速通C语言第十二站 文件操作
系列文章目录
?速通C语言系列
?速通C语言第一站 一篇博客带你初识C语言? ? ? ??http://t.csdn.cn/N57xl
?速通C语言第二站 一篇博客带你搞定分支循环 ? http://t.csdn.cn/Uwn7W
?速通C语言第三站 ?一篇博客带你搞定函数 ? ? ? ?http://t.csdn.cn/bfrUM
速通C语言第四站??一篇博客带你学会数组? ? ? ? ??http://t.csdn.cn/Ol3lz
?速通C语言第五站 一篇博客带你详解操作符? ? ??http://t.csdn.cn/OOUBr
速通C语言第六站 一篇博客带你掌握指针初阶?? http://t.csdn.cn/7ykR0
速通C语言第七站 一篇博客带你掌握数据的存储 http://t.csdn.cn/qkerU
?速通C语言第八站 一篇博客带你掌握指针进阶??? http://t.csdn.cn/m95FK
?速通C语言第八.五站 指针进阶题目练习?? ? ? ? ? http://t.csdn.cn/wWC2x
速通C语言第九站? 字符相关函数及内存函数??? http://t.csdn.cn/YyBBM
?速通C语言第十站? 自定义类型????????????????????????? http://t.csdn.cn/jsGJ7
速通C语言第十一站? 动态内存开辟????????????????? http://t.csdnimg.cn/necjp
感谢佬们支持!首先祝大家元旦快乐!
文章目录
- 系列文章目录
- 前言
- 1、为什么使用文件
- 2、什么是文件
- ???????? 文件名
- 3、文件的打开和关闭
- 4、文件的顺序读写
- ?????? 流
- ?????? 一次读一个
- ?????? 一次读一行
- ?????? 格式化输入输出函数
- ?????? 二进制输入输出函数
- ?????? 综合对比
- 5、文件的随机读写
- 6、文本文件和二进制文件
- 7、文件读取结束的判定
- 8、文件缓冲区
- 总结
前言
?? 在学习之前,我家首先要知道,文件/文件系统是一个很重要的东西,而且研究文件只停留在语言层面是非常片面的。等我们学到操作系统后,才会对此有一个更深的理解.
1、为什么使用文件
比如说我们写一个通讯录,运行之后进行增删查改,但是退出程序后我们的数据就没了
要想有信息拷贝,就要把数据写到文件中。
2、什么是文件
文件分为两种,一种为数据文件,另一种为程序文件(内存文件)
程序文件分为3种 :1、我们写的.c文件
??????????????????????????????? 2、编译过程中产生的临时文件 .i ,.s .o
??????????????????????????????? 3、最后生成的可执行程序 .exe
而数据文件简单来说就是我们能从这个文件中读点数据,也能将程序中的文件写到文件中
文件名
??? 一个文件需要一个唯一的文件标识符,在我们看来是文件名(但是在操作系统看来不是)
文件名由三部分构成
?文件路径+文件名+后缀(注:在Linux系统中文件后缀没用)
例:
C:\code\test.txt
而文件的路径分为两种
一种叫绝对路径,表示从根目录一直到你当前文件的路径
例如/c/Users/86138/tDesktop/test.c?
还有一种叫相对路径,可以表示当前路径或上级路径的文件
比如test.c? ../test.c
3、文件的打开和关闭
每一个被打开的文件都在内存中用一个结构体维护,用于存放文件的部分信息(如文件存放的位置,文件的状态信息等),这个结构体被typedef为FILE
所以我们要想对这个文件做什么,就要用文件指针FILE*调用
关闭一个文件,我们用fclose函数

