电商平台商品详情API接口|商品详情页(一)
电商网站上:
小电商:页面静态化的方案;
比如 电商平台商品详情API接口商品的信息放到表中 + 页面模板,渲染成html页面,每次用户请求的时候,直接返回html页面,不涉及到业务逻辑。
缺点一旦模板发生了变更,所有的Html页面需要重新渲染,小网站还ok,大网站不可。
大型电商网站:商品详情页
????????多级缓存+双层nginx提高命中率+热点数据自动降级+缓存维度化
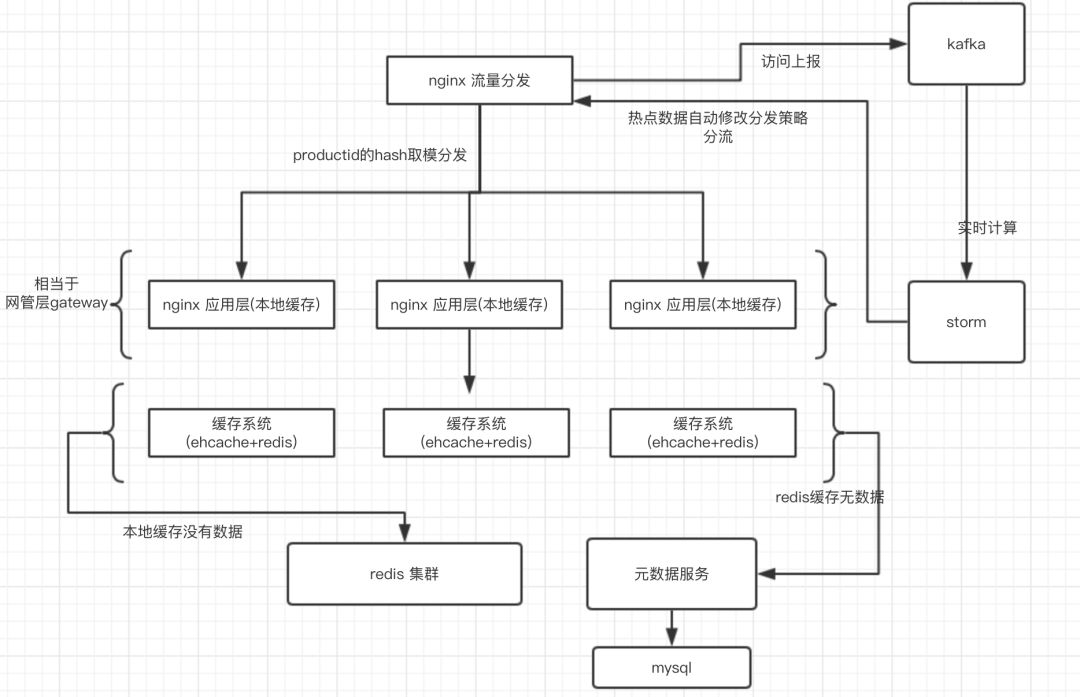
==>多级(三级)缓存每一级的意义
① nginx分发层,根据productId的hash取模,将流量分发到应用层nginx,nginx本地缓存扛热点数据,如果缓存仅仅放在redis,则多N次的网络开销。
② redis扛大量的离散数据。(单机的redis的QPS大概到几W)
③ ehcache扛redis集群大规模灾难,避免Mysql裸奔。
==>缓存多维度
将实时性要求比较高的信息(库存|销量等) 和 实时性要求不高的信息 分开存储。
其中实时性不高的信息 (商品信息,分类信息,店铺信息)也 分key-value缓存。
实时性要求比较高的信息,采用数据库+mysql同步双写。实时性要求不高的信息,采用异步写缓存。
这样做的好处:
① redis的性能和吞吐量:数据越大,吞吐量急剧下降
② 降低更新缓存的频率
==>双层nginx提高缓存命中率
假设仅仅有第二层缓存,一个请求过来随机打到不同的nginx上,同一个productId而言,第一次打到一台nginx机器上,本地加载了缓存,第二次过来请求打到了不同的nginx机器上,查看nginx本地缓存无。
双层nginx缓存,请求统统到分发层nginx,根据分发策略(比如productId的hash取模),这样,对于同一个productId请求会打到同一个应用层nginx。
应用层nginx相当于网管层gateway。
==>热点数据自动降级
① nginx+lua将访问流量上报到kafaka
② storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案
热点:某个商品的访问量,瞬间超出了普通商品访问量的10倍,或者100倍,1000倍。
