python深度学习—第6章(波斯美女)
第6章?深度学习用于文本和序列
6.1 处理文本数据
与其他所有神经网络一样,深度学习模型不会接收原始文本作为输入,它只能处理数值张量。 文本向量化(vectorize)是指将文本转换为数值张量的过程。它有多种实现方法。
将文本分割为单词,并将每个单词转换为一个向量。
将文本分割为字符,并将每个字符转换为一个向量。
提取单词或字符的 n-gram,并将每个 n-gram 转换为一个向量。n-gram 是多个连续单词 或字符的集合(n-gram 之间可重叠)。
将文本分解而成的单元(单词、字符或 n-gram)叫作标记(token),将文本分解成标记的过程叫作分词(tokenization)。所有文本向量化过程都是应用某种分词方案,然后将数值向量与生成的标记相关联。这些向量组合成序列张量,被输入到深度神经网络中(见图 6-1)。将向量与标记相关联的方法有很多种。
本节将介绍两种主要方法:对标记做 one-hot 编码(one-hot encoding)与标记嵌入[token embedding,通常只用于单词,叫作词嵌入(word embedding)]。
本节剩余内容将解释这些方法,并介绍如何使用这些方法,将原始文本转换为可以输入到 Keras 网络中的 Numpy 张量。

理解 n-gram 和词袋
n-gram 是从一个句子中提取的 N 个(或更少)连续单词的集合。这一概念中的“单词” 也可以替换为“字符”。
下面来看一个简单的例子。考虑句子“The cat sat on the mat.”(“猫坐在垫子上”)。它 可以被分解为以下二元语法(2-grams)的集合。
{"The", "The cat", "cat", "cat sat", "sat",
"sat on", "on", "on the", "the", "the mat", "mat"}
这个句子也可以被分解为以下三元语法(3-grams)的集合。
{"The", "The cat", "cat", "cat sat", "The cat sat",
"sat", "sat on", "on", "cat sat on", "on the", "the",
"sat on the", "the mat", "mat", "on the mat"}
这样的集合分别叫作二元语法袋(bag-of-2-grams)及三元语法袋(bag-of-3-grams)。这 里袋(bag)这一术语指的是,我们处理的是标记组成的集合,而不是一个列表或序列,即 标记没有特定的顺序。这一系列分词方法叫作词袋(bag-of-words)。
词袋是一种不保存顺序的分词方法(生成的标记组成一个集合,而不是一个序列,舍弃了句子的总体结构),因此它往往被用于浅层的语言处理模型,而不是深度学习模型。
提取 n-gram 是一种特征工程,深度学习不需要这种死板而又不稳定的方法,并将其替换为分层特征学习。本章后面将介绍的一维卷积神经网络和循环神经网络,都能够通过观察连续的单词序列或字符序列来学习单词组和字符组的数据表示,而无须明确知道这些组的存在。因此,本书不会进一步讨论 n-gram。
但一定要记住,在使用轻量级的浅层文本处理模型时(比如 logistic 回归和随机森林),n-gram 是一种功能强大、不可或缺的特征工程工具。
6.1.1 单词和字符的 one-hot 编码
one-hot 编码是将标记转换为向量的最常用、最基本的方法。在第 3 章的 IMDB 和路透社两个例子中,你已经用过这种方法(都是处理单词)。它将每个单词与一个唯一的整数索引相关联,然后将这个整数索引 i 转换为长度为 N 的二进制向量(N 是词表大小),这个向量只有第 i 个元素是 1,其余元素都为 0。
当然,也可以进行字符级的 one-hot 编码。为了让你完全理解什么是 one-hot 编码以及如何实现 one-hot 编码,代码清单 6-1 和代码清单 6-2 给出了两个简单示例,一个是单词级的 one-hot编码,另一个是字符级的 one-hot 编码。
# 代码清单 6-1 单词级的 one-hot 编码(简单示例)
import numpy as np
# 初始数据:每个样本是列表的一个元素(本例中的样本是一个句子,但也可以是一整篇文档)
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 构建数据中所有标记的索引
token_index = {}
for sample in samples:
# 利用 split 方法对样本进行分词。在实际应用中,
# 还需要从样本中去掉标点和特殊字符
for word in sample.split():
if word not in token_index:
# 为每个唯一单词指定一个唯一索引。
# 注意,没有为索引编号0指定单词
token_index[word] = len(token_index) + 1
# 对样本进行分词。只考虑每个样本前 max_length 个单词
max_length = 10
# 将结果保存在 results 中
results = np.zeros(shape=(len(samples),
max_length,
max(token_index.values()) + 1))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
index = token_index.get(word)
results[i, j, index] = 1.
