【Java并发】深入浅出 synchronized关键词原理-下
上一篇文章,简要介绍了syn的基本用法和monter对象的结构,本篇主要深入理解,偏向锁、轻量级锁、重量级锁的本质。
对象内存布局
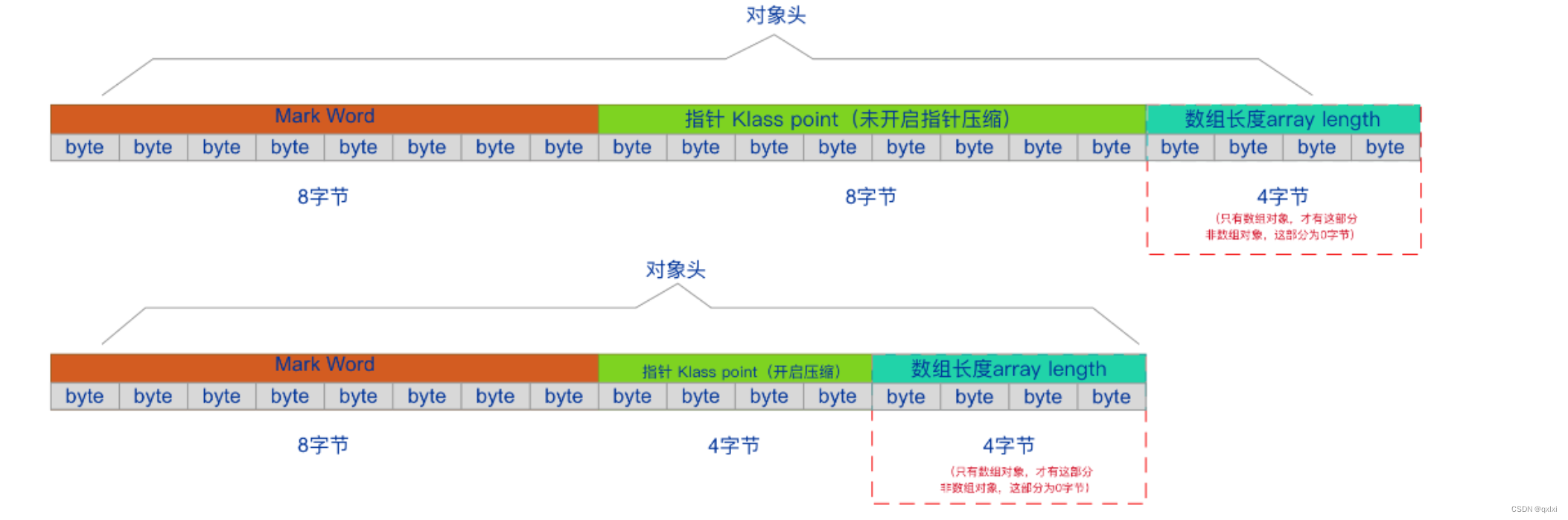
Hotspot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据 (Instance Data)和对齐填充(Padding)。
对象头:比如 hash码,对象所属的年代,对象锁,锁状态标志,偏向锁(线程)ID, 偏向时间,数组长度(数组对象才有)等。
实例数据:存放类的属性数据信息,包括父类的属性信息;
对齐填充:由于虚拟机要求 对象起始地址必须是8字节的整数倍。填充数据不是必须存 在的,仅仅是为了字节对齐。
对象头详解
HotSpot虚拟机的对象头包括:
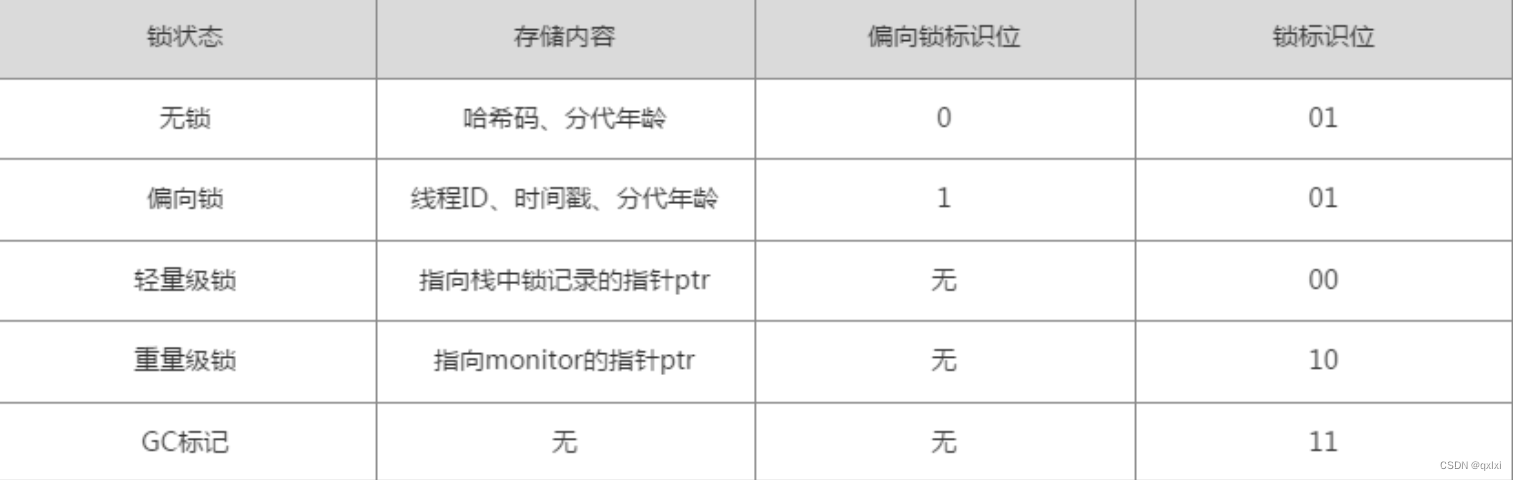