③?热点一旦统计出来,storm会直接发送http请求到nginx上,nginx如果发现某个商品是热点数据,就立即做流量分发策略的降级。
在所有的应用层nginx本次缓存上加载热点数据,同时对该商品的分发策略,从hash取模修改成随机,分发到不同的nginx应用层,来分发流量。
java和大数据的关系:
storm和spark的区别
对于strom来说
1.纯实时(毫秒级),不能忍受1秒以上延迟
2.支持事务
3.高峰低峰时间段,动态调整实时计算程序
4.纯实时,不需要在中间执行SQL交互式查询
对于spark streaming来说
1.准实时(秒级),不要求强大可靠的事务机制,不要求动态调整并行度
2.如果一个项目除了实时计算之外,还包含了离线批处理,交互式查询等业务功能,而且实时计算中,可能还牵扯到 高延迟批处理,交互式查询等功能,那么首选Spark生态,用Spark Core开发离线批处理,用Spark Sql开发交互式查询,用Spark Streaming开发实时计算,三者无缝整合。
总之,Spark Streaming有一点是Storm绝对比不上的,他位于Sparking生态技术栈中,因此Spark Streaming和Spark Core,Spark SQL无缝整合,也就是意味着,可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理,交互式查询等操作。
Storm在实时延迟上,比Spark Streaming厉害。
hive和hbase的区别
hive中的表是纯逻辑表,只是定义了表定义,本身不存储数据,完全依赖HDFS和MapReduce。将结构化的数据文件映射为一张数据表,并提供了HQL查询功能,并将HQL最终转换为MapReduce任务进行运行。不适用于实时查询,因为耗时比较严重。
HBase是物理表。海量数据的在线储存和简单查询,替代MySQL分库分表,提供更好的伸缩性。非常适合用来进行大数据的实时查询。
Storm的集群架构和核心概念
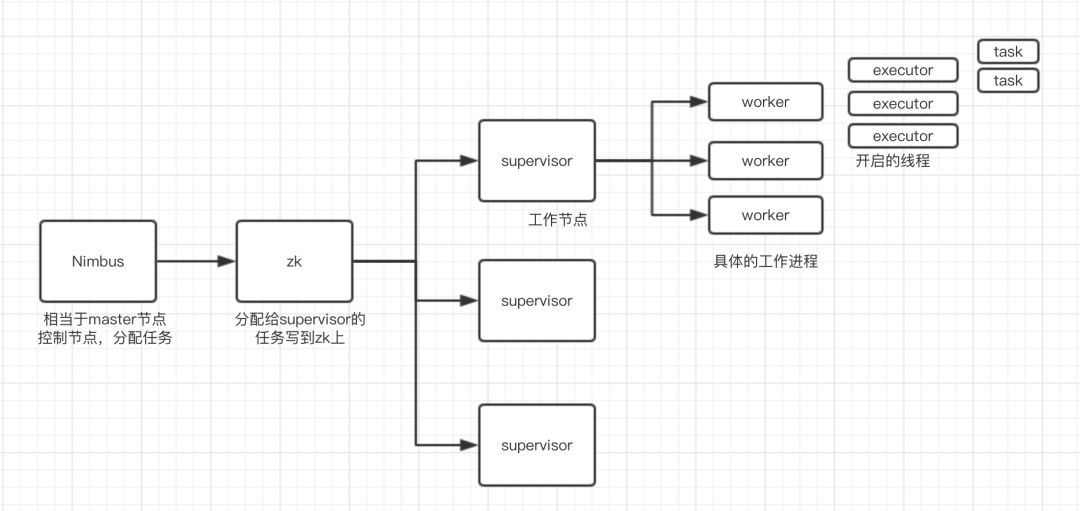
Storm的集群架构
nimbus -> supervior -> worker -> executor -> task
物理架构如下:
Storm的核心概念
Topology; spout; Bolt; Tuple; Stream
