关于C#中的HashSet<T>与List<T>
发布时间:2024年01月23日
HashSet<T>
表示值的集合。这个集合的元素是无须列表,同时元素不能重复。由于这个集合基于散列值,不能通过数组下标访问。
List<T>
表示可通过索引访问的对象的强类型列表。内部是用数组保存数据,不是链表。元素可重复,是有序列表,根据调用add的时间先后进行排序。每次添加删除操作会重新排序。例如有100个元素,删除掉下标99的元素后,无法再通过下标99访问数据。
性能分析
HashSet对数据的检索效率(contains函数)比List 快。HashSet存储数据时将数据通过散列函数直接映射到地址,所有取值时可以直接取到,时间复杂度为O(1)。List检索时需要一个个的进行值比较,最多需要比较到数组末尾,时间复杂度为O(n),n为元素个数。
实例分析
public static void Test()
{
int dataCount = 10; //数据个数
int loopCount = 10000000; //循环次数
Stopwatch sw = new Stopwatch();
HashSet<int> hash = new HashSet<int>();
List<int> list = new List<int>();
list.AddRange(Enumerable.Range(0, dataCount));
//list.Select(x => hash.Add(x));
for (int i = 0; i < dataCount; i++)
{
hash.Add(i);
}
sw.Restart();
for (int i = 0; i < loopCount; i++)
{
hash.Contains(999999);
}
sw.Stop();
Console.WriteLine("HASH:" + sw.ElapsedMilliseconds);
sw.Restart();
for (int i = 0; i < loopCount; i++)
{
list.Contains(999999);
}
sw.Stop();
Console.WriteLine("LIST:" + sw.ElapsedMilliseconds);
sw.Restart();
for (int i = 0; i < loopCount; i++)
{
hash.Add(999999999);
hash.Remove(999999999);
}
sw.Stop();
Console.WriteLine("HASH:" + sw.ElapsedMilliseconds);
sw.Restart();
for (int i = 0; i < loopCount; i++)
{
list.Add(99999909);
list.Remove(99999909);
}
sw.Stop();
Console.WriteLine("LIST:" + sw.ElapsedMilliseconds);
}当数据量较小时,list的增加删除性能有优势,当数据量较大,则hashset的性能有巨大优势
数据量10

数据量50?

数据量1000

数据量10000
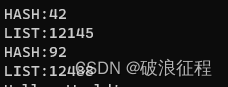
文章来源:https://blog.csdn.net/yunxiaobaobei/article/details/135778669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 7.6 yum lamp
- Linux驱动(中断、异步通知):红外对射,并在Qt StatusBus使用指示灯进行显示
- 用户密码重复使用限制策略
- Python入门知识点分享——(七)集合运算与字典类型
- 动态规划—— 求最长不下降序列LIS【集训笔记】
- 【漏洞复现】Atlassian Confluence远程代码执行漏洞(CVE-2023-22527)
- 矩阵特征值解决微分方程问题【2】
- 【网络安全 | XCTF】simple_transfer
- 网络爬虫原理:探秘数字世界的信息猎手
- 【PID学习笔记11】连续系统的数字PID