Oracle-数据库性能变慢问题分析
问题背景:
????????应用运维报障说最近两天业务数据入库和表查询都变得很慢,需要排查一下数据库的性能问题
问题分析:
????????登录到服务器上,通过TOP命令快速看了一下,服务器整体的CPU使用%usr不算特别高,但%wa IO等待很高,怀疑有可能是数据库存在大量的IO操作语句导致服务器IO负载升高
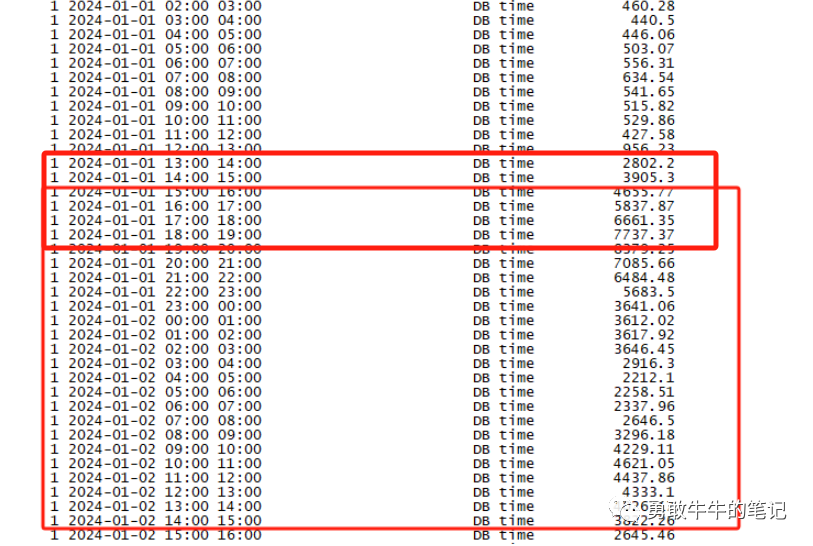
????????查询数据库的负载dbtime时间,可以看到数据库的负载明显变高,平常只有几百的dbtime值,从2024年1月1日13点左右之后开始飙升,最高达到7000+
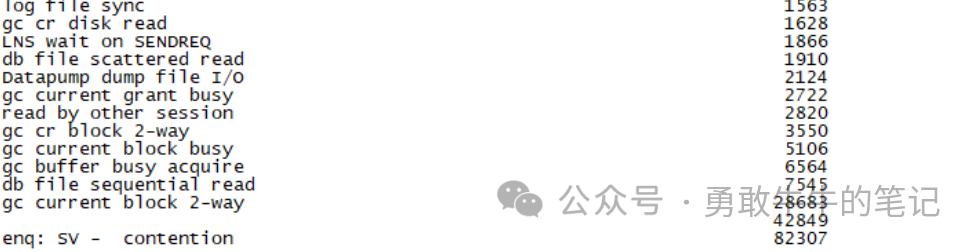
????????对比1月1日13点前后的等待事件情况,发现13点之后的IO等待事件db file sequential read以及direct path read等待事件明显多了几个数量级,等待事件的类型与看到的服务器IO等待负载升高匹配,可以确认数据库肯定存在大量的IO操作
select event,count(*)
from DBA_HIST_ACTIVE_SESS_HISTORY a
where to_char(sample_time,'yyyymmdd hh24:mi:ss')>='20240101 13:00:00'
and to_char(sample_time,'yyyymmdd hh24:mi:ss')<='20240102 16:00:00'
group by event
order by 2;????????正常时间段
?
????????性能缓慢,IO等待高时间段
?