- Mark Word 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机中分别为 32bit和64bit,官方称它为“Mark Word”。
- Klass Pointer
对象头的另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指 针来确定这个对象是哪个类的实例。 32位4字节,64位开启指针压缩或最大堆内存<32g时4字 节,否则8字节。jdk1.8默认开启指针压缩后为4字节,当在JVM参数中关闭指针压缩(-XX:- UseCompressedOops)后,长度为8字节。 - 数组长度(只有数组对象有)
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度。 4字节
如何查看java对象信息数据
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
可以发现一个Object在压缩情况下是16字节。对其填充4字节。
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
思考题:markword如何记录锁状态的?

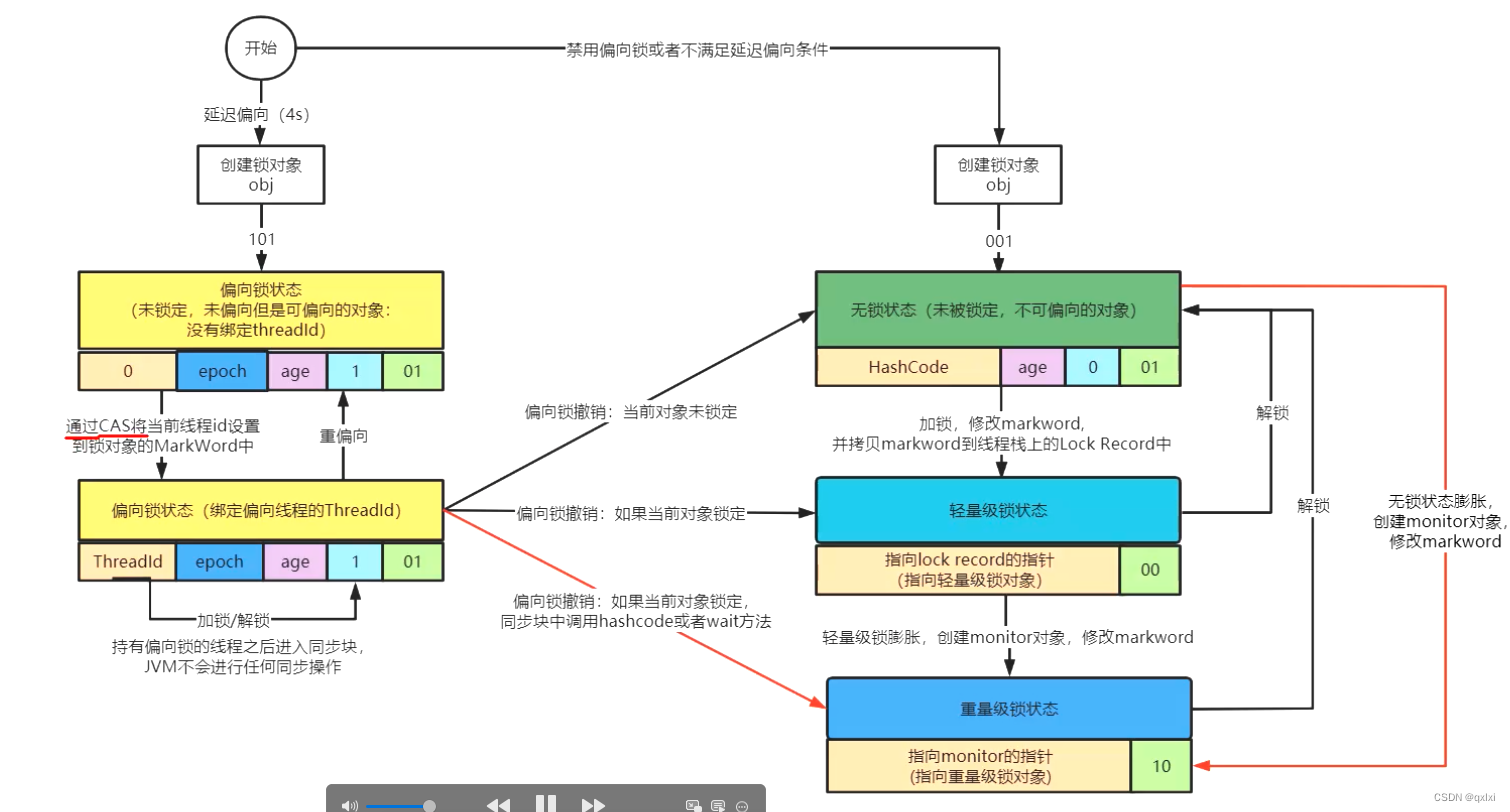
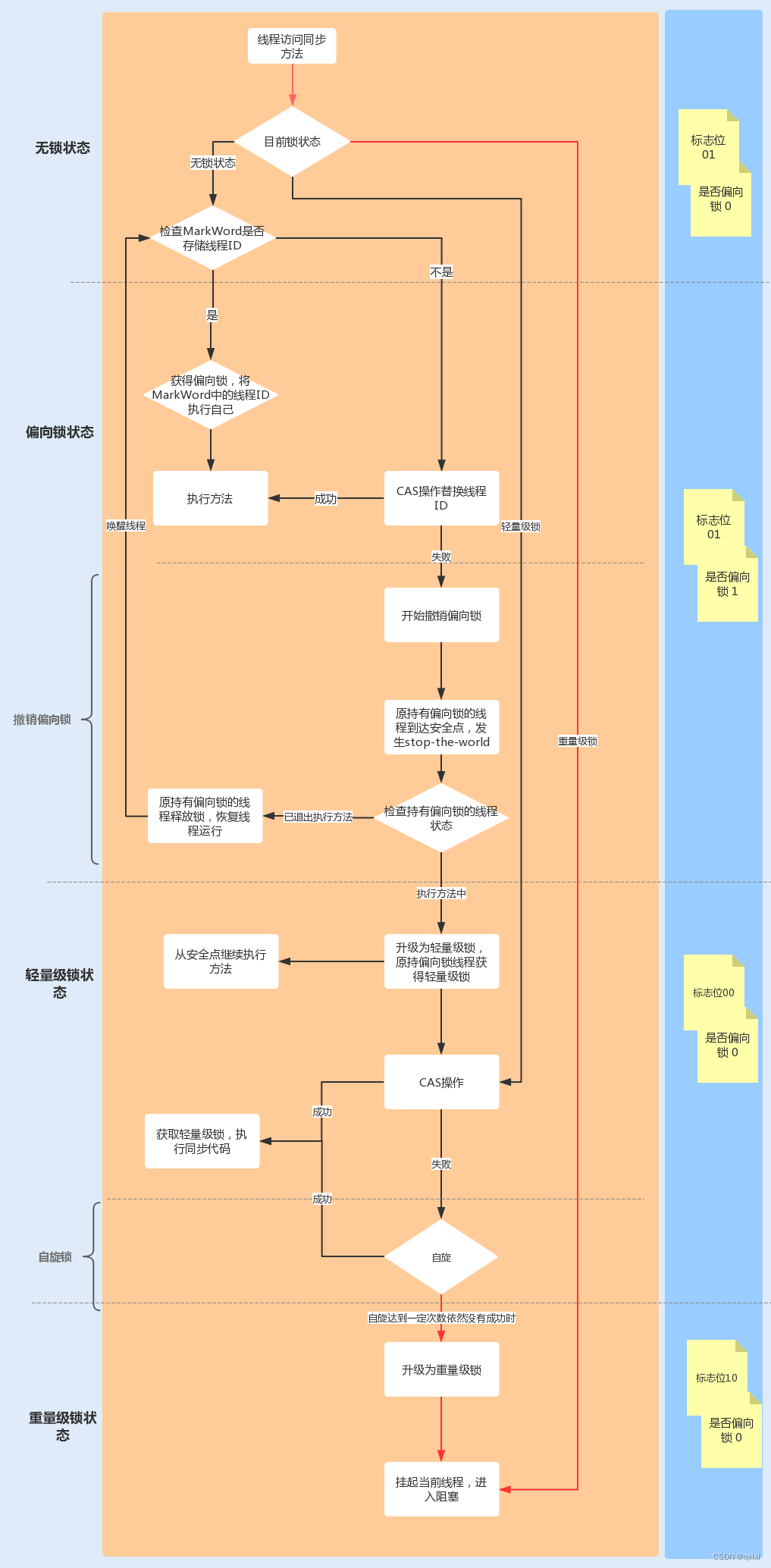
这里有一个问题,那就是为什么需要锁升级 在于原来的syn的锁比较重,每次wait\notify都需要从用户态到内核态的转换。而利用偏向锁和轻量级锁,可以在用户态没有竞争或者两个线程竞争的前提下进行锁竞争,避免频繁切换到内核态。你看本质上还是为了提高锁的性能。
偏向锁
偏向锁是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了消除数据在无竞争情况下锁重入(CAS操 作)的开销而引入偏向锁。对于没有锁竞争的场合,偏向锁有很好的优化效果。
偏向锁延迟
偏向锁模式存在偏向锁延迟机制:HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建 的对象开启偏向锁模式。JVM启动时会进行一系列的复杂活动,比如装载配置,系统类初始化等 等。在这个过程中会使用大量synchronized关键字对对象加锁,且这些锁大多数都不是偏向锁。 为了减少初始化时间,JVM默认延时加载偏向锁。
