基于YOLOv4开发构建道路交通场景下CCTSDB2021交通标识检测识别系统
交通标志检测是交通标志识别系统中的一项重要任务。与其他国家的交通标志相比,中国的交通标志有其独特的特点。卷积神经网络(CNN)在计算机视觉任务中取得了突破性进展,在交通标志分类方面取得了巨大的成功。CCTSDB 数据集是由长沙理工大学的相关学者及团队制作而成的,其有交通标志样本图片有近 20000 张,共含交通标志近 40000 个,但目前只公开了其中的 10000 张图片,标注了常见的指示标志、禁令标志及警告标志三大类交通标志。随着时间的更迭有了不同的版本数据集,本文的主要目的就是想要基于yolov3来开发构建CCTSDB2021数据集上的目标检测识别系统,首先看下实例效果:

接下来看下数据集:

YOLOv4比YOLOv3多了CSP和PAN结构,YOLOv4使用CSPDarknet53作为backbone,加上SPP模块、PANet作为网络的颈部,Head部分仍采用YOLOv3的结构。
总结一下YOLOv4的基本组件,总共5个:
CBM:YOLOv4的网络结构中最小的组件,由Conv+BN+Mish激活函数组成
CBL:由Conv+Bn+Leaky_relu激活函数组成。
Res Unit:残差结构,类似ResNet
CSPX:由三个卷积层和X个Res Unit模块concate组成
SPP:采用1×1,5×5,9×9,13×13的最大池化方式,进行多模融合
Yolov4集成了当时领域内的一些Tricks如:WRC、CSP、CmBN、SAT、Mish激活、Mosaic数据增强、DropBlock和CIoU通过实验对模型的精度和速度进行了平衡.YOLOv4借鉴了CSPNet(Cross Stage Partial Networks,跨阶段局部网络)的思想,对YOLOv3的Darknet53网络进行了改进,形成了全新的主干网路结构--CSPDarknet53,CSPNet实际上是基于Densnet的思想,即首先将数据划分成Part 1和Part 2两部分,Part 2通过dense block发送副本到下一个阶段,接着将两个分支的信息在通道方向进行Concat拼接,最后再通过Transition层进一步融合。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主流的有CSPResNext50 和CSPDarknet53两种改造Backbone网络。
采用CSP结构有如下几点好处:
1.加强CNN学习能力
2.删除计算瓶颈
3.减少显存开销
SPP输入的特征层依次通过一个卷积核大小为5×5,9×9,13×13的最大池化下采样层,然后将这三个输出的特征层和原始的输入的特征层进行通道拼接。通过SPP结构能够在一定程度上解决多出尺度的问题;PAN来自于PANet(Path Aggregation Network),实际上就是在原来的FPN结构上又加上了一个从低层到高层的融合。在YOLOv4里面的特征融合采用的是concat通道拼接。