如果关闭成功,返回0,失败返回EOF
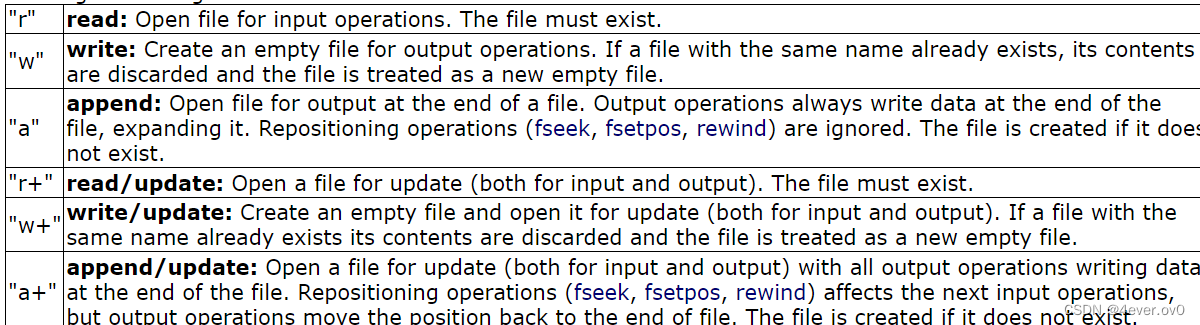
打开一个文件,我们用fopen函数

其中,第一个参数为文件的名字,第二个参数为打开文件的方式,有6种选项选择(我们重点研究前三个)
如果打开成功,返回一个文件指针,失败就返回NULL
我们写一波代码给大家看一下
我们先以 写 打开一个文件,用“w"选项,
意为,如果文件存在,会先清空再打开,如果不存在,会创建出来
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
printf("打开失败\n");
}
//写文件
//关文件
fclose(pf);
pf = NULL;运行之后打开代码所在的目录
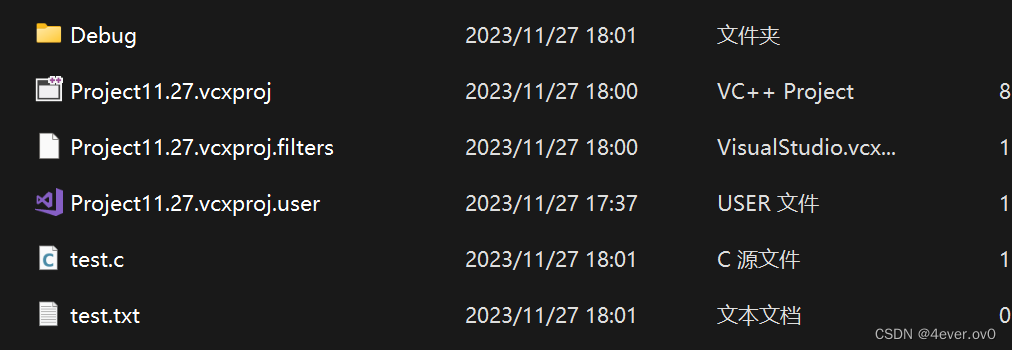
(果然多了一个test.txt)
写了之后我们在读一个文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen\n");
}读和写不同,如果没有该文件,会直接报错(使用perror函数)