//关闭延迟开启偏向锁
‐XX:BiasedLockingStartupDelay=0 3 //禁止偏向锁
‐XX:‐UseBiasedLocking
//启用偏向锁
‐XX:+UseBiasedLocking
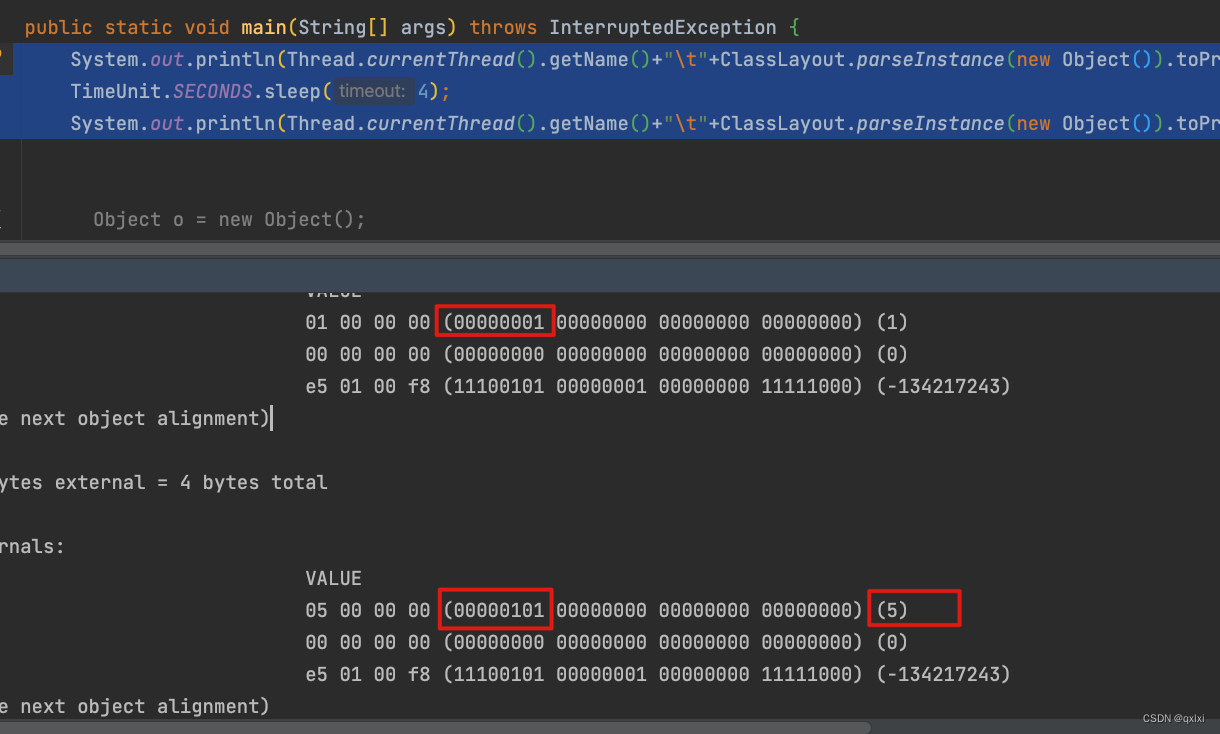
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(new Object()).toPrintable());
TimeUnit.SECONDS.sleep(4);
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(new Object()).toPrintable());
偏向锁
public static void main(String[] args) throws InterruptedException {