print(results)
print(samples)# 代码清单 6-2 字符级的 one-hot 编码(简单示例)
import string
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 所有可打印的 ASCII 字符
characters = string.printable
token_index = dict(zip(range(1, len(characters) + 1), characters))
max_length = 50
results = np.zeros((len(samples), max_length, max(token_index.keys()) + 1))
for i, sample in enumerate(samples):
for j, character in enumerate(sample):
index = token_index.get(character)
results[i, j, index] = 1.
print(characters)
print(token_index)
print(results)注意,Keras 的内置函数可以对原始文本数据进行单词级或字符级的 one-hot 编码。你应该使用这些函数,因为它们实现了许多重要的特性,比如从字符串中去除特殊字符、只考虑数据集中前 N 个最常见的单词(这是一种常用的限制,以避免处理非常大的输入向量空间)。
# 代码清单 6-3 用 Keras 实现单词级的 one-hot 编码
from keras.preprocessing.text import Tokenizer
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 创建一个分词器(tokenizer),设置为只考虑前 1000 个最常见的单词
tokenizer = Tokenizer(num_words=1000)
# 构建单词索引
tokenizer.fit_on_texts(samples)
# 将字符串转换为整数索引组成的列表
sequences = tokenizer.texts_to_sequences(samples)
# 也可以直接得到 one-hot 二进制表示。
# 这个分词器也支持除 one-hot 编码外的其他向量化模式
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
# 找回单词索引
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
print('word_index:', word_index)
print('tokenizer = ', tokenizer)
print('one_hot_results:', one_hot_results)
one-hot 编码的一种变体是所谓的 one-hot 散列技巧(one-hot hashing trick),如果词表中唯 一标记的数量太大而无法直接处理,就可以使用这种技巧。这种方法没有为每个单词显式分配 一个索引并将这些索引保存在一个字典中,而是将单词散列编码为固定长度的向量,通常用一 个非常简单的散列函数来实现。这种方法的主要优点在于,它避免了维护一个显式的单词索引, 从而节省内存并允许数据的在线编码(在读取完所有数据之前,你就可以立刻生成标记向量)。 这种方法有一个缺点,就是可能会出现散列冲突(hash collision),即两个不同的单词可能具有相同的散列值,随后任何机器学习模型观察这些散列值,都无法区分它们所对应的单词。如果散列空间的维度远大于需要散列的唯一标记的个数,散列冲突的可能性会减小。
# 代码清单 6-4 使用散列技巧的单词级的 one-hot 编码(简单示例)
import numpy as np
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 将单词保存为长度为 1000 的向量。如果单词数量接近 1000 个(或更多),
# 那么会遇到很多散列冲突,这会降低这种编码方法的准确性
dimensionality = 1000
max_length = 10
results = np.zeros((len(samples), max_length, dimensionality))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
# 将单词散列为 0~1000 范围内的一个随机整数索引
index = abs(hash(word)) % dimensionality
results[i, j, index] = 1.
print('i, j, index:', i, j, index)
print('results:', results)
6.1.2 使用词嵌入
将单词与向量相关联还有另一种常用的强大方法,就是使用密集的词向量(word vector),也叫词嵌入(word embedding)。one-hot 编码得到的向量是二进制的、稀疏的(绝大部分元素都 是 0)、维度很高的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点数向量(即密集向量,与稀疏向量相对),参见图 6-2。与 one-hot 编码得到的词向量不同,词嵌入是从数据中学习得到的。常见的词向量维度是 256、512 或 1024(处理非常大的词表时)。与此相对,one-hot 编码的词向量维度通常为 20 000 或更高(对应包含 20 000 个标记的词表)。因此,词向量可以将更多的信息塞入更低的维度中。

获取词嵌入有两种方法。
在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始
是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