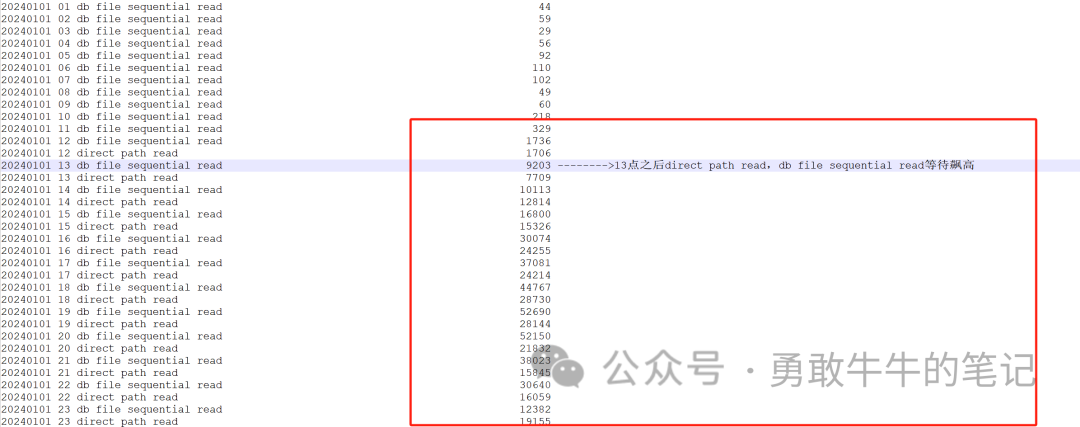
????????进一步查看IO等待事件db file sequential read以及direct path?read每小时的增长趋势,可以看到在13点之后,IO等待事件出现了显著的增长
select to_char(sample_time,'yyyymmdd hh24'),event,count(*)
from DBA_HIST_ACTIVE_SESS_HISTORY a
where event in('direct path read','db file sequential read')
group by to_char(sample_time,'yyyymmdd hh24'),event
order by 1;?
????????分析IO等待事件引发的sql语句,可以看到TOP主要有4条语句sql:8aq5bt0k6jb4d、3s559a2uc2xk0、3nd18t4tmv0mz、25dy6q436ch3k
select sql_id,count(*)
from DBA_HIST_ACTIVE_SESS_HISTORY a
where to_char(sample_time,'yyyymmdd hh24:mi:ss')>='20240101 13:00:00'
and to_char(sample_time,'yyyymmdd hh24:mi:ss')<='20240102 16:00:00'
and event in ('db file sequential read','direct path read')
having count(*)>50000
group by sql_id
order by 2;?

????????分析第一条SQL:8aq5bt0k6jb4d
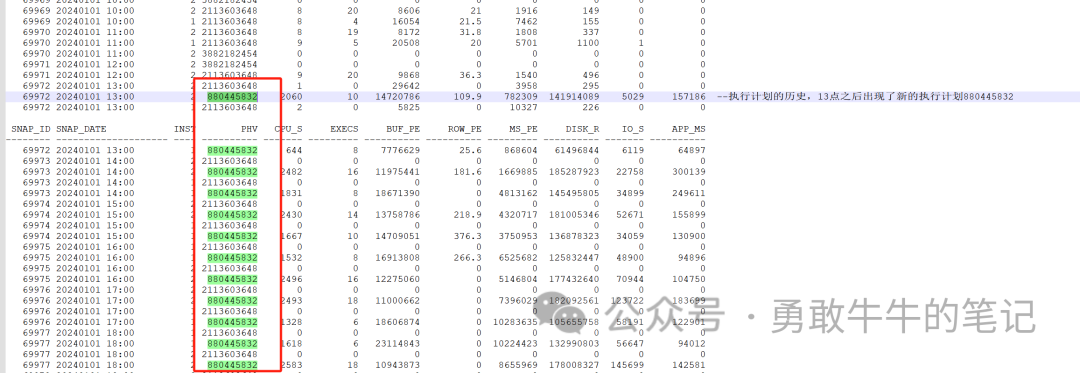
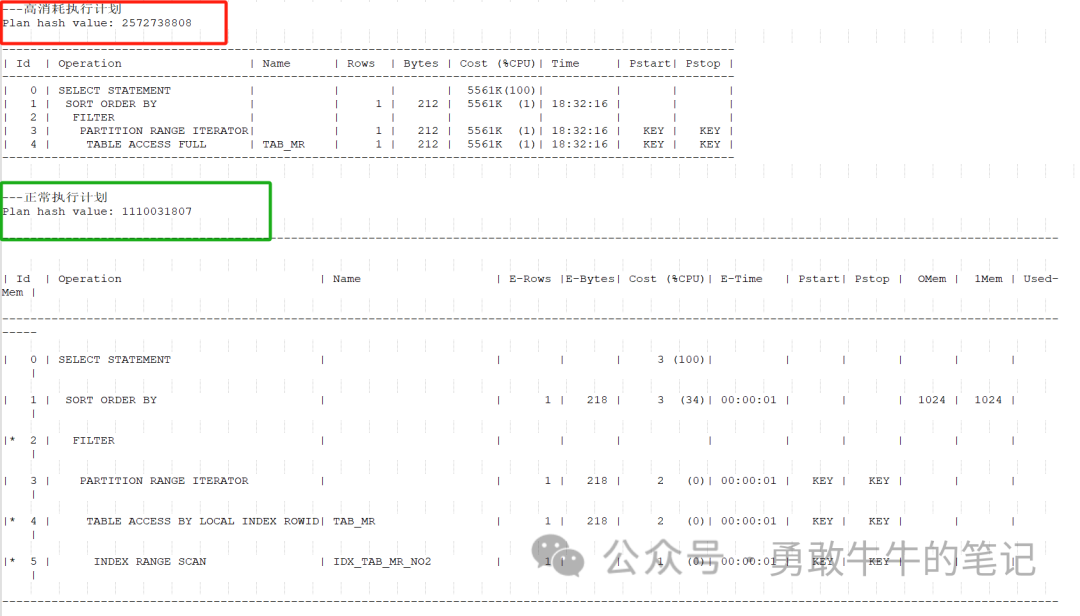
