量化原理入门——Folding BN RELU
本文介绍量化中如何将BatchNorm和ReLU合并到Conv中。
Folding BatchNorm
BatchNorm是google提出的一种加速神经网络训练的技术,在很多网络中基本是标配。回忆一下BatchNorm其实就是在每一层输出的时候做了一遍归一化操作:
Input:Values of x over a mini-batch:
;
Parameters to be learned:
,
output:
? //mini batch mean
? // mini batch variance
?// normalization
?// scale and shift
Algorithm1:Batch normalizing transform, applied to activation x over a mini-batch。其中是网络中间某一层的激活值,
、
分别是其均值和方差,
则是经过BN后的输出。
一般卷积层与BN合并
?Folding BatchNorm不是量化才有的操作,在一般网络中,为了加速网络推理,我们也可以把BN合并到Conv中。
合并的过程是这样的,假设有一个已经训练好的Conv和BN:
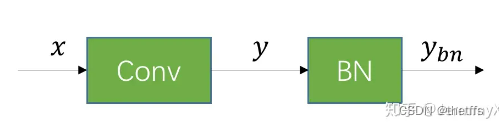
假设Conv的weight和bias分别是w和b,那么卷积层的输出为:
? (1)
途中BN层的均值和方差可以表示为和
,那么BN层的输出
可以表示为:
(2)
然后我们将(1)式代入(2)式得:
?(3)
我们用来表示
, 那么(3)式可以表示为:
?(4)
可以发现,(4)式形式上跟(1)式一模一样,因此它本质上也是一个Conv运算,我们只需要用和
来作为原来卷积的weight和bias,就相当于将BN的操作合并到了Conv里面。实际inference的时候,由于BN层的参数已经固定了,因此可以把BN层folding到Conv中,省去BN层的计算开销。

?卷积层和BN层合并,从pytorch官方扒出的对应代码如下:传送
def fuse_conv_bn_weights(
conv_w: torch.Tensor,
conv_b: Optional[torch.Tensor],
bn_rm: torch.Tensor,
bn_rv: torch.Tensor,
bn_eps: float,
bn_w: Optional[torch.Tensor],
bn_b: Optional[torch.Tensor],
transpose: bool = False
) -> Tuple[torch.nn.Parameter, torch.nn.Parameter]:
r"""Fuse convolutional module parameters and BatchNorm module parameters into new convolutional module parameters.
Args:
conv_w (torch.Tensor): Convolutional weight.
conv_b (Optional[torch.Tensor]): Convolutional bias.
bn_rm (torch.Tensor): BatchNorm running mean.
bn_rv (torch.Tensor): BatchNorm running variance.
bn_eps (float): BatchNorm epsilon.
bn_w (Optional[torch.Tensor]): BatchNorm weight.
bn_b (Optional[torch.Tensor]): BatchNorm bias.
transpose (bool, optional): If True, transpose the conv weight. Defaults to False.
Returns:
Tuple[torch.nn.Parameter, torch.nn.Parameter]: Fused convolutional weight and bias.
"""
conv_weight_dtype = conv_w.dtype
conv_bias_dtype = conv_b.dtype if conv_b is not None else conv_weight_dtype
if conv_b is None:
conv_b = torch.zeros_like(bn_rm)
if bn_w is None:
bn_w = torch.ones_like(bn_rm)
if bn_b is None:
bn_b = torch.zeros_like(bn_rm)
bn_var_rsqrt = torch.rsqrt(bn_rv + bn_eps)
if transpose:
shape = [1, -1] + [1] * (len(conv_w.shape) - 2)
else:
shape = [-1, 1] + [1] * (len(conv_w.shape) - 2)
fused_conv_w = (conv_w * (bn_w * bn_var_rsqrt).reshape(shape)).to(dtype=conv_weight_dtype)
fused_conv_b = ((conv_b - bn_rm) * bn_var_rsqrt * bn_w + bn_b).to(dtype=conv_bias_dtype)
return (
torch.nn.Parameter(fused_conv_w, conv_w.requires_grad), torch.nn.Parameter(fused_conv_b, conv_b.requires_grad)
)?
? ?量化BatchNorm Folding
量化网络时可以用同样的方法把BN合并到Conv中。
如果量化时不想更新BN的参数(后训练量化),那我们就先把BN合并到Conv中,直接量化新的Conv即可。
如果量化时需要更新BN的参数(比如量化感知训练),那也很好处理。Google把这个流程的心法写在一张图上了:
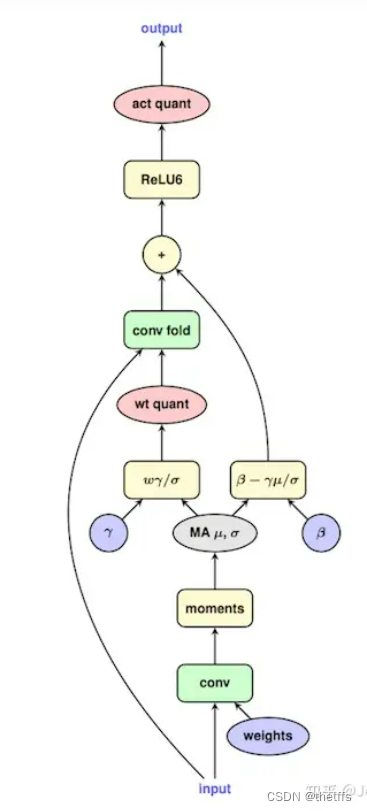
由于实际 inference 的时候,BN 是 folding 到 Conv 中的,因此在量化训练的时候也需要模拟这个操作,得到新的 weight 和 bias,并用新的 Conv 估计量化误差来回传梯度。
量化感知训练后期再做详细的解读和补充。
Conv和ReLU合并
在量化中,Conv + ReLU这样的结构一般也是合并成一个Conv进行运算的,而这一点在全精度模型中则办不到。?
之前的文章中有介绍过,ReLU前后应该使用同一个scale和 zeropoint。这是因为ReLU本身没有做任何的数学运算,只是一个截断函数,如果使用不同的scale和zeropoint,将会导致无法量化回float域。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【网络技术】【Kali Linux】Wireshark嗅探(五)文件传输协议(FTP)
- Microsoft Dynamics 365 帐户无权模拟请求的用户
- [c]统计数字
- 栈和队列相关习题
- 【python、pytorch】
- C语言例题3
- 生产问题(十四)K8S抢占CPU导致数据库链接池打爆
- HJ10 字符个数统计【C语言】
- 东华大学继续教育学院2023 秋季学期《组织行为学》考试试卷
- C++从零开始的打怪升级之路(day8)