4、文件的顺序读写
流
我们先来补充一个流的概念,流的概念很抽象,我们在没学操作系统之前,只能稍微理解一下
众所周知,我们储存一个程序文件有很多硬件来选择,比如屏幕(屏幕显示文件的本质也是存储),硬盘,U盘,网络
所以选择很多,不同选择的读写方式肯定不同,而在软件层面要考虑所有选择的读写方式显然太SB了,所以我们抽象一个“流”的概念出来,其类型为FILE*
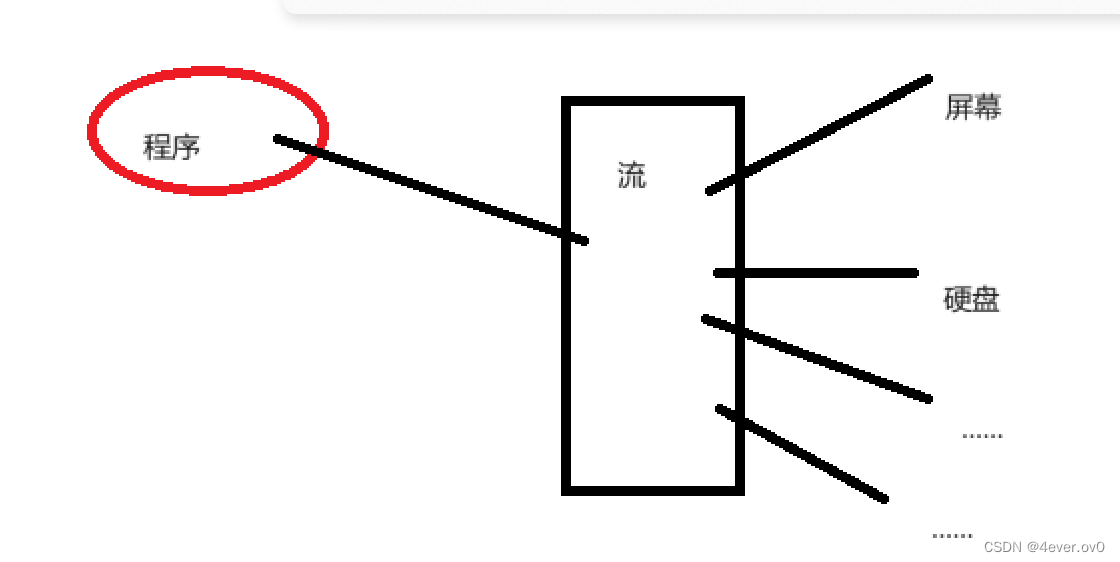
我们在写文件的时候向流中写,剩下向右边的东西怎么写是操作系统的事,他会以多态的方式实现一系列方法,这些都是以后再学的啦
另外,当C语言程序运行起来,就默认打开了3个流
0 ? stdin (标准输入流)?? 对应得硬件是键盘
1?? stdout(标准输出流)? 对应得硬件是屏幕
2?? stderr(标准输出错误流)? 对应得硬件也是屏幕
一次读一个
我们用fputc/fgetc可以从指定流中输出/输入一个数据


我们尝试向标准输出stdout(显示器)输出3个字母
fputc('z', stdout);
fputc('y', stdout);
fputc('g', stdout);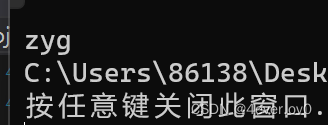
再尝试从标准输入stdin中读几个字符
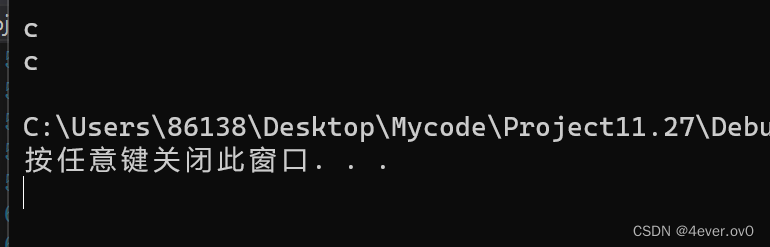
既然我们能从stdout,stdin里读写,那么文件也可以
创建一个test.txt
FILE* pf = fopen("test.txt", "w");//写
fputc('a', pf);
fputc('b', pf);
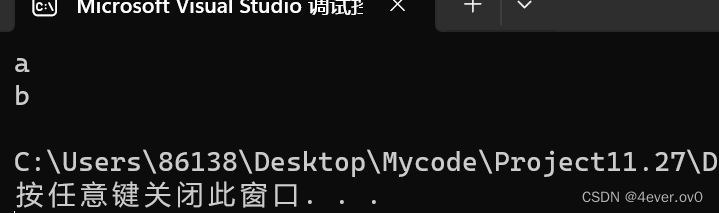
fputc('c', pf);?查看一下test.txt