????????查看语句的执行计划,可以看到语句的执行计划发生了改变,在1月1日13点生成了一个高消耗的执行计划,执行次数628次,平均消耗时间6583秒,逻辑读和物理读次数都很高平均100W+,而正常的执行计划执行时间都在10秒以内,,物理读次数在1000次以内
????????从执行计划的生成时间与数据库负载变高时间一致以及语句的逻辑读和物理读消耗,基本可以确认数据库的性能缓慢与这个语句有关
?

????????分析语句的高消耗执行计划,语句里面唯一的大表TAB_MR,大小157628MB,作为了nested loop的驱动表,并且执行的路径是全表分区范围扫描
?

?
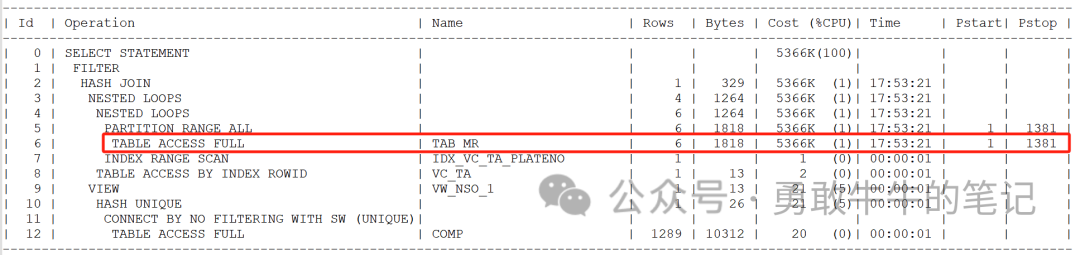
????????表TAB_MR根据时间条件t.syn_time查询数据
?

????????跟正常的执行计划对比,可以看到正常的执行计划是使用到了分区本地索引IDX_TAB_MR_SYN_TIME,而不是全表分区范围扫描
?
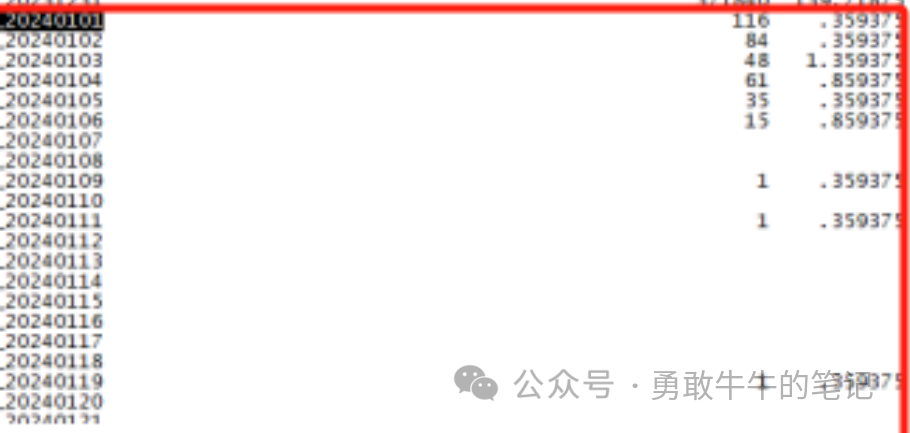
????????检查分区表以及索引的统计信息,都发现1月份之后的统计信息与实际表的数据差异很大,实际一天的分区有几十万的数据
--查看分区表的统计信息
select table_owner, table_name, partition_name, AVG_ROW_LEN ,num_rows, blocks*8/1024 size_m,last_analyzed
from dba_tab_partitions where table_name='SALES_LIST'
--查看索引的统计信息
select owner,index_name,PARTITION_NAME,SUBPARTITION_NAME,LEAF_BLOCKS,DISTINCT_KEYS,LAST_ANALYZED
from dba_ind_statistics
where table_owner='TEST' and table_name='SALES_LIST';?
