLM回答即可。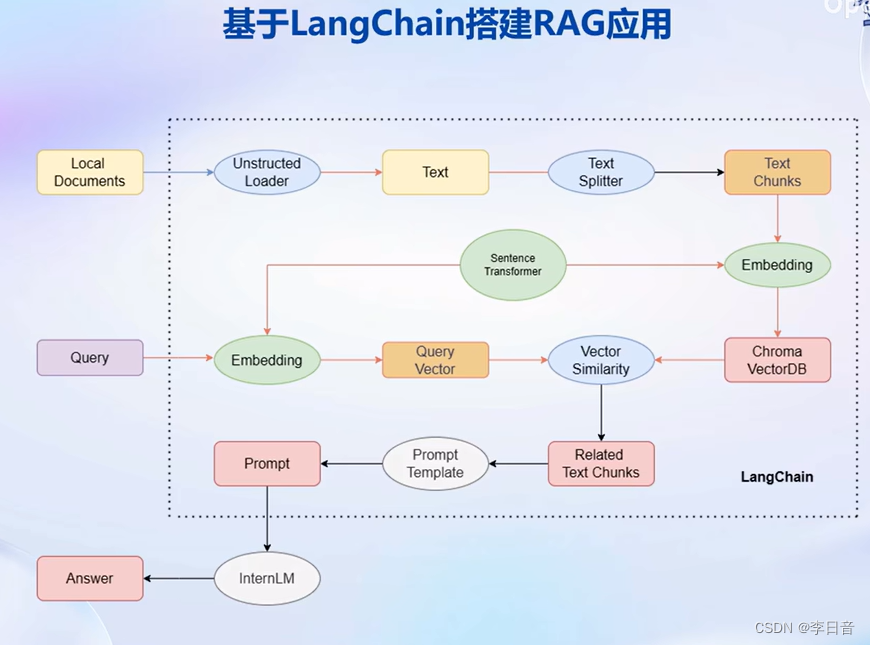
构建向量数据库
基于个人数据构建向量数据库。LangChain支持自定义LLM,可以直接接入到框架中。
- 多种数据类型,针对不同类型选取不同加载器,转化为无格式字符串。
- 由于单个文档超过模型上下文上限,还需要对文档进行切分。
- 使用向量数据库支持语义检索,需要将文本向量化存入向量数据库
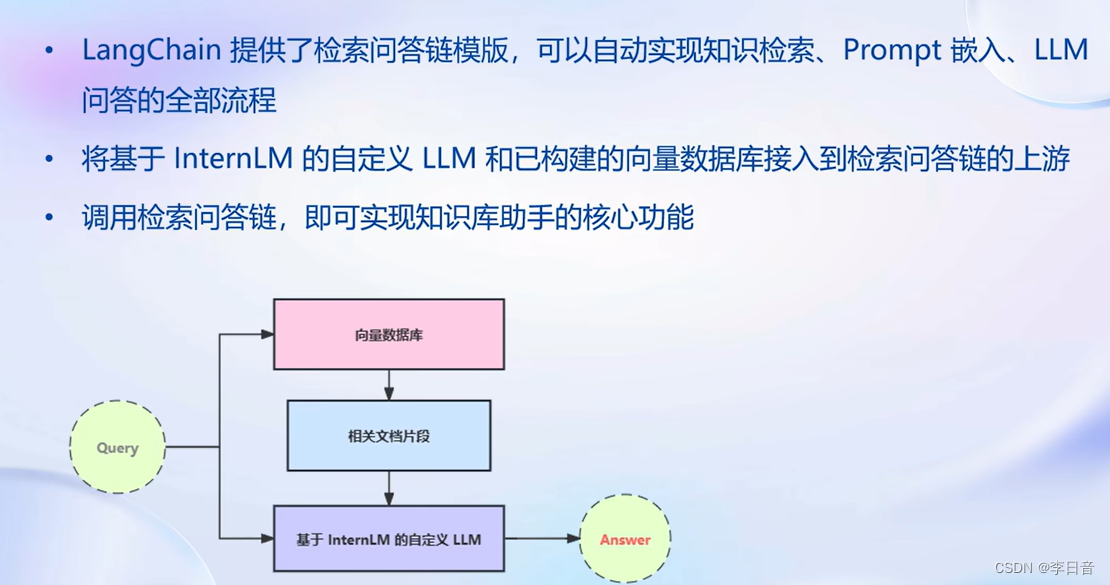
构建检索问答链
自动实现知识检索、Prompt嵌入、LLM问答。
问答性能还有所局限
优化建议
基于语义切分而不是字符串长度。
给每个chunk生成概括性索引。

web 部署
简易框架:Gradio、Streamlit等
实践部分
文章来源:https://blog.csdn.net/lalala12ll/article/details/135609077
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql的性能调优,explain的用法,explain各字段的解释
- B/S架构云端SaaS服务的医院云HIS系统源码,自主研发,电子病历病历4级
- java 赋值运算符、自增自减运算符、关系运算符、逻辑运算符、三元运算符
- Nacos配置管理
- Stable-Diffusion|从图片反推prompt的工具:Tagger(五)
- PYTHON十五分钟:从入门到熟悉
- Google推出Gemini AI开发——10年工作经验的Android开发要被2年工作经验的淘汰了?
- 处理机调度与死锁
- 计算机网络概述
- Linux下进程子进程的退出情况