TimeUnit.SECONDS.sleep(4);
Object obj = new Object();
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj) {
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
}
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
},"T1").start();
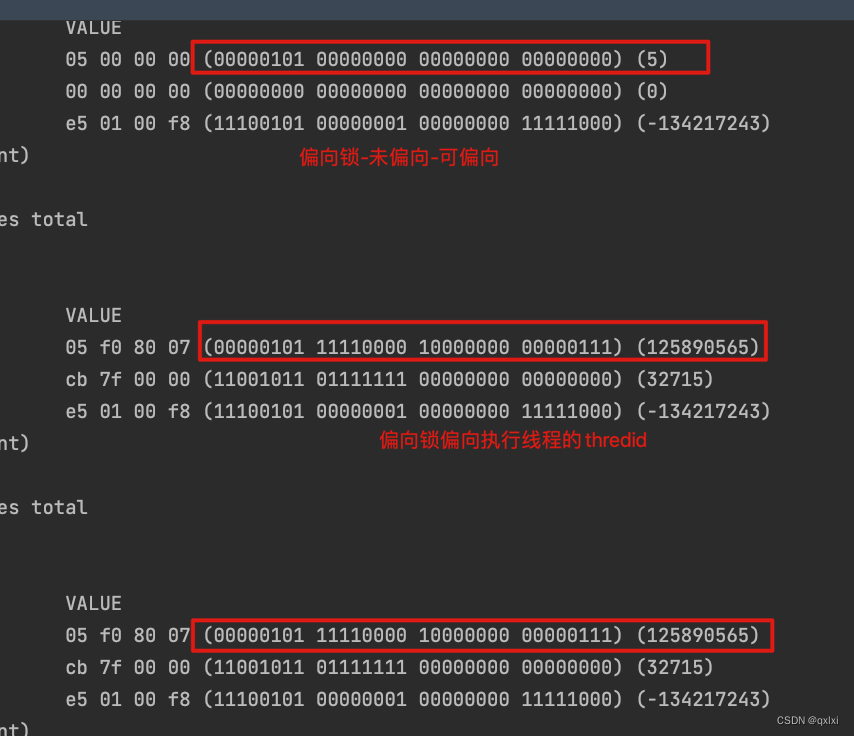
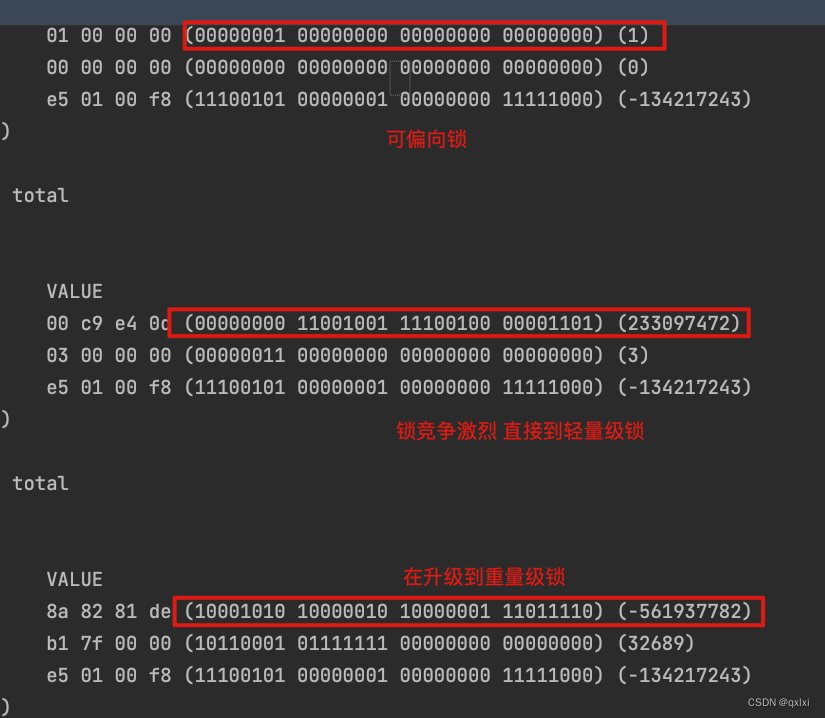
**流程:**可以发现,当一个对象刚被创建的时候,markword处于无锁状态,并随即进入偏向锁状态,此时mark word字段中的threadI为0,此时线程获取某个对象的syn关键字的时候,会发现这个对象时处于可偏向的,101的。并且threadId为0.就会通过cas原子操作竞争这个偏向锁。markword为5 (101) 如果cas成功,则将当前线程的id设置进去。
