linux性能优化-cpu使用率
文章目录
1.CPU使用率
用什么指标来描述系统的CPU性能呢?不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标CPU使用率,CPU使用率是单位时间内CPU使用情况的统计,以百分比的方式展示。
2.节拍率的概念
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiwies记录了开机以来的节拍数。每发生一次时间中断,Jiwies的值就加 1。
2.1.查看系统节拍率
不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。
[root@centos7-2 ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000
2.2.用户节拍率
正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样用户空间程序并不需要关心内核中 HZ被设置成了多少,因为它看到的总是固定值USER_HZ。
USER_HZ=100
为了方便用户控件程序,内核还提供了一个用户控件的节拍率,它总是固定为100,也就是1/100秒,这样用户控件程序并需要关系内核中HZ被设置成了多少
2.3.CPU使用率公式
CPU使用率,就是除了空闲时间外的其他时间占总CPU时间的百分比,用公式来表示就是
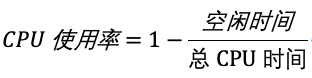
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出CPU使用率。当然,也可以用每一个场景的CPU 时间,除以总的 CPU 时间,计算出每个场景的CPU使用率。
为了计算机CPU使用率,性能能工具一般都会间隔一段时间(比如 3 秒)的两次值做差后,再计算出这段时间的平均CPU使用率。

性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证他们用的是相同的间隔时间。
3.怎么查看CPU使用率
top显示了系统总体的 CPU和内存使用情况,以及各个进程的资源使用情况;ps则只显示了每个进程的资源使用情况;pidstat分析每个进程CPU使用情况
3.1.top显示系统总体CPU使用情况
top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况
#查看cpu整体负载
top
top - 14:25:10 up 1:30, 2 users, load average: 0.18, 0.21, 0.25
Tasks: 235 total, 1 running, 234 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.2 us, 0.5 sy, 0.0 ni, 98.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
MiB Mem : 7915.7 total, 2686.9 free, 3559.6 used, 1670.1 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4127.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1084 root 20 0 977416 82904 43556 S 2.3 1.0 0:10.82 systemd
1243 alice 20 0 1710980 395384 40816 S 1.7 4.9 0:08.73 gnome-shell
1912 bob 20 0 665208 73144 54936 S 1.0 0.9 0:03.44 chrome
925 root 20 0 0 0 0 I 0.7 0.0 0:02.30 kworker/0:2-events
3051 alice 20 0 835956 64388 44480 S 0.3 0.8 0:01.27 gnome-terminal-
#解释示例输出:
- `top - 14:25:10 up 1:30, 2 users, load average: 0.18, 0.21, 0.25`:
显示当前系统时间、系统已运行时间、当前登录用户数以及系统的平均负载情况。
- `Tasks: 235 total, 1 running, 234 sleeping, 0 stopped, 0 zombie`:
显示当前系统任务的统计信息,包括总任务数、正在运行的任务数、睡眠中的任务数、停止的任务数和僵尸进程数。
- `%Cpu(s): 1.2 us, 0.5 sy, 0.0 ni, 98.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st`:
显示CPU使用情况的统计信息,包括用户空间占用率、系统空间占用率、Nice优先级任务占用率、空闲率、等待IO的任务占用率、硬中断占用率、软中断占用率和虚拟化占用率。
- `MiB Mem: 7915.7 total, 2686.9 free, 3559.6 used
3.2.pidstat分析每个进程CPU使用情况
top并没有细分进程的用户态CPU和内核态CPU,那要怎么查看每个进程的详细情况呢?