在不同于待解决问题的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些
词嵌入叫作预训练词嵌入(pretrained word embedding)。
我们来分别看一下这两种方法。
1. 利用 Embedding 层学习词嵌入
要将一个词与一个密集向量相关联,最简单的方法就是随机选择向量。这种方法的问题在于, 得到的嵌入空间没有任何结构。例如,accurate 和 exact 两个词的嵌入可能完全不同,尽管它们在大多数句子里都是可以互换的 a。深度神经网络很难对这种杂乱的、非结构化的嵌入空间进行学习。
说得更抽象一点,词向量之间的几何关系应该表示这些词之间的语义关系。词嵌入的作用应该是将人类的语言映射到几何空间中。例如,在一个合理的嵌入空间中,同义词应该被嵌入到相似的词向量中,一般来说,任意两个词向量之间的几何距离(比如 L2 距离)应该和这两个词的语义距离有关(表示不同事物的词被嵌入到相隔很远的点,而相关的词则更加靠近)。除了距离,你可能还希望嵌入空间中的特定方向也是有意义的。为了更清楚地说明这一点,我们来看一个具体示例。
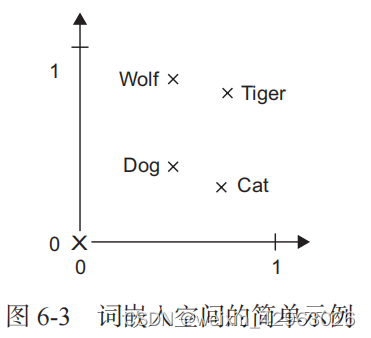
在图 6-3 中,四个词被嵌入在二维平面上,这四个词分别是 cat(猫)、dog(狗)、wolf(狼)
和 tiger(虎)。对于我们这里选择的向量表示,这些词之间的某些语义关系可以被编码为几何
变换。例如,从 cat 到 tiger 的向量与从 dog 到 wolf 的向量相等,这个向量可以被解释为“从宠
物到野生动物”向量。同样,从 dog 到 cat 的向量与从 wolf 到 tiger 的向量也相等,它可以被解
释为“从犬科到猫科”向量。
在真实的词嵌入空间中,常见的有意义的几何变换的例子包括“性别”向量和“复数”向量。例如,将 king(国王)向量加上 female(女性)向量,得到的是 queen(女王)向量。将 king(国王)向量加上 plural(复数)向量,得到的是 kings 向量。词嵌入空间通常具有几千个这种可解释的、 并且可能很有用的向量。
有没有一个理想的词嵌入空间,可以完美地映射人类语言,并可用于所有自然语言处理任务?可能有,但我们尚未发现。此外,也不存在人类语言(human language)这种东西。世界上有许多种不同的语言,而且它们不是同构的,因为语言是特定文化和特定环境的反射。但从更实际的角度来说,一个好的词嵌入空间在很大程度上取决于你的任务。英语电影评论情感分析模型的完美词嵌入空间,可能不同于英语法律文档分类模型的完美词嵌入空间,因为某些语义关系的重要性因任务而异。
因此,合理的做法是对每个新任务都学习一个新的嵌入空间。幸运的是,反向传播让这种学习变得很简单,而 Keras 使其变得更简单。我们要做的就是学习一个层的权重,这个层就是Embedding 层。
# 代码清单 6-5 将一个 Embedding 层实例化
from keras.layers import Embedding
# Embedding 层至少需要两个参数:
# 标记的个数(这里是 1000,即最大单词索引 +1)和嵌入的维度(这里是 64)
embedding_layer = Embedding(1000, 64)最好将 Embedding 层理解为一个字典,将整数索引(表示特定单词)映射为密集向量。它接收整数作为输入,并在内部字典中查找这些整数,然后返回相关联的向量。Embedding 层实际上是一种字典查找(见图 6-4)。

Embedding 层的输入是一个二维整数张量,其形状为 (samples, sequence_length),每个元素是一个整数序列。它能够嵌入长度可变的序列,例如,对于前一个例子中的Embedding 层,你可以输入形状为 (32, 10)(32 个长度为 10 的序列组成的批量)或 (64,15)(64 个长度为 15 的序列组成的批量)的批量。不过一批数据中的所有序列必须具有相同的长度(因为需要将它们打包成一个张量),所以较短的序列应该用 0 填充,较长的序列应该被截断。
这 个 Embedding 层返回一个形状为 (samples, sequence_length, embedding_dimensionality) 的三维浮点数张量。然后可以用 RNN 层或一维卷积层来处理这个三维张量(二者都会在后面介绍)。
将一个 Embedding 层实例化时,它的权重(即标记向量的内部字典)最开始是随机的,与其他层一样。在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构以便下游模型可以利用。一旦训练完成,嵌入空间将会展示大量结构,这种结构专门针对训练模型所要解决的问题。
我们将这个想法应用于你熟悉的 IMDB 电影评论情感预测任务。首先,我们需要快速准备数据。将电影评论限制为前 10 000 个最常见的单词(第一次处理这个数据集时就是这么做的),然后将评论长度限制为只有 20 个单词。对于这 10 000 个单词,网络将对每个词都学习一个 8维嵌入,将输入的整数序列(二维整数张量)转换为嵌入序列(三维浮点数张量),然后将这个张量展平为二维,最后在上面训练一个 Dense 层用于分类。
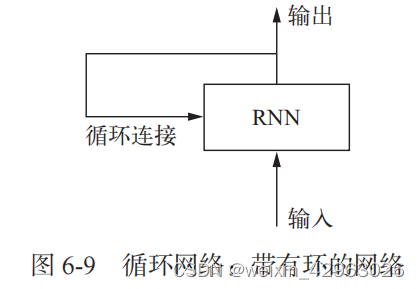
6.2 理解循环神经网络

state_t = 0 # t 时刻的状态
for input_t in input_sequence: # 对序列元素进行遍历
output_t = f(input_t, state_t)
state_t = output_t # 前一次的输出变成下一次迭代的状态state_t = 0
for input_t in input_sequence:
output_t = activation(dot(W, input_t) + dot(U, state_t) + b)
state_t = output_t# 代码清单6 - 21 简单RNN的Numpy实现
import numpy as np
timesteps = 100 # 输入序列的时间步数