但是发现在执行完,syn代码块的时候,发现并没有退出偏向锁。原因在于偏向锁不会主动释放,主要是提高加锁的效率。当这个线程再次获取syn对象锁的时候,可以判断markword是否偏向以及thredid是不是自己的线程id 做处理,如果是的话,直接可以使用。并且CAS操作其实是硬件层面的操作,
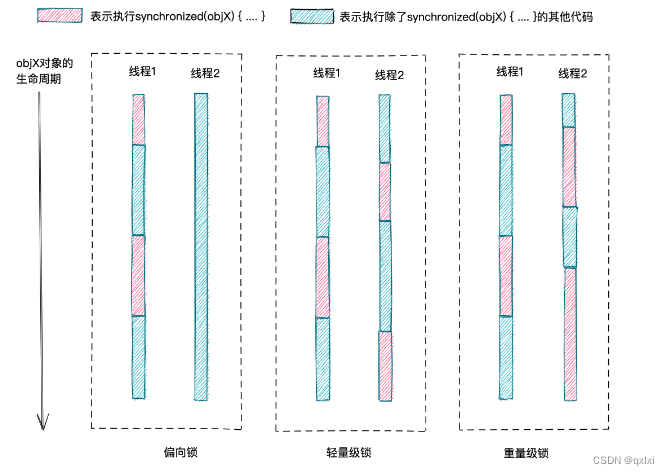
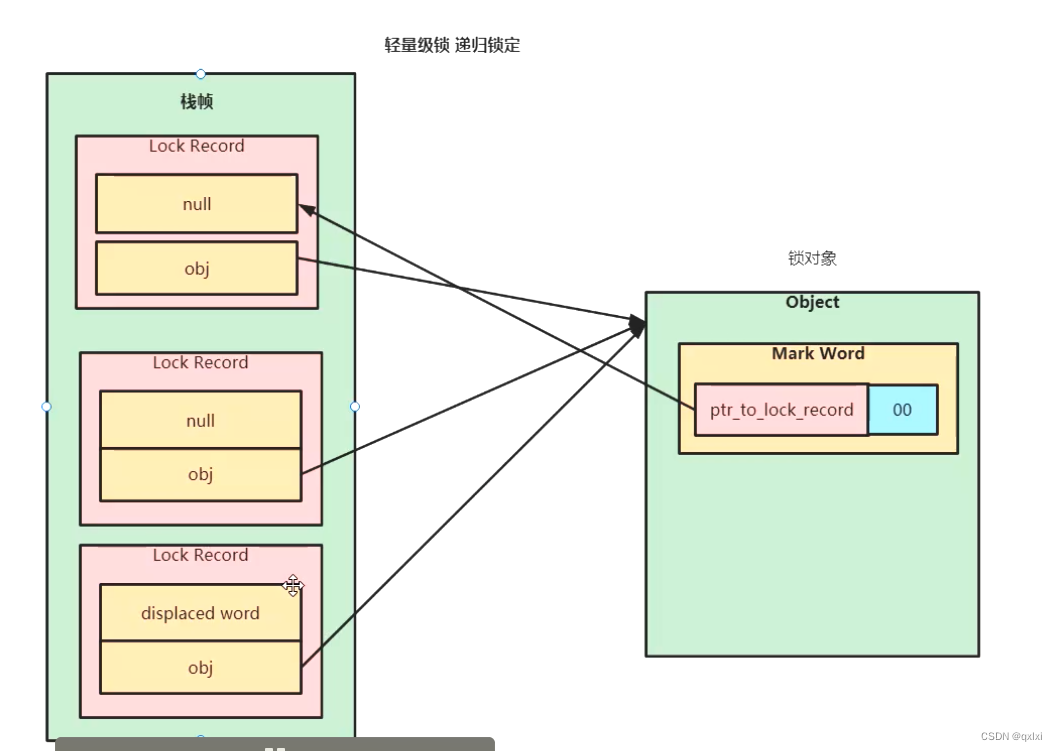
轻量级锁
在一个线程获取锁的时候,会设置为偏向锁,但是当两个线程交替执行的时候,会从偏向锁升级为轻量级锁。轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间多个线程访问同一把锁的场合,就会导致轻量级锁膨胀为重 量级锁。
TimeUnit.SECONDS.sleep(4);
Object obj = new Object();
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
