2023-12-29 工作心得补充 适时抽取方法,让代码变简洁
发布时间:2023年12月29日
1 JSONObject 实际上是个map?
2 数据库实际上也是map 只不过map 是竖着写,数据库横着写.
3 像 用户名 密码 这种后续可能随时会改的,不要写死在代码里,都写成nacos参数。
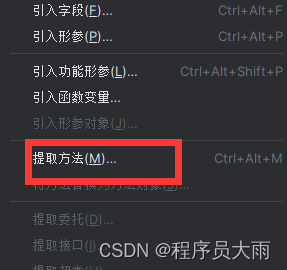
4?方法的抽取 让代码变得简洁
可读性很高。这是方法抽取的秘诀。写文章应该也可以这样,把一些抽象的东西装进黑盒,尽可能为大众留下更通俗易懂的文字。
选中代码-右键重构-提取方法-起名
5 for循环map的key,然后去另一个map匹配,如果有就取出来做后续处理,同时把它从Map里给删掉。(防止重复)
Map是可以这样做的,List不行。List如果在for循环的时候 删除里面的元素,会导致ConcurrentModificationException异常。
for (String key: map.keySet()) {
? ? ? ? ? ? Car car = null;
? ? ? ? ? ? if (map.containsKey(key)) {
? ? ? ? ? ? ? ? car = map.get(key);
? ? ? ? ? ? ? ? map.remove(key);
? ? ? ? ? ? }
}
6 如果list转map 的时候,key这样设置
?ele.getBatchId() + "_" + ele.getDate()?
那应该怎么取batchId呢?
?ele.split("_")[0]
7 按下面这样操作,就可以拿到去重后的已有日期数据。
List<String> dateCollect = reportList.stream().map(ReportStatistic::getDate).collect(Collectors.toList());
Set<String> dateSet = new HashSet<>(dateCollect);
8 擅用return。
如果有 就xx 然后直接 return 。
我之前总忘记还有return。
9 命名规范。如果是布尔值,命名最后前可以加个is。比如是否同步历史数据,可以写isSyncHistory,如果是true就是同步,如果是false,就是不同步。
如果写syncHistory,那么就容易造成混乱。
10 增量保存的奥秘。
?
Map<String, Car> oldDataMap = oldDatalist.stream().collect(Collectors.toMap(e -> e.getDate() + "-" + e.getxx() + "-" + e.getxx() , Function.identity(), (k, v) -> k));
Map<String, Car> newDataMap = newDataList.stream().collect(Collectors.toMap(e -> e.getDate() + "-" + e.getxx() + "-" + e.getxx() , Function.identity(), (k, v) -> k));
for (String key : newDataMap.keySet()) {
//如果旧数据里有新数据的key,那么就给该新数据设置旧数据的id
if(oldDataMap.containsKey(key)){
newDataMap.get(key).setId(oldDataMap.get(key).getId());
}
}
//再用JPA的SaveAll(如果id为null就新增,如果id不为null就修改,也就是增量新增)
repository.saveAll(newDataMap.values);
文章来源:https://blog.csdn.net/tomorrow9813/article/details/135290854
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- v-masonry踩坑 数据不重绘问题
- 【WinForm.NET开发】数据绑定
- 快速入门学会tomcat!
- 【mars3d】TilesetLayer支持position位置偏移的前置说明
- git提交报错:remote: Please remove the file from history and try again.
- VRRP(虚拟路由器冗余协议)
- 为什么网上很多人都不推荐新手学习C语言?
- QScrollBar滑块颜色通过setStyleSheet设置时未生效现象
- 二叉树的顺序结构,堆的实现
- 2024谷歌SEO自学基础入门