昇思MindSpore技术公开课——第三课:GPT
1、学习总结
1.1Unsupervised Language Modelling
GPT代表“生成预训练”(Generative Pre-trained Transformer)。GPT模型是由OpenAI公司开发的一种基于Transformer架构的人工智能语言模型。它在大规模文本数据上进行预训练,学习了丰富的语言知识和语境,并能够执行多种自然语言处理任务。
GPT模型的核心思想是在大规模语料库上进行预训练,使其具备对语言的理解和生成能力。它采用Transformer架构,该架构利用自注意力机制来处理输入序列,使得模型能够捕捉长距离依赖关系。GPT的预训练包括自监督学习,其中模型尝试预测给定上下文中缺失的词语,从而学习语言的结构和语法。
动机
GPT 模型的动机来源于 未标注的文本数据远多于已标注的文本数据,并且对于不同的下游任务会存在不同的标注方式。
已有方法
semi-supervised learning
半监督学习(Semi-Supervised Learning)是一种机器学习范式,介于监督学习和无监督学习之间。在半监督学习中,训练数据集包含一部分带有标签的样本(有监督的数据)和一部分没有标签的样本(无监督的数据)。该方法旨在利用有限的标签样本和大量未标签样本来提高模型的性能。GPT1主要使用以下方法训练:
- 基于大量未标注的文本数据,训练预训练语言模型
- 使用已标注文本数据,对模型针对某一特定下游任务进行finetune,只更改output layer(线性层)
但是半监督学习面临以下问题:
- 自然语言处理的下游任务非常多元,难以有统一的优化目标。
- 难以将预训练模型的信息完全传递到finetune的下游任务中。
所以提出了非监督学习预训练模型,模型结构如下:
由于训练objective的选择,gpt在模型选择上不应该看见当前token后的信息,故模型应设计为单向网络,即transformer中的decoder结构。

2、学习心得
Supervised Fine-Tuning
Supervised Fine-Tuning(有监督微调)是一种机器学习中的训练策略,通常用于对预训练模型进行进一步调整以适应特定任务。这方法主要应用在迁移学习的背景下,其中模型首先在一个大规模的任务上进行了预训练,然后通过微调在特定任务上进行优化。
在已经预训练好的GPT上额外加一层线性层

并通过缩小目标与计算结果的误差进行模型优化

最终为加速模型收敛及提高模型的泛化性,融入pretrain时language modelling的优化目标

心得:
在GPT课程的学习过程中,我对自然语言处理和大模型的工作原理有了更全面的认识。通过深入学习GPT模型,我理解了预训练和微调的重要性,以及如何利用大规模文本数据让模型学到通用的语言表示。课程中的实践项目——使用GPT Finetune 完成一个Task,使用IMDb数据集,通过finetune GPT进行情感分类任务。加深了对模型训练和调整的实际操作经验。
总的来说,GPT这一节课程的学习让我受益匪浅。不仅拓展了对人工智能和大模型的理解,还提升了在实际项目中应用这些知识的能力。这门课程为我未来在人工智能领域的发展奠定了坚实的基础,激发了我对这一领域的兴趣和探索欲望。
3、经验分享
使用GPT Finetune 完成一个Task
在模型finetune中,需要根据不同的下游任务来处理输入,主要的下游任务可分为以下四类:
- 分类(Classification):给定一个输入文本,将其分为若干类别中的一类,如情感分类、新闻分类等;
- 蕴含(Entailment):给定两个输入文本,判断它们之间是否存在蕴含关系(即一个文本是否可以从另一个文本中推断出来);
- 相似度(Similarity):给定两个输入文本,计算它们之间的相似度得分;
- 多项选择题(Multiple choice):给定一个问题和若干个答案选项,选择最佳的答案。