}},"T1").start();
Thread.sleep(1000);
new Thread(()->{
synchronized (obj) {
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
}
System.out.println(Thread.currentThread().getName()+"\t"+ClassLayout.parseInstance(obj).toPrintable());
},"T2").start();
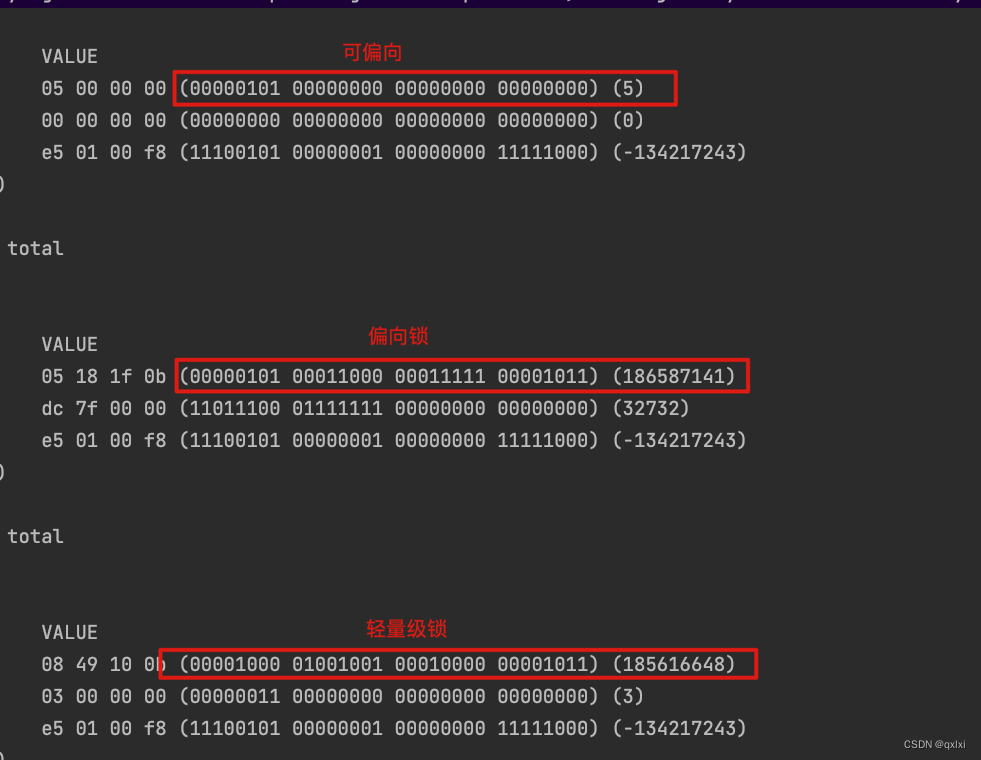
从图中可以看出,锁一开始是可偏向,线程T1cas获取到偏向锁,但是线程T2没有获取到,自己CAS失败,偏向锁不会主动释放锁,因此在升级偏向锁时,虚拟机需要暂停持有偏向锁的线程,查看是否还在使用这个偏向锁,如果不在使用,那么就会将markword设置为无锁状态,如果这个锁还在使用,那就升级为轻量级锁。
好了我们来思考几个问题
为什么需要在将偏向锁升级时需要暂停偏向锁?
