探索栈数据结构:深入了解其实用与实现(c语言实现栈)
发布时间:2023年12月23日
上次结束了链表部分的内容:链接未来:深入理解链表数据结构(二.c语言实现带头双向循环链表)
然而,当我们涉及特定问题时,另一个非常有用的数据结构也开始显得至关重要——栈
栈与链表有着截然不同的特性,它采用一种后进先出(LIFO)的策略,这意味着最后进入栈的元素将首先被取出。这样的特性赋予了栈在特定场景下独特的价值和功能
源码可以去我的gitee:Nero的gitee
1.栈的概念和结构
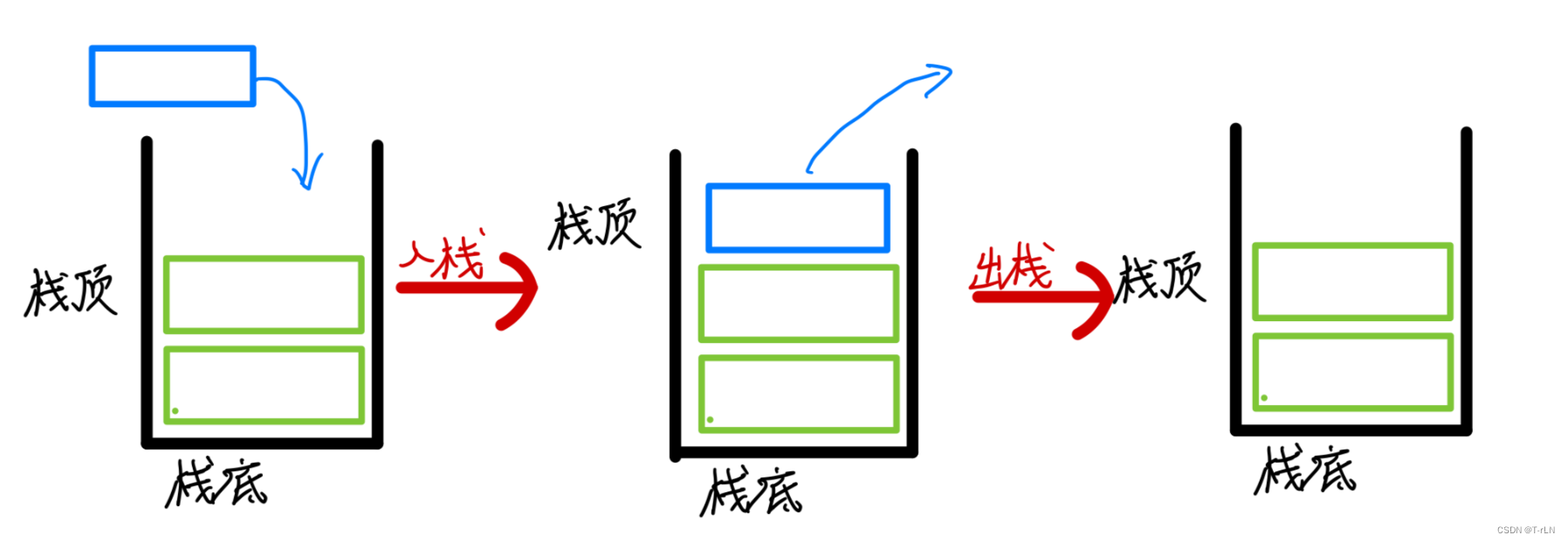
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则
压栈(push):栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶
出栈(pop):栈的删除操作叫做出栈。出数据也在栈顶
2.栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。栈只在一端进行插入和删除,选择数组尾端非常契合。
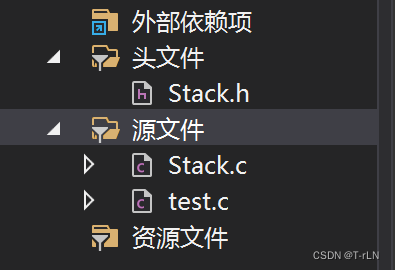
2.1项目文件规划
-
- 头文件Stack.h:用来基础准备(常量定义,typedef),链表表的基本框架,函数的声明
- 源文件Stack.h:用来各种功能函数的具体实现
- 源文件test.c:用来测试功能是否有问题,进行基本功能的使用
2.2基本结构及各功能(Stack.h)
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
typedef int STDataType;
typedef struct Stack
{
int* a;
int top; // 标识栈顶位置的
int capacity; //栈的容量
}ST;
void STInit(ST* ps);//初始化
void STDestroy(ST* ps);//销毁
void STPush(ST* ps, STDataType x);// 栈顶插入
void STPop(ST* ps);// 栈顶删除
STDataType STTop(ST* ps);//返回栈顶元素
bool STEmpty(ST* ps);//判断栈是否为空
int STSize(ST* ps);//栈中元素数量
2.3各功能具体实现
初始化
void STInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = -1;//我选择了-1
ps->capacity = 0;
}
top用来标记栈顶位置,那一开始初始化为多少合适:
- 初始化为**-1**:指向塔顶元素。因为底层用数组来实现,那第一个元素下标为0,一开始无元素为-1,有了第一个元素加上1变成0,完全符合。
- 初始化为0:指向塔顶元素的下一个位置。道理同上,但是总是比塔顶元素下标大1
插入
void STPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->capacity == ps->top + 1)//判断有没有满
{
int newCapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;
STDataType* new = (STDataType*)realloc(ps->a, sizeof(ST) * newCapacity);
assert(new);
ps->a = new;
ps->capacity = newCapacity;
}
ps->top++;
ps->a[ps->top] = x;
}
代码确保传入的栈指针
ps是有效的。然后,它检查栈是否已满。当栈满时,需要扩展栈的容量栈的
top指针增加,表示栈顶位置上移一个单位。最后,要推入栈的元素x被放入栈顶位置
ps->a[ps->top]
删除
void STPop(ST* ps)
{
assert(ps);
assert(ps->top >= 0);//确保不为空
ps->top--;
}
返回栈顶元素
STDataType STTop(ST* ps)
{
assert(ps);
assert(ps->top >= 0);
return ps->a[ps->top];
}
是否为空
bool STEmpty(ST* ps)
{
assert(ps);
return ps->top == -1;
}
元素数量
int STSize(ST* ps)
{
assert(ps);
return ps->top + 1;
}
大家一般都是:栈和队列,栈和队列,(二者放在一起)马上就到队列的知识梳理了。
感谢大家支持!!!
文章来源:https://blog.csdn.net/qq_74415153/article/details/135138528
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MyBatis-Plus提供的注解
- 锁存器触发器
- 【传奇开心果系列】Ant Design Mobile of React实现移动应用(一):从helloworld开始
- Oracle 设置 Oracle 11g 会话超时
- shall脚本
- Java中java.lang.ClassCastException异常原因及解决方法
- 【正点原子STM32连载】 第二十二章 高级定时器输出比较模式实验 摘自【正点原子】APM32E103最小系统板使用指南
- 2023年最严重的10起0Day漏洞攻击事件
- 车辆违规实线变道检测系统:融合Gold-YOLO改进YOLOv8
- Eyeshot 2024.1 即将来临--Crack-预定