input_features = 32 # 输入特征空间的维度
output_features = 64
inputs = np.random.random((timesteps, input_features)) # 输入数据:随机噪声
state_t = np.zeros((output_features,)) # 初始状态:全零向量
# 创建随机的权重矩阵
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features))
b = np.random.random((output_features,))
successive_outputs = []
# input_t 是形状为 (input_features,) 的向量
for input_t in inputs:
# 由输入和当前状态(前一个输出)计算得到当前输出
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
# 将这个输出保存到一个列表中
successive_outputs.append(output_t)
# 更新网络的状态,用于下一个时间步
state_t = output_t
# 最终输出是一个形状为 (timesteps, output_features) 的二维张量
final_output_sequence = np.stack(successive_outputs, axis=0)

6.2.1 Keras 中的循环层
from keras.layers import SimpleRNN二者有一点小小的区别:SimpleRNN 层能够像其他 Keras 层一样处理序列批量,而不是像 Numpy 示例那样只能处理单个序列。因此,它接收形状为 (batch_size, timesteps, input_features) 的输入,而不是 (timesteps, input_features)。
与 Keras 中的所有循环层一样,SimpleRNN 可以在两种不同的模式下运行:一种是返回每个时间步连续输出的完整序列,即形状为 (batch_size, timesteps, output_features) 的三维张量;另一种是只返回每个输入序列的最终输出,即形状为 (batch_size, output_ features) 的二维张量。这两种模式由 return_sequences 这个构造函数参数来控制。
我们来看一个使用 SimpleRNN 的例子,它只返回最后一个时间步的输出。
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 320000
simple_rnn (SimpleRNN) (None, 32) 2080
=================================================================
Total params: 322080 (1.23 MB)
Trainable params: 322080 (1.23 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 320000
simple_rnn (SimpleRNN) (None, None, 32) 2080
=================================================================
Total params: 322080 (1.23 MB)
Trainable params: 322080 (1.23 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32)) # 最后一层仅返回最终输出
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 320000
simple_rnn (SimpleRNN) (None, None, 32) 2080
simple_rnn_1 (SimpleRNN) (None, None, 32) 2080
simple_rnn_2 (SimpleRNN) (None, None, 32) 2080
simple_rnn_3 (SimpleRNN) (None, 32) 2080
=================================================================
Total params: 328320 (1.25 MB)
Trainable params: 328320 (1.25 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
# 代码清单 6-22 准备 IMDB 数据
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
max_features = 10000 # 作为特征的单词个数
# 在这么多单词之后截断文本这些单词都属于前 max_features 个最常见的单词)
maxlen = 500
batch_size = 32
print('Loading data...')
(input_train, y_train), (input_test, y_test) = imdb.load_data(
num_words=max_features)
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
# 代码清单 6-23 用 Embedding 层和 SimpleRNN 层来训练模型
from keras.layers import Dense
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
# 代码清单 6-24 绘制结果
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Loading data...
