由浅入深走进Pythony异步编程【多线程】(含代码实例讲解 || GIL锁,CPU密集型、守护线程、递归锁,线程池)
写在前面
从底层到第三方库,全面讲解python的异步编程。这节讲述的是python的多线程实现,纯干货,无概念,代码实例讲解。
本系列有6章左右,点击头像或者专栏查看更多内容,陆续更新,欢迎关注。
部分资料来源及参考链接:
https://www.bilibili.com/video/BV1Li4y1j7RY/
进程与线程的关系
记住这个就行:
- 进程只是占内存
- 线程才消耗CPU
- 默认一个进程至少一个线程
- 一般称为主进程和主线程
以这个PostgreSQL的进程为例,从任务管理器看,它是这样的:

它占用了一定的内存,没有任何变化,例如0.2MB,0.5MB,一旦对服务进行唤起,就会创造线程开始工作,前面就不会是0%了
所以,这就是前面4条所说的,进程占内存,线程消耗CPU,一个进程至少一个线程,一般称为主进程和主线程
GIL锁
全名叫全局解释器锁(GIL),简单来说,就是用于同步线程的一种机制,它仅允许同一时间执行一个线程。
假设现在有两个线程A、B,它们都要修改一个变量,它们两个就会抢锁,一个线程抢到后,另一个线程只能等待,就类似于上锁了。
多线程测试CPU密集型
你可以用下面的代码进行一个测试:
直接工作:
import time
#CPU 裸奔
def start():#单纯计算 消耗CPU资源 没有实际意义
data = 0
for _ in range(10000000):
data += 1
return
if __name__ == "__main__":
time_data = time.time()#程序启动时间
for _ in range(10):#执行10次 这个 _ 代表 我们不打算使用这个变量
start()
print(time.time() - time_data)#当前时间 减去 启动时间 = 程序过程耗时
多线程:
import time
import threading
def start():
data = 0
for _ in range(10000000):
data += 1
return
if __name__ == "__main__":
time_data = time.time()
ts = {}
for i in range(10):
t = threading.Thread(target = start)
t.start()
ts[i] = t
for i in range(10):
ts[i].join()
print(time.time() - time_data)
结果是这样的:
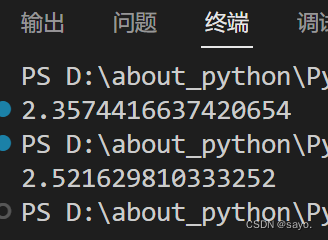
多线程反而变慢了。
这就是CPU密集型,其中大部分的时间都用在处理GIL锁,频繁的开锁和解锁,反而速度变慢了。所以在一些消耗cpu的计算性工作上,python反而不推荐使用多线程。
但是在IO密集型中,例如网络爬虫,文件读写,数据库操作,计算量相对较少时,多线程的速度就快很多。因为不需要大量的计算,CPU利用率相对较低,推荐使用多线程。
非堵塞线程、堵塞线程、守护线程
import threading
import time
def start():
time.sleep(2)
print(threading.current_thread().name)#打印线程名字
print(threading.current_thread().is_alive())#打印当前线程还活着
print(threading.current_thread().ident)#打印当前线程的ID
if __name__ == "__main__":#主线程
print('程序开始')
#以下是我们创建的线程 主线程 会跳过 创建线程
t = threading.Thread(target = start,name = '我的第一个线程')#target参数填函数名 不要用括号
t.start()#开始执行
# t.join()#堵塞线程
print('程序结束')
运行的结果是
程序开始
程序结束
我的第一个线程
True
20236
为什么程序开始,会立刻打印程序结束呢?
是因为当前为非阻塞线程,主线程可以跳过创建的子线程
如何完成阻塞线程呢?
在原程序上加上 t.join(),就可以让主线程进行阻塞并等待子线程
守护线程
现在变更主线程内容
if __name__ == "__main__":#主线程
print('程序开始')
#以下是我们创建的线程 主线程 会跳过 创建线程
t = threading.Thread(target = start,name = '我的第一个线程')#target参数填函数名 不要用括号
t.daemon = True#启动守护线程 主线程结束 所有线程一起死
t.start()#开始执行
# t.join()#堵塞线程
print('程序结束')
程序结果为
程序开始
程序结束
现在时非阻塞状态下,当主线程结束时,所有线程都会结束,它就保证了线程安全
多线程冲突
尝试以下代码:
import threading
data = 0
def add_data():
global data
for _ in range(1000000):
data += 1
def down_data():
global data
for _ in range(1000000):
data -= 1
if __name__ == "__main__":
print('start')
t = threading.Thread(target = add_data)
t2 = threading.Thread(target = down_data)
t.start()
t2.start()
t.join()
t2.join()
print(data)
print('end')
如果你是较低版本的python3,或者直接使用python2,你会得到奇怪的结果,类似这样:
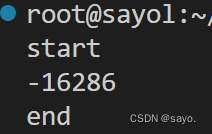
这就是多线程冲突问题,第一个线程还没来得及加就被减完了,结果是混乱的。
(如果你使用的是高版本的python,例如3.8以上,python本身会帮助你规避这个问题。GIL的实现可能做了一些优化和改进,使得数据竞争问题的出现几率较低。这可能会导致在某些情况下,多个线程对 data 进行加减操作时,最终的结果可能是正确的。但是这样的写法仍然是线程不安全的。)
普通锁和递归锁
为了解决这个问题,就会上锁,python 使用的是重量级锁,示例如下
import threading
lock = threading.Lock()
data = 0
def add_data():
global data
for _ in range(1000000):
lock.acquire()
data += 1
lock.release()
def down_data():
global data
for _ in range(1000000):
lock.acquire()
data -= 1
lock.release()
if __name__ == "__main__":
print('start')
t = threading.Thread(target = add_data)
t2 = threading.Thread(target = down_data)
t.start()
t2.start()
t.join()
t2.join()
print(data)
print('end')
这样,得到就是期望的结果0,lock = threading.Lock()就是普通锁
什么是递归锁呢?