?(成功)
再读
FILE* pf = fopen("test.txt", "r");
int ret = fgetc(pf);
printf("%c\n", ret);

第二次读
一次读一行
一次读写一个字符,太慢了
由此我们提供fgets读一行,fputs写一行

?
注意:num代表读取的最大个数,如果num=100,则实际读99个,因为要预留一个\0的位置
(因为无论如何这都是在语言的层面读写,就要遵守语言的规则以\0结尾)
另外,如果某一行的大小+1(\0的大小)<num,那就只读这一行,不读下一行
例:
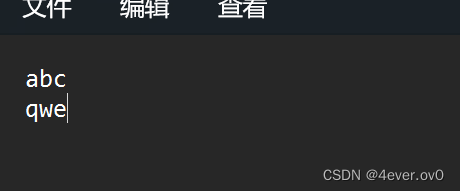
FILE* pf = fopen("test.txt", "w");
fputs("abc\n", pf);
fputs("qwe\n", pf);
fclose(pf);
pf = NULL;打开文件
读
FILE* pf = fopen("test.txt", "r");
char arr[10] = { 0 };
fgets(arr, 4, pf);
printf("%s\n", arr);
先读4个,发现只读了第一行
fgets(arr, 5, pf);
printf("%s\n", arr);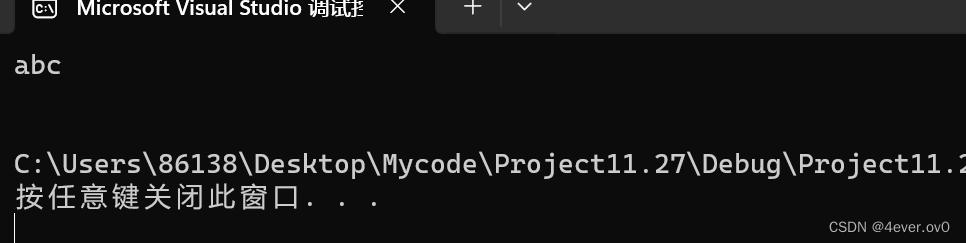
?改成读5个,他依然只读第一行
格式化输入输出函数
fprintf

fscanf

const char* format是我要输的格式,就和我们学的printf,scanf一样
例:
struct S
{
char arr[10];
int num;
float sc;
};
struct S s = { "abcdef",10,5.5};
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
}
fprintf(pf, "%s %d %f",s.arr,s.num,s.sc);

二进制输入输出函数
fread

从流中读count个size大小的数据到buffer中
fwrite

把buffer中count个size大小的数据写入buffer中
例:
struct S
{
char arr[10];
int num;
float sc;
};
struct S s = { "abcdef",10,5.5 };
FILE* pf = fopen("test.txt", "wb");//二进制写,wb
if (pf == NULL)
{
perror("fopen\n");
}
fwrite(&s, sizeof(struct S), 1, pf);
字符串从二进制写进去还是一样,但是数字不行,我们看不懂
我们看不懂,但是fread可以
struct S s = {0 };
FILE* pf = fopen("test.txt", "rb");//二进制读,rb
fread(&s, sizeof(struct S), 1, pf);
printf("%s %d %f", &s.arr, s.num, s.sc);
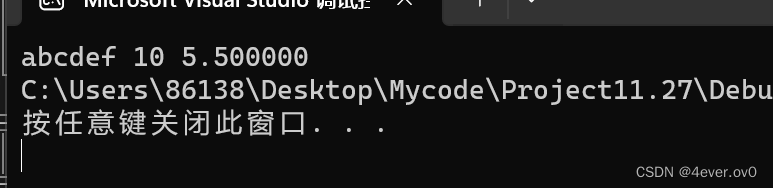
读一下
struct S
{
char arr[10];
int num;
float sc;
};
struct S s = { 0};
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
}
fscanf(pf, "%s %d %f",s.arr,&(s.num),&(s.sc));//记得加&
printf("%s %d %f", s.arr, s.num, s.sc);
综合对比
我们再补充一个sscanf和sprintf,