[root@centos7-2 ~]# pidstat 1 5
Linux 3.10.0-693.el7.x86_64 (centos7-2) 2023年12月17日 _x86_64_ (2 CPU)
20时54分33秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时54分34秒 0 24002 0.98 0.98 0.00 0.00 1.96 0 pidstat
20时54分34秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时54分35秒 27 1112 0.00 0.99 0.00 0.00 0.99 0 mysqld
20时54分35秒 0 24002 0.00 1.98 0.00 0.00 1.98 0 pidstat
20时54分35秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时54分36秒 0 24002 1.00 1.00 0.00 0.00 2.00 0 pidstat
20时54分36秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时54分37秒 0 24002 1.00 1.00 0.00 0.00 2.00 0 pidstat
20时54分37秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时54分38秒 0 24002 0.00 1.00 0.00 0.00 1.00 0 pidstat
平均时间: UID PID %usr %system %guest %wait %CPU CPU Command
平均时间: 27 1112 0.00 0.20 0.00 0.00 0.20 - mysqld
平均时间: 0 24002 0.60 1.19 0.00 0.00 1.79 - pidstat
参数详细说明:
- 用户ID (UID): 进程所有者的用户ID。
- 进程ID (PID): 进程的唯一标识符。
- %usr (User CPU %): 用户空间的 CPU 使用率。
- %system (System CPU %): 内核空间的 CPU 使用率。
- %guest (Guest CPU %): 虚拟机(guest)的 CPU 使用率。
- %wait (IO Wait %): 进程等待 I/O 操作的时间比例。
- %CPU (CPU %): 进程的总 CPU 使用率(%usr + %system)。
- CPU: 指示在哪个 CPU 上运行的进程。
- Command: 进程的命令名。
4.CPU使用率过高怎么办
**分析思路 **
- 如何轻松找到CPU使用率过高的进程
通过top、ps 、pidstat等工具
- 占用CPU高的到底是代码里的那个函数?
perf和GDB
GDB(The GNU Project Debugger),这个功能强大的程序调试利器,GDB调试程序的过程会中断程序运行,这在线上环境往往是不允许的;
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题 ,使用 perf 分析 CPU 性能问题,我来说两种用法:
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
[root@centos7-2 ~]# perf top
Samples: 724 of event 'cpu-clock', Event count (approx.): 125711088
Overhead Shared Object Symbol
45.11% [kernel] [k] generic_exec_single
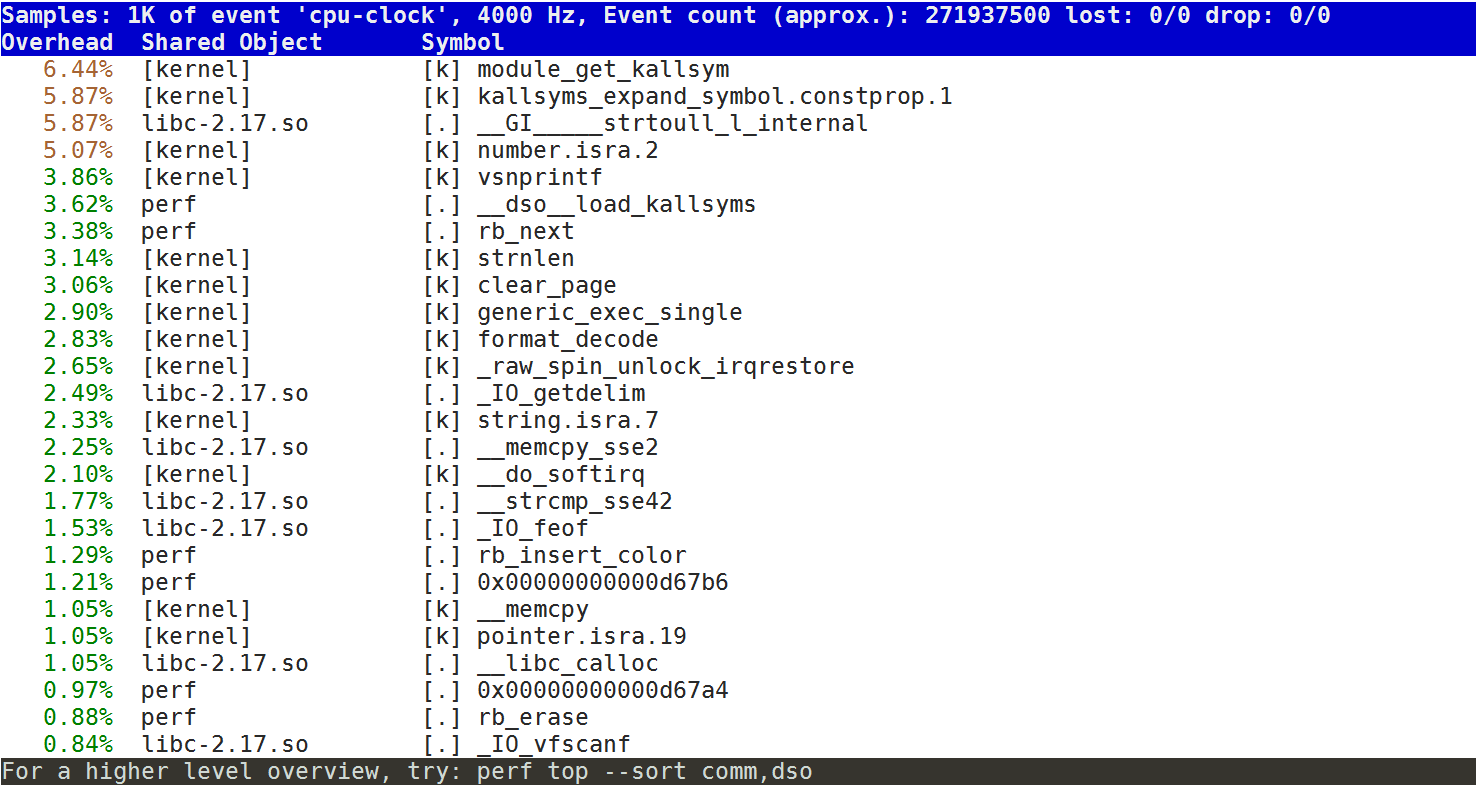
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了1000个 CPU 时钟事件,而总事件数则为 271937500。 采样数需要我们特别注意,如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
4.1.perf命令详解
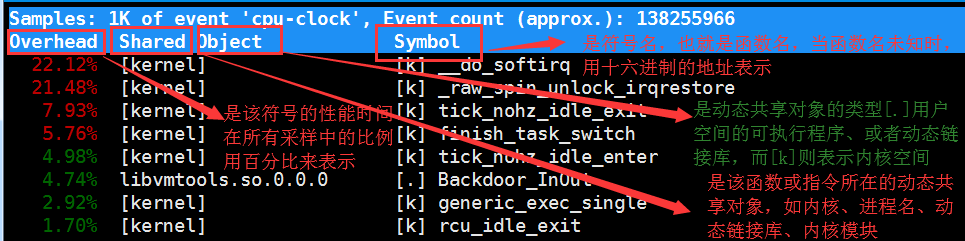
第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用perf report 解析展示
perf record # 按 Ctrl+C 终止采样