上述的上锁,解锁显然非常不优雅。程序非常繁琐,这里就要引入递归锁的概念,它的写法就是这样:
rlock = threading.RLock()
配合with,就可以实现自动开关锁,写法就像这样:
import threading
class Rlock_Data():
rlock = threading.RLock()#递归锁
def __init__(self):
self.data = 0
def execute(self,n):
with Rlock_Data.rlock:#自动开关
self.data += n
def add(self):#加 1 操作
with Rlock_Data.rlock:#自动开关
self.execute(1)
def down(self):#减 1 操作
with Rlock_Data.rlock:#自动开关
self.execute(-1)
def add_data(rlock):
for _ in range(1000000):#连续加 一百万次
rlock.add()
def down_data(rlock):
for _ in range(1000000):#连续减 一百万次
rlock.down()
if __name__ == "__main__":
print('程序开始')
t = Rlock_Data()
t1 = threading.Thread(target = add_data,args=(t,))#target参数填函数名 不要用括号
t2 = threading.Thread(target = down_data,args=(t,))#args参数把Rlock_Data实例传进去
t1.start()#开始执行
t2.start()
t1.join()#堵塞线程
t2.join()
print(t.data)
print('程序结束')
解释一下threading.Thread(target = add_data,args=(t,))这段语句,显得比较奇怪,首先传递的一个回调函数,直接给上方法名,后面的(t,)是为了识别为元组,不加括号会被识别为整型。
线程池
按照之前的思路threading.Thread可以创造一个线程,那么开启多线程就像这样:
for i in range(10):
t = threading.Thread(target = start)#target参数填函数名 不要用括号
t.start()
ts[i] = t #全新的线程
利用循环打开多个线程,但是这会带来一个问题,每次打开的线程都是新的,例如你当前开启了100个线程,运行完毕后,就得关闭这些线程,重新再创建100个线程继续运行。显然,这样会降低效率
线程池就可以解决这个问题,它可以反复利用旧的线程,直接进行独立的线程创建,一直反复用就行。就像打开了若干管道,数据在里面进行传输,而且这是很好的解耦思路,将创建线程和数据本身分割开来,逻辑更加清晰
用下面这个代码来体会一下:
import time
import threadpool
#先用pip install threadpool 检查是否安装
#执行比较耗时的函数,需要开启多线程
def get_html(url):
time.sleep(3)
print(url)
urls= [i for i in range(10)]#生成10个数 for的简洁写法
pool = threadpool.ThreadPool(10)#建立线程池 开启10个线程
requests = threadpool.makeRequests(get_html,urls)#提交10个任务到线程池
for req in requests:#开始执行任务
pool.putRequest(req)#提交
pool.wait()#等待完成
除了threadpool的第三方模块,python从3.2开始当然也有自带的异步执行的方法,也可以实现线程池
from concurrent.futures import ThreadPoolExecutor,as_completed
import time
number_list = [1,2,3,4,5,6,7,8,9,10]
def add_number(data):#这个函数 只能消耗CPU资源 没啥意义
item = count(data)
return item
def count(number):#单纯计算 随便写
for i in range(0,5000000):
i = i + 1
return i * number
if __name__ == "__main__":
start_time = time.time()#程序启动时间
#开启线程池
with ThreadPoolExecutor(max_workers = 5) as t:# max_workers参数为 你要开多少个线程
for item in number_list:#提交任务
t.submit(add_number,item)
# reqs = [t.submit(add_number,item) for item in number_list]#提交任务 简洁写法
# for req in as_completed(reqs):# 转成 可迭代对象
# print(req.result())#打印信息
print('程序总耗时:{}'.format(time.time() - start_time))#当前时间 减去 启动时间 = 程序过程耗时
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Excel如何插入行?4个简单方法轻松完成!
- 机器学习之常用激活函数
- TIMESNET: TEMPORAL 2D-VARIATION MODELINGFOR GENERAL TIME SERIES ANALYSIS
- Mastercam各版本安装指南
- 2023 年度龙蜥最佳用户案例奖揭晓,中国移动、小红书、中国人寿财险等企业上榜!
- 使用react-router-dom获取路径url地址
- JumpServer3.0版本-权限管理
- Vue2+Vue3组件间通信方式汇总(3)------$bus
- 2023-RunwayML-Gen-2 AI视频生成功能发展历程
- 3d重建 26ms