这是因为虚拟机需要根据持有偏向锁的线程是否正在使用偏向锁,来决定将偏向锁转为无锁还是轻量级锁,其实检查这类也是复合操作。因为是两个不同的线程操作,虚拟机线程可能检查到没有使用偏向锁,但是过了一会线程获取到偏向锁。显然无法将偏向锁设置为无锁状态,所以需要暂停持有偏向锁的线程。如何暂停就直接使用gc中的STW(stop the word)
能否不把偏向锁线程状态会退回偏向状态
其实如果出现线程竞争,会退到可偏向状态,可能会导致频繁的STW,所以还不如回退到无锁状态。
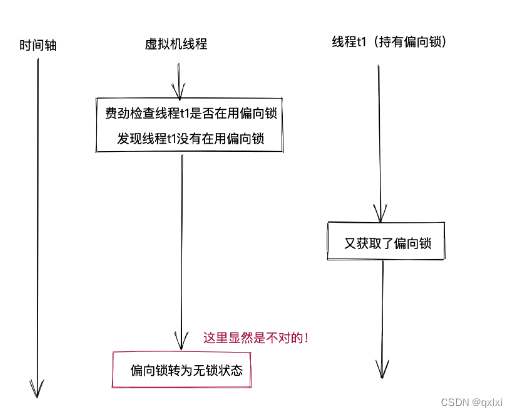
市面上很多的资料都是锁升级就是无锁->偏向锁-》轻量级锁->重量级锁。 其实是不准确的。正确的其实是一开始是偏向锁状态,根据偏向锁的是否持有线程判断,如果没有持有就升级到无锁状态,如果持有锁,并且还有一个线程竞争的前提下,那就升级到轻量级锁。如果竞争更加激烈,升级到重量级锁。但是升级到重量级锁后是无法降级的。
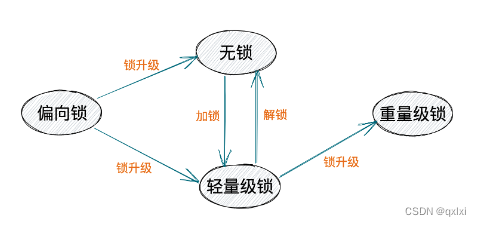
重量级锁
在上述代码的基础上,在加一个线程获取,就可以获得此效果。
锁消除
除了syn的锁升级,syn还有两个优化,那就是锁消除和锁粗化,虚拟机在JIT编译时,会根据代码的分析,去掉没有必要的锁,在多线程操作的安全性,StringBuffer中的append函数 设计实现时加了锁,在下面代码中,strBuffer是局部变量,不会被多线程共享,更不后在多线程环境下调用它的append函数,append函数的锁就可以被优化消除。

锁粗化
锁组化,其实也是在JIT编译的时候,根据锁的范围,将多个小的锁范围,调整为一个。比如如下,就是将1W次的append加解锁,粗化成一次。

总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2. 套圈(分治)
- MySQL基础篇(四)事务
- 内核编译与系统调用
- 细胞基因完整矩阵转10xGenomics稀疏矩阵文件
- 游戏引擎?
- Jenkins Docker Cloud在Linux应用开发CI中的实践
- 从微信审批表单中拿数据写入MySQL,使用dolphinscheduler定时调度
- 每天五分钟计算机视觉:揭秘迁移学习
- 服务器如何设置禁ping,禁ping有哪些作用
- 漏洞复现-红帆OA iorepsavexml.aspx文件上传漏洞(附漏洞检测脚本)