Spout:数据源的一个代码组件,实现了一个Spout接口,写一个java类,在这个spout代码中,我们可以自己尝试去数据源获取数据,比如从kafka中消费数据。
bolt: 一个业务处理的代码组件,spout会将数据传送给bolt,实现了一个bolt接口。
topology: 流程图 ?一堆spout+bolt,就会组成一个topology,就是一个拓扑,实时计算作业,spout+bolt,一个拓扑涵盖了数据获取/生成+数据处理的所有代码逻辑,topology。
tuple:就是一条数据,每条数据都会被封装成tuple中,在多个spout和bolt之间传递;
stream: 就是一个流,源源不断过来的tuple,组成了一个流。
构建集群如下:
构建一主两从的结构,分配三台机器
114:nimbus节点? ? 115:supervisor节点 ?116:supervisor节点
配置文件中可以指定supervisor的端口(即工作进程worker的端口号)
nimbus的114机器下面可以看到 nimbus.log access.log metric.log的日志
supervisor的115机器下面可以看到 supervisor.log access.log metric.log的日志
在主节点开启管控台 storm ui &; ?jps查看进程
如何执行word count的代码示例:
将topology代码打成jar包,提交到nimubs节点,
执行 storm jar [jar名称] [main方法的类]
一旦开始执行以后,在supervisor节点jps命令可以看到多了个worker进程。
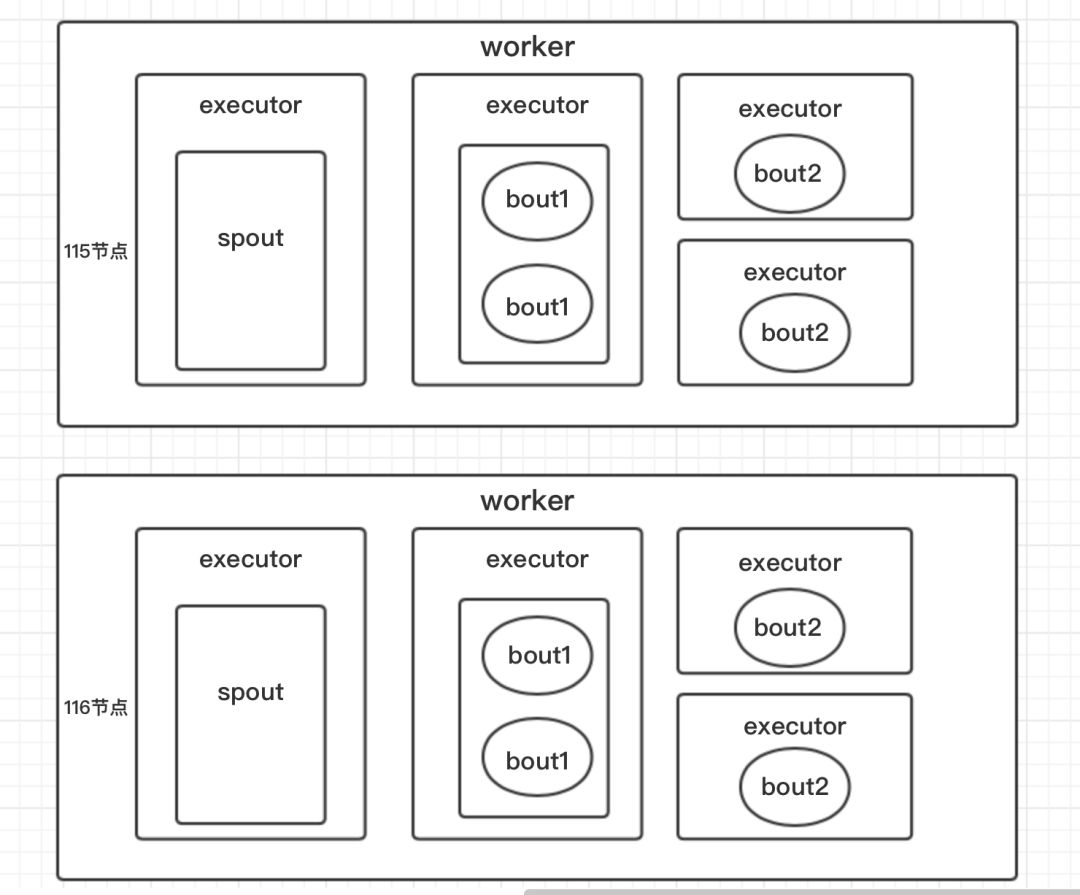
并行策略设定
worker=2
spout=2
bout1=2, numberTask=4
bout2=4
在物理节点supervisor上的分配如下:
redis持久化: RDB, ?AOF
RDB: 定时生成全量快照,作为冷备。redis主进程,去fork一个子进程,去执行RDB操作。
生成多个文件,每个文件都代表了某一个时刻的完整的数据快照。
AOF: 存放的是指令日志,做数据恢复的时候,其实是回放和执行所有的指令日志。而RDB是将数据直接加载到内存中。AOF速度比RDB略慢。但是可以更好的保证数据不丢失。
redis读写分离
写请求:1秒几千
大量的都是读请求