?从一个字符串中读取一个格式化的数据,其中,format代表格式
再加上我们熟悉的scanf和fscanf

scanf,从标准输入stdin(键盘)输入格式化的语句

针对所有输出流的格式化输入语句,其中输出流包括stdin和文件,也就是说scanf是fscanf的子集
fscanf(0,const char* format...)//等价于scanf

?把一个字符串中转换一个格式化的数据,其中,format代表格式

printf,针对标准输出stdout(显示器) 的格式化输出语句
?
?fprintf,针对所有输出流 的格式化输出语句,同上,标准输出流包括stdout和文件
fprintf(1, const char* format...)//等价于printf
5、文件的随机读写
随机读写意为想读哪读哪
之前我们学的顺序读写只能从开头往下一个一个读,有了随机读写,我们可以从任意地方开始读。

第二个参数表示偏移量
第三个参数表示起始位置,有三种选择
SEEK_CUR 当前文件指针的位置
SEEK_END 文件末,此时偏移量只能为负,即从后向前读(但是其封装的系统调用lseek中为可正可负,会对文件相应扩容,并产生文件空洞等,此处可以忽略)
SEEK_SET? 文件开始,此时偏移量只能为正,即从头开始读
我们写个代码来用一下这个函数
先将我们的test.txt中写上abcdef
FILE* pf = fopen("test.txt", "r");
int ch = fgetc(pf);
printf("%c\n", ch);//a
ch = fgetc(pf);
printf("%c\n", ch);//b
ch = fgetc(pf);
printf("%c\n", ch);//c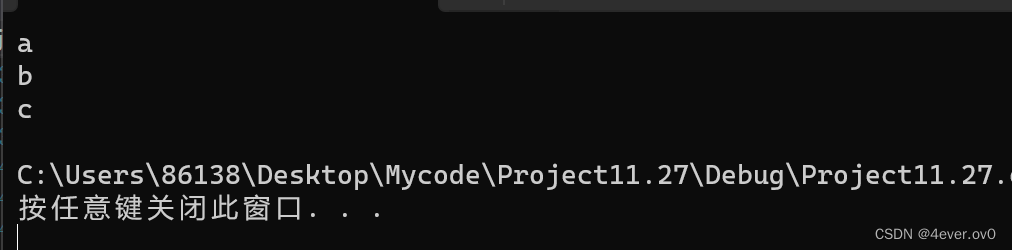
显然,再往下读就是d了,现在我们又想读b了,怎么办?调整一下文件指针,往前推两个
fseek(pf, -2, SEEK_CUR);
ch = fgetc(pf);
printf("%c\n", ch);
(又读到b了,牛逼)
与之补充的还有两个函数
ftell
可以返回我们当前文件的偏移量
例:

(我们当前读完了b,要读c,所以偏移量为2)
rewind

让文件指针的位置又回到文件开始
例:
printf("文件的偏移量为:%d\n", ftell(pf));
rewind(pf);
printf("文件的偏移量为:%d\n", ftell(pf));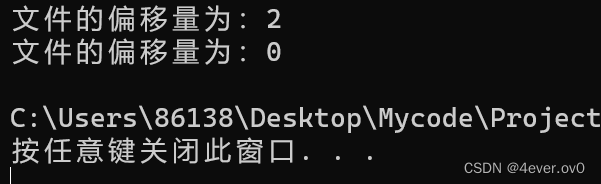
6、文本文件和二进制文件
根据数据得组织形式,数据文件被称为文本文件/二进制文件
二进制文件:数据在内存中以二进制形式储存,如果不加转换得输出到外存,就是二进制文件
文本文件:如果要求在外存上以ASCII码的形式存储,则需要在存储前转换以ASCII码的形式存储的文件就是文本文件。
对应到数据就是
字符:一律ASCII码
数值型数据:既可以ASCII码,又可以二进制
例:
给一个整数10000(int),以ASCII码存就是占5个字节,但是以二进制形式就是4个字节
7、文件读取结束的判定
feof