25000 train sequences
25000 test sequences
Pad sequences (samples x time)
input_train shape: (25000, 500)
input_test shape: (25000, 500)Epoch 1/10
157/157 [==============================] - 8s 48ms/step - loss: 0.6466 - acc: 0.6136 - val_loss: 0.4759 - val_acc: 0.8000
Epoch 2/10
157/157 [==============================] - 7s 46ms/step - loss: 0.4151 - acc: 0.8213 - val_loss: 0.4254 - val_acc: 0.8124
Epoch 3/10
157/157 [==============================] - 7s 45ms/step - loss: 0.3148 - acc: 0.8730 - val_loss: 0.5115 - val_acc: 0.7604
Epoch 4/10
157/157 [==============================] - 7s 46ms/step - loss: 0.2763 - acc: 0.8895 - val_loss: 0.4706 - val_acc: 0.8036
Epoch 5/10
157/157 [==============================] - 7s 46ms/step - loss: 0.2236 - acc: 0.9134 - val_loss: 0.3849 - val_acc: 0.8516
Epoch 6/10
157/157 [==============================] - 7s 46ms/step - loss: 0.2024 - acc: 0.9230 - val_loss: 0.4644 - val_acc: 0.8540
Epoch 7/10
157/157 [==============================] - 7s 46ms/step - loss: 0.1333 - acc: 0.9517 - val_loss: 0.4882 - val_acc: 0.8186
Epoch 8/10
157/157 [==============================] - 7s 46ms/step - loss: 0.0948 - acc: 0.9681 - val_loss: 0.5769 - val_acc: 0.7646
Epoch 9/10
157/157 [==============================] - 7s 47ms/step - loss: 0.0703 - acc: 0.9773 - val_loss: 0.6042 - val_acc: 0.7848
Epoch 10/10
157/157 [==============================] - 8s 48ms/step - loss: 0.0427 - acc: 0.9875 - val_loss: 0.7803 - val_acc: 0.7618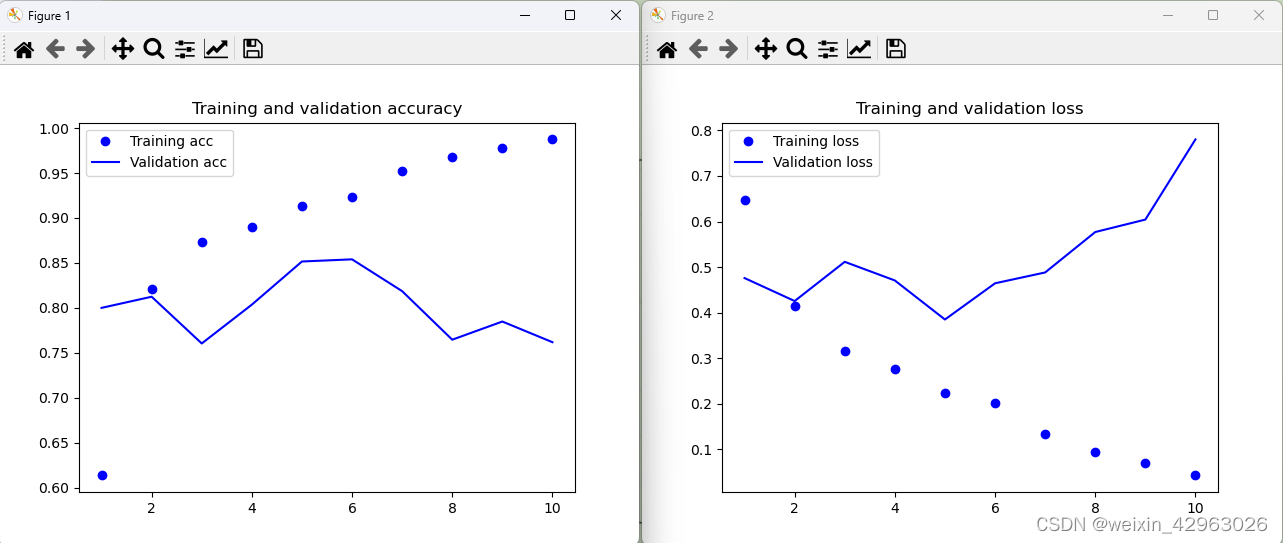
6.2.2 理解 LSTM 层和 GRU 层


y = activation(dot(state_t, U) + dot(input_t, W) + b)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【unity知识点】实现延迟调用——InvokeRepeating Invoke CancelInvoke Coroutine使用介绍
- 用户管理第2节课 -- idea 2023.2 创建表--鱼皮
- 微信Windows版如何从旧电脑迁移聊天记录到新电脑
- 算法题中常用数学概念、公式、方法汇总(其四:组合学)
- 没有自动化测试项目经验,3个项目帮你走入软测职场!
- 写给不耐烦程序员的 JavaScript 指南(五)
- 搭建自托管密码管理器
- Linux中关于tail命令详解
- 【解刊】Elsevier旗下,1区CCF-B,超快审稿:2个月22天录用!
- GeoTrust证书的申请流程和安装说明