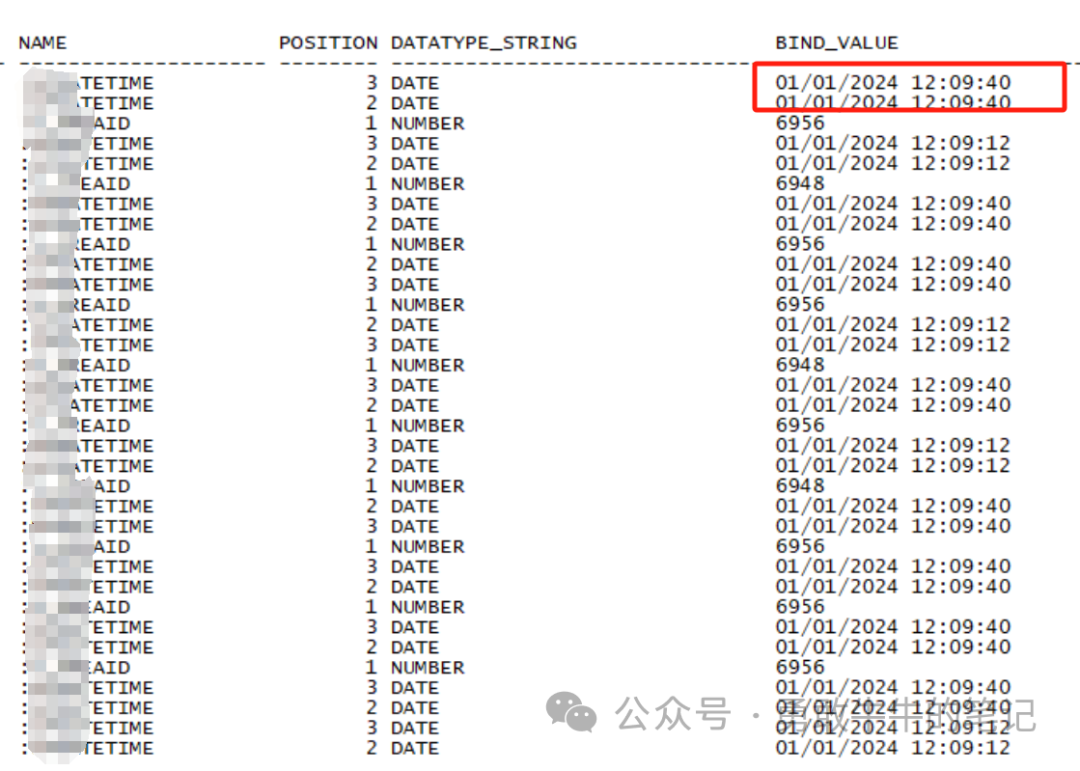
????????查看语句传入的绑定变量值,发现传入的都是查询最新1月份的数据,可以判断执行计划选错执行路径的原因为统计信息的不准确导致优化器估算出现错误,选择了全表扫描的路径
?