注意:在文件读取中,绝不能用feof的返回值来判断文件是否结束,而是应用于文件已经结束了,是读取失败结束的,还是遇到文件结尾结束的。
文件正常结束会返回一个非0的值
ferror

不为-1就是打开失败
?所以到底该怎么判断文件结束?
对于文本文件,判断返回值是否未EOF(end of file)
对于二进制,fread在读取时,返回的是实际读取完整元素的个数,如果发现读取到的完整元素的个数<指定元素的个数,这就是最后一次读取了(但实际上在系统调用read的层面,有很多情况都能导致读到的完整元素个数(ssize_t)<指定元素个数,此处我们不做考虑)。
用上面的方法得知文件结束后我们再用feof函数
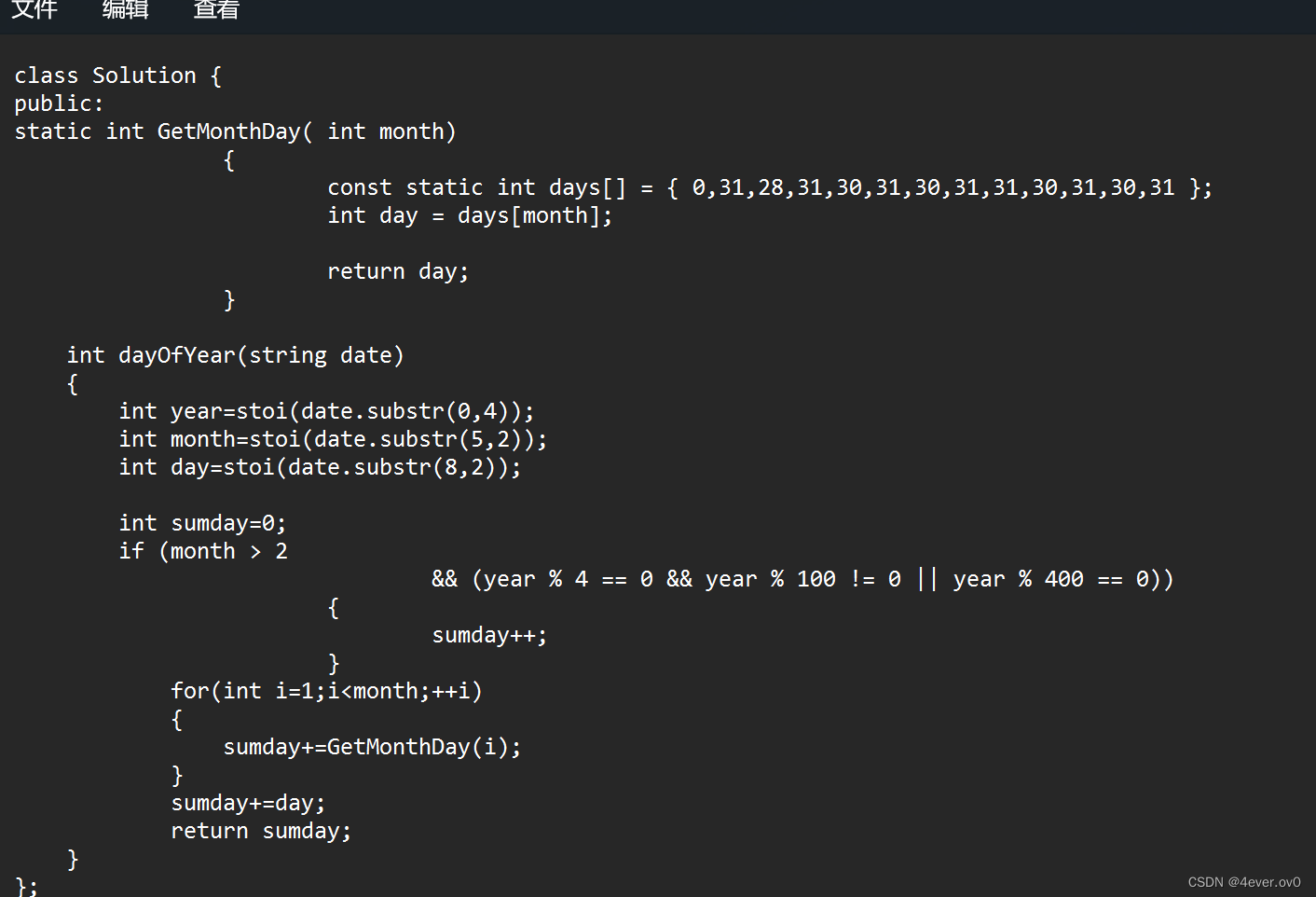
例:
假设test.txt文件中有一份代码,要求把test.txt文件拷贝一份,生成test2.txt
test.txt