[root@centos7-2 ~]# perf report
Samples: 5K of event 'cpu-clock', Event count (approx.): 1332500000
Overhead Command Shared Object Symbol
97.15% swapper [kernel.kallsyms] [k] native_safe_halt
0.49% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.36% vmtoolsd libvmtools.so.0.0.0 [.] Backdoor_InOut
0.34% swapper [kernel.kallsyms] [k] __do_softirq
0.17% swapper [kernel.kallsyms] [k] tick_nohz_idle_exit
0.13% swapper [kernel.kallsyms] [k] tick_nohz_idle_enter
0.13% vmtoolsd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.11% kworker/0:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.11% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbOut
0.08% dockerd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.08% vmtoolsd [kernel.kallsyms] [k] __do_softirq
0.06% kworker/1:2 [kernel.kallsyms] [k] queue_delayed_work_on
0.06% vmtoolsd [kernel.kallsyms] [k] format_decode
0.04% irqbalance [kernel.kallsyms] [k] cap_mmap_file
0.04% kworker/0:0 [kernel.kallsyms] [k] ata_sff_pio_task
0.04% kworker/1:2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.04% mysqld mysqld [.] fts_optimize_words
0.04% swapper [kernel.kallsyms] [k] rcu_idle_exit
0.04% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbIn
0.02% dockerd [kernel.kallsyms] [k] __do_softirq
0.02% in:imjournal rsyslogd [.] 0x0000000000016f90
0.02% irqbalance [kernel.kallsyms] [k] __fsnotify_parent
0.02% irqbalance [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.02% irqbalance [kernel.kallsyms] [k] copy_user_generic_unrolled
0.02% irqbalance [kernel.kallsyms] [k] native_flush_tlb_single
0.02% irqbalance [kernel.kallsyms] [k] unmap_page_range
Tip: For tracepoint events, try: perf report -s trace_fields
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ChatGPT绘制全球植被类型分布图、生物量图、土壤概念图、处理遥感数据并绘图、病毒、植物、动物细胞结构图
- 《算法通关村——回溯模板如何解决回溯问题》
- Java基础进阶(学习笔记)
- MySQL 索引连环问题,你能答对几个?
- 自动化补丁管理软件
- 如何用 Python 实现一个 “系统声音” 的实时律动挂件
- JavaScript实现字符串首字母大写、翻转字符串、获取用户选定的文本
- C++重新认知:头文件的预处理
- 内网穿透方案&FRP内网穿透实战(基础版)
- 【全栈软件测试】软件测试学习技术交流-欢迎志同道合者加入