当然了还有训练策略、数据增强等其他方面的创新技术这里就不再展开了介绍了,感兴趣的话可以自行查询相关的资料即可。
如果对如何使用yolov4项目来开发构建自己的目标检测系统有疑问的可以看我前面的超详细博文教程:
《基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】》
《基于官方YOLOv4-u5【yolov5风格实现】开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】》
本文的项目开发是以第一篇教程为实例进行的,当然了如果想要使用第二篇的教程本质上也都是一样的。
self.names如下:
mandatory
prohibitory
warningself.yaml如下:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/
test: ./dataset/images/test/
# number of classes
nc: 3
# class names
names: ['mandatory', 'prohibitory', 'warning']模型训练参数配置详情如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov4-tiny.weights', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/yolov4-tiny.cfg', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()本文是基于yolov4-tiny.cfg进行模型的开发训练的,终端执行即可启动训练,日志输出如下所示:
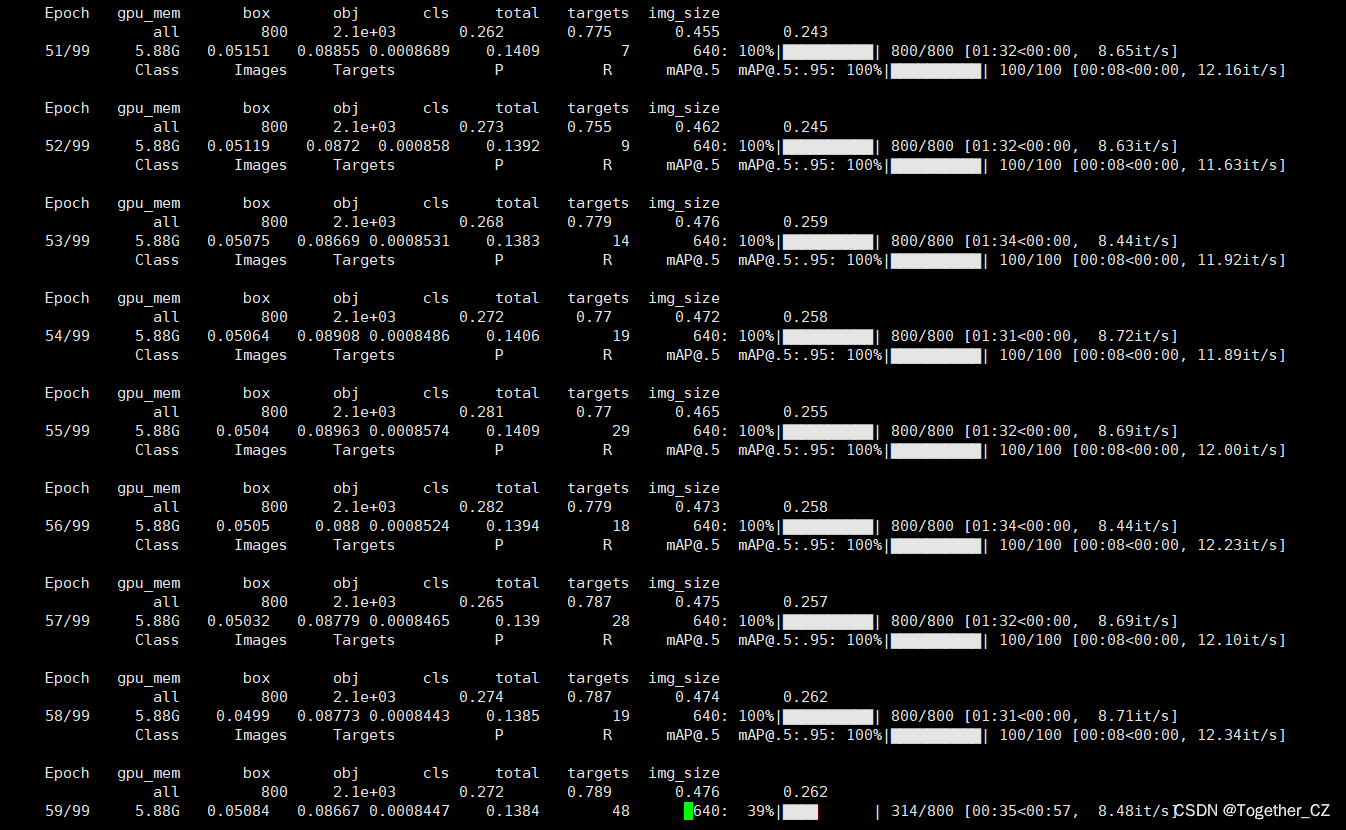
接下来看下结果详情。
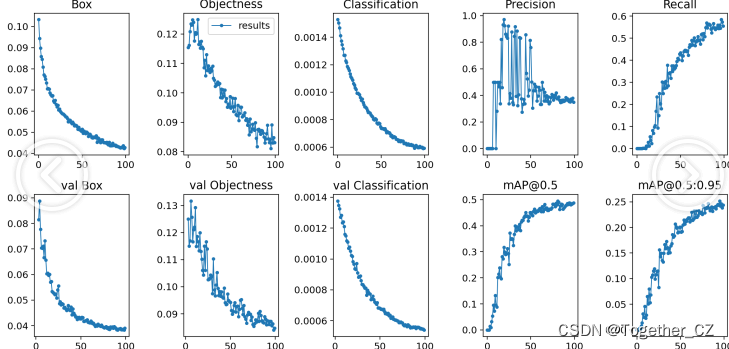
【训练可视化】
离线推理实例如下:

结果详情如下:
{"prohibitory": [[0.9419642686843872, [278, 741, 414, 815]]]}感兴趣的话也都可以动手实践下!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springboot/java/php/node/python超市综合管理系统【计算机毕设】
- 【EI会议征稿通知】第五届计算机通信与网络安全国际学术会议 (CCNS 2024)
- Python中列表和字符串的反转
- “与客户,共昂首”—昂首资本亮相2023年济南交易技术峰会,完美诠释行业标杆
- MySQL与Oracle数据库在网络安全等级方面用到的命令
- 掌握Python中析构函数、封装和私有权限的绝密技巧
- nuc980 打包烧录系统镜像文件
- 学习python仅此一篇就够了(内置模块)
- PostgreSQL16中的新增功能:双向逻辑复制
- 数据集介绍【02】CIFAR10