int main()
{
FILE* pfread = fopen("test.txt", "r");
if (pfread == NULL)
{
perror("fopen\n");
}
//写文件
FILE* pfwrite = fopen("test2.txt", "w");
if (pfwrite == NULL)
{
//这次打开失败了说明第一次打开成功了,所以得释放第一个
fclose(pfread);
pfread = NULL;
return 1;
}
//从pfread里读,写到pfwrite里
int ch = 0;
while ((ch = fgetc(pfread)) != EOF)
{
fputc(ch, pfwrite);
}
//关文件
fclose(pfread);
pfread = NULL;
fclose(pfwrite);
pfwrite = NULL;
}
运行之后
test2果然也有了相同的代码
下来该判断文件如何结束的了
if (ferror(pfread))
puts("I/O error when reading\n");
else if (feof(pfread))
puts("EOF reach successfully\n");
(正常结束了)
8、文件缓冲区
先给到大家一张图,然后再举一个例子
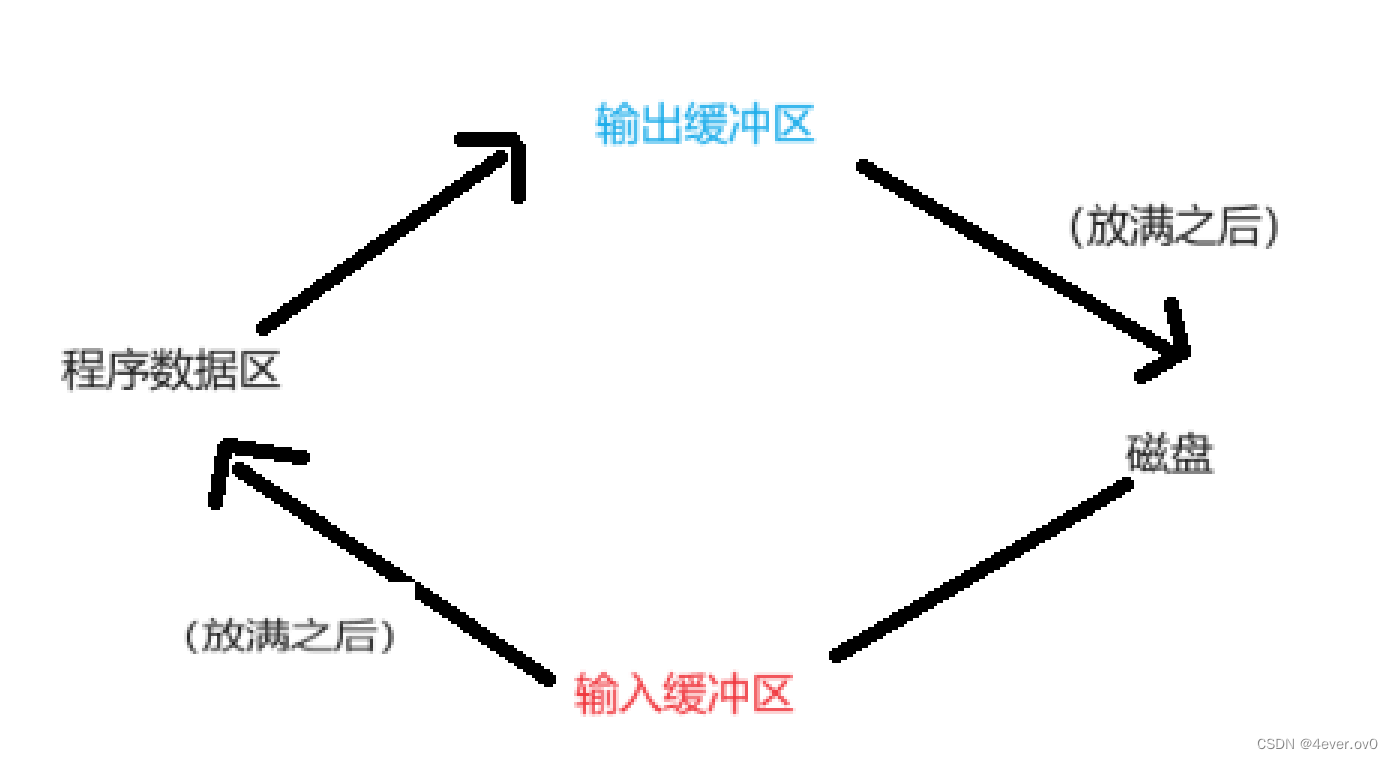
先举个现实生活中的例子
? 比如你在北京,你的朋友在济南,你想给他寄一个东西,所以你就跑到你们学校的快递站,填好信息。
?? 此时你的快递就被寄出去了吗?没有,为什么?为什么不马上寄出去?
?? 如果说你刚走了,快递被一辆车寄出去了,又有一个人来了,填的信息也是寄向济南,然后再派一辆车寄吗?这成本太高了,肯定不能这么做