假如单个的redis能够承受的读是 5W QPS,如果流量上升,多搞几个slave的redis,分散读请求。水平扩容。
redis replication 基本原理
当slave刚启动的时候,会发一条ping数据给master,master会发 full resynchronization(全量复制)。
master在后台搞一个线程,把全量的快照文件发给slave。
正常情况来一条数据复制到一条数据到slave,如果异常什么的,就生成rdb快照。
哨兵
集群监控: 负责监控redis master和slave进程是否正常工作
消息中心: 如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知管理员。
故障转移: 如果Master node 挂掉,会自动转移到slave node上
哨兵本身也是分布式的,至少三个实例保证自己的健壮性
判断一个master node是否宕机了,需要大部分的哨兵都同意才行,涉及到选举问题。
脑裂问题
master主节点,出现了异常性,哨兵检测不到,故障转移,让原来的slave节点成为了master节点。于是就出现了两个主节点,大脑一分为二。
当redis会在数据达到一定的程度之后,清理掉一些数据LRU。
redis默认情况下就是使用LRU策略,最近最少使用的数据干掉。
可以在redis.conf中 设置 maxmemory
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端数据结构与算法总结<week two>
- java中的多态
- 【JS】按照a>b>c>d>e>f的优先级,将a,b,c,d,e,f元素进行筛选,选出三个不为空字符的元素进行字符拼接
- 【PHP进阶教程】手把手教你实现用户登录验证(附实战代码)
- 实现vue加载指令 v-loading
- 【jdk与tomcat配置&文件夹共享&防火墙设置(入站出站规则)】
- 智能分析网关V4+太阳能供电模式,搭建鱼塘养殖远程视频监控方案
- 微信登录失败 appid不能为空,错误码:10012
- 豆瓣酱生产加工污水处理需要哪些工艺设备
- 解决nvidia-smi报错:NVIDIA-SMI has failed because it couldn‘t communicate with the NVIDIA driver.