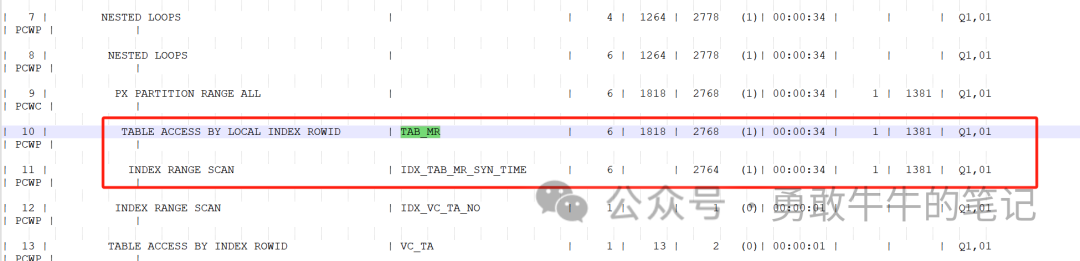
????????分析第二条SQL:3sruu5v9gtysg
????????语句是一条正常的普通insert语句,执行计划没有可以分析的,查看语句的执行消耗变化情况,可以看到在13点之后,语句的IO_WAIT等待时间变得很高,可以判断语句应该是受到系统负载IO变慢所影响的
?
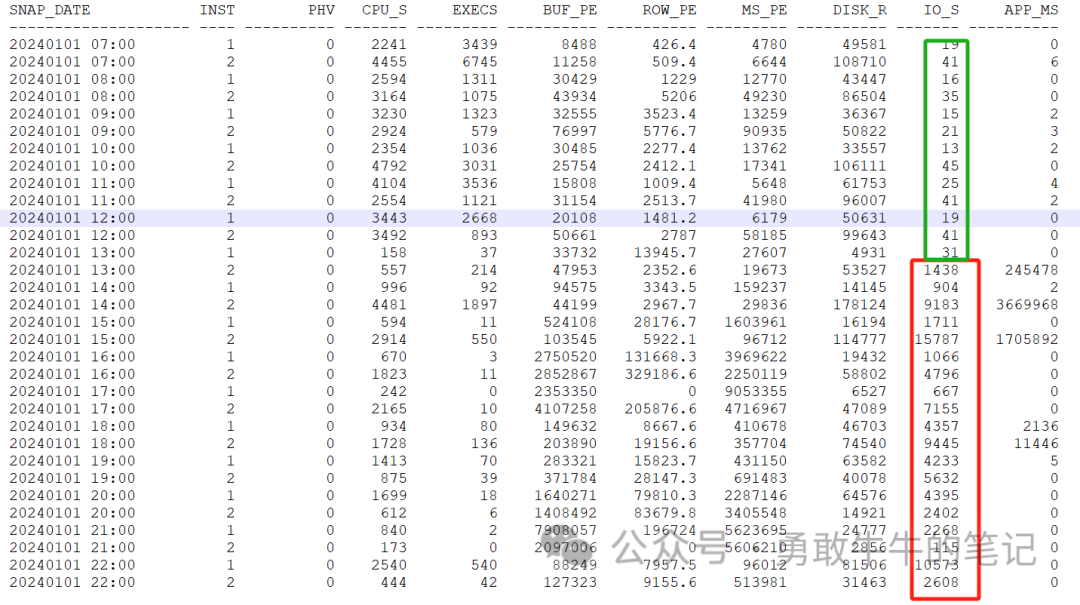
????????分析第三条SQL:3sruu5v9gtysg
????????跟第二条语句类似,在执行计划没有变化的情况下,语句的IO_WAIT等待时间变得很高,语句同样也是受到系统负载IO变慢所影响的
?