本次实践使用IMDb数据集,通过finetune GPT进行情感分类任务。
4、课程反馈
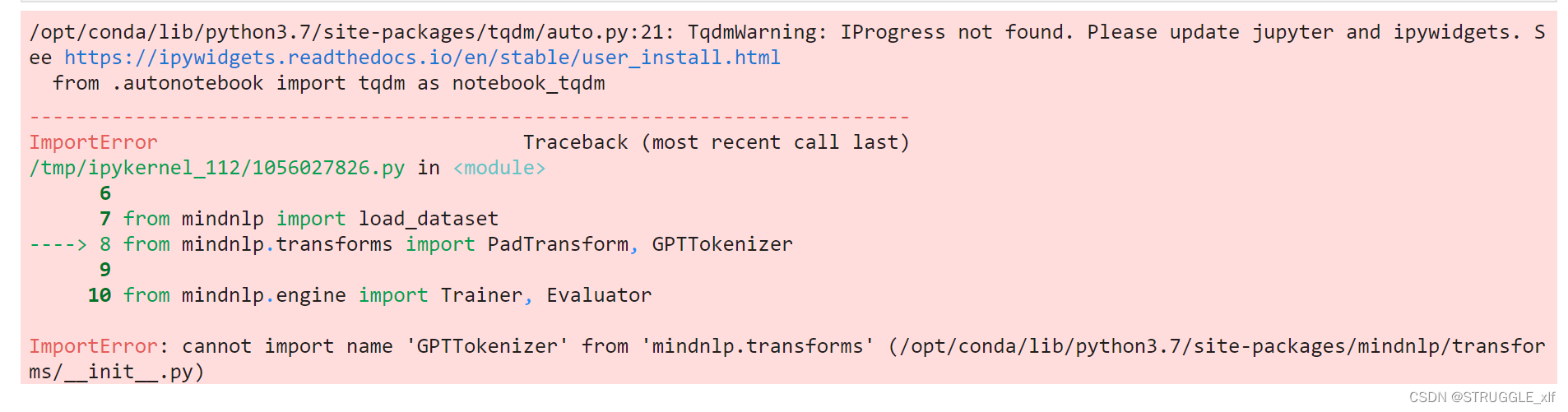
在学习GPT课程的时候,跟着课程内容实践代码课程,导入mindnlp库的时候报错,具体是运行以下代码的时候:
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn
from mindnlp import load_dataset
from mindnlp.transforms import PadTransform, GPTTokenizer
from mindnlp.engine import Trainer, Evaluator
from mindnlp.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp.metrics import Accuracy
报错:
ImportError: cannot import name 'Truncate' from 'mindspore.dataset.text' (/home/ma-user/anaconda3/envs/MindSpore/lib/python3.7/site-packages/mindspore/dataset/text/__init__.py)
我在启智社区创建的调试环境,镜像是
mindspore_2.0.0_notebook,使用pip 命令下载了mindnlp,但还是报错。
报错二:ImportError: cannot import name ‘GPTTokenizer’ from ‘mindnlp.transforms’ (/opt/conda/lib/python3.7/site-packages/mindnlp/transforms/init.py)
暂时还没有解决办法。
安装mindnlp时报错:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
transformers 4.35.0 requires tokenizers<0.15,>=0.14, but you have tokenizers 0.15.0 which is incompatible.
解决办法:
降低tokenizers版本:
pip install tokenizers==0.14.0
希望技术公开课的实验部分可以写清楚需要的环境和MindSpore版本是什么,以及跑通代码所需的依赖。
5、使用MindSpore昇思的体验和反馈
在学习MindSpore技术公开课的时候,我喜欢MindSpore昇思的设计理念,特别是其支持全场景、全流程AI开发的灵活性。其采用了图模型的思想,使得模型构建更直观,易于理解。同时,MindSpore昇思提供了丰富的工具和功能,如自动微分、模型并行训练等,使得深度学习任务的实现更加便捷和高效。然后MindSpore的安装命令也非常简洁,在启智社区还有对应的MindSpore镜像版本可以使用,非常方便学习。
6、未来展望
通过深入学习大模型的可成——GPT的原理和应用,我在自然语言处理和文本生成领域的理解更加深刻。掌握了预训练和微调等关键技术,我能够更有效地利用大规模数据训练模型,提高在特定任务上的性能。
在科研方面,课程使我更加了解人工智能领域的最新进展,尤其是大型预训练模型在语言理解、生成和其他复杂任务上取得的显著成果。这启发了我在未来研究方向的选择,促使我更深入地探索和应用先进的深度学习技术。
基于课程学到的知识,我对人工智能和大模型的发展和应用充满了期待。我相信随着技术的不断进步,大模型将在更多领域展现出强大的能力,如医疗、自动驾驶、智能推荐等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!