?? 所以怎么办? 快递站有一个专门放寄往济南的柜子,柜子满了再寄,也就是要等一波寄往济南的快递,然后只派一辆车寄,这成本就小很多了呀
对应于计算机我们再举一个例子
比如我写数据,我想往硬盘上写,但是这数据不是你能写的,你得告诉操作系统给你写、
操作系统是很忙的,你跟操作系统说:哥们,往磁盘写个数据,操作系统停下手上的活给你写;过一会儿你又说:哥们,往磁盘写个数据……那操作系统什么都不干,刚给你写数据?
那效率太低了。这个时候就要用的缓冲区了
你往磁盘写数据,先往缓冲区上写,缓冲区满了,操作系统再一波往磁盘上写。
所以缓冲区是很有必要的
注意:这波我们学的缓冲区是C语言给我们提供的,也就是说是一个语言层的缓冲区
?总结
?做总结,还是那句话,这篇博客只能带大家对文件有一个浅显的认识,在正式学了操作系统的基础IO和文件系统,才能对这些有更深刻的认识。
水平有限,还请各位大佬指正。如果觉得对你有帮助的话,还请三连关注一波。希望大家都能拿到心仪的offer哦。

每日gitee侠:今天你交gitee了嘛
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 最流行的 Python 环境管理工具Conda
- 阿里云独享型通用算力u1云服务器怎么样?通用算力型u1实例有什么优势?
- 分享 | 顶刊高质量论文插图配色(含RGB值及16进制HEX码)(第二期)
- FPGA图形化前仿真
- 递归组件怎么实现无线滚动
- 【第一期】操作系统期末大揭秘:知识回顾与重点整理
- 根据配置动态加载三方多数据源,支持热加载
- Linux———top命令详解(狠狠爱住)
- 基于SpringBoot的社区帮扶对象管理系统
- DDR3通信协议介绍篇