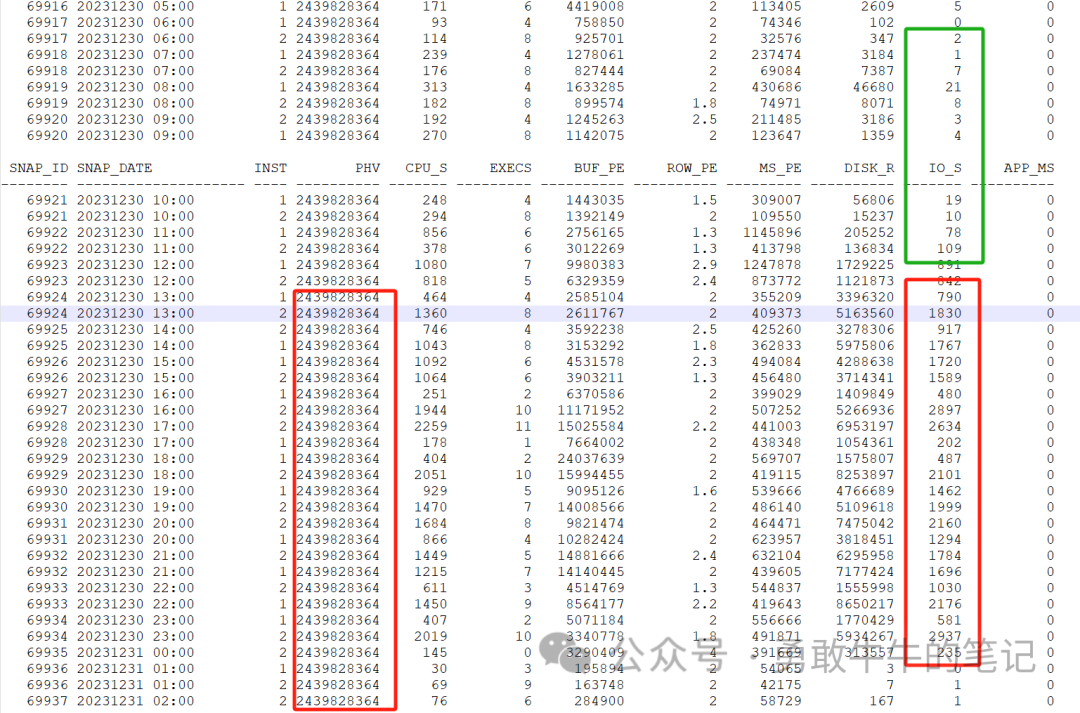
????????分析第四条SQL:3sruu5v9gtysg
????????查看语句的执行计划,可以看到语句的执行计划也发生了改变,在1月1日13点生成了一个高消耗的执行计划,执行次数7149次,平均消耗时间7.374秒,物理读和逻辑读比起正常的执行计划消耗都增长了很多,而正常的执行计划执行时间都在0.0005秒以内,平均只有10次的逻辑读

????????查看语句的执行计划,跟第一条语句是同一张表语句TAB_MR,同样的问题,优化器选错了执行的路径进行全表单分区范围扫描
????????分析完这4条TOP SQL可以对问题做个总结了,数据库从2024年1月1日13点左右负载明显升高,主要的负载为IO操作,IO操作负载升高的原因为大表TAB_MR的2024年1月份之后的分区统计信息不准确,导致涉及1月份数据的查询SQL生成了错误的高消耗全表分区扫描执行计划,产生了大量的物理读以及逻辑读,最终引发了整个数据库的性能下降,业务数据入库和表查询都变慢
问题解决:
????????对大表TAB_MR1月份的分区单独收集统计信息后,语句的执行计划恢复了正常,数据库的IO负载也降下来、
其他问题:
????????最后还有一个问题就是关于统计信息收集的,数据库是有开启默认的自动统计信息收集的,单个分区的数据变化量也超过了10%,为什么表的统计信息到1月2号还没有更新
?

?

????????查看统计信息job的执行记录,可以看到2024年1月1日的统计信息收集在晚上22点有正常的开始执行,但是最后统计信息收集的job由于4个小时的执行窗口时间已到,job被迫暂停了(REASON="Stop job called because associated window was closed"),也就是任务有跑,但没收集完成
????????注:周一到周五默认统计信息收集窗口4个小时,周六周日默认统计信息收集窗口20个小时
????????通常统计信息没有在4个小时窗口执行完成的可能原因有1 数据库要收集的表数据量过大 2 数据库的性能出现问题,导致收集缓慢 3 统计信息收集的并行度不合理,导致收集速度过慢 4 Oracle的bug,结合统计信息收集的历史完成时间都在2小时以内以及收集时间段存在IO负载高的问题,判断统计信息收集还是受到数据库的性能下降所影响
?

?
?
?
?
?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CTFshow-pwn入门-栈溢出pwn39-pwn40
- 干货分享|光伏电站施工建设方案
- 在Spring Cloud中使用Hystrix服务完成熔断降级处理
- ansible
- Windows 系统下本地单机搭建 Redis(一主二从三哨兵)
- C Primer Plus(第六版)11.13 编程练习 第8题
- Java 重写(Override)与重载(Overload)
- 葡萄酒术语“干”是什么意思呢?
- 【Jmeter、postman、python 三大主流技术如何操作数据库?】
- 金蝶云星空动态表单二开新增字段不显示问题