基于LLM大模型的信息提取指南
信息提取(information Extraction)是从文本或文档集合中自动检索与特定主题相关的特定信息的过程。 这通常涉及自然语言处理技术的使用。 使用自然语言处理来提取信息通常会导致构建复杂的逻辑,这些逻辑有时非常具体并且不能很好地概括。
好吧……但是我们在谈论什么复杂的逻辑呢?
NSDT工具推荐:?Three.js AI纹理开发包?-?YOLO合成数据生成器?-?GLTF/GLB在线编辑?-?3D模型格式在线转换?-?可编程3D场景编辑器?-?REVIT导出3D模型插件?-?3D模型语义搜索引擎?-?Three.js虚拟轴心开发包
复杂的逻辑可能涉及技术,例如尝试设计可以解析某些类型文档的模块。 人们必须浏览大量文档才能对布局有一个大致的了解,然后尝试提出依赖于 AWS Textract 等 OCR 服务中的键值对提取的模块,或者使用基于自然语言的提取逻辑来设计 复杂的正则表达式或只是简单地在某些关键字的空间局部性中搜索其相应的值。 这些方法虽然成功,但不能完全不受文档结构变化的影响。
随着在数百万文档和文本的语料库上训练的大型语言模型 (LLM) 的出现,解决这个问题变得相当容易。 大型语言模型可以轻松提取有关给定上下文和模式的属性的信息。 在大多数简单的情况下,它们不需要对任务进行额外的微调,并且可以很好地泛化。 LLM可以更好地分析的文档类型包括简历、法律合同、租赁、报纸文章和其他非结构化文本文档。
此外,为了实现 LLM 功能的民主化,OpenAI 提供了 API,可用于从 GPT 3.5 和 GPT 4 等 LLM 产品生成结果。
在本文中,我将讨论一个非常基本的信息提取管道可能是什么样子,以及如何使用 LangChain 和 Streamlit 等现代 Python 框架,轻松地围绕 LLM 构建 Web 应用程序。
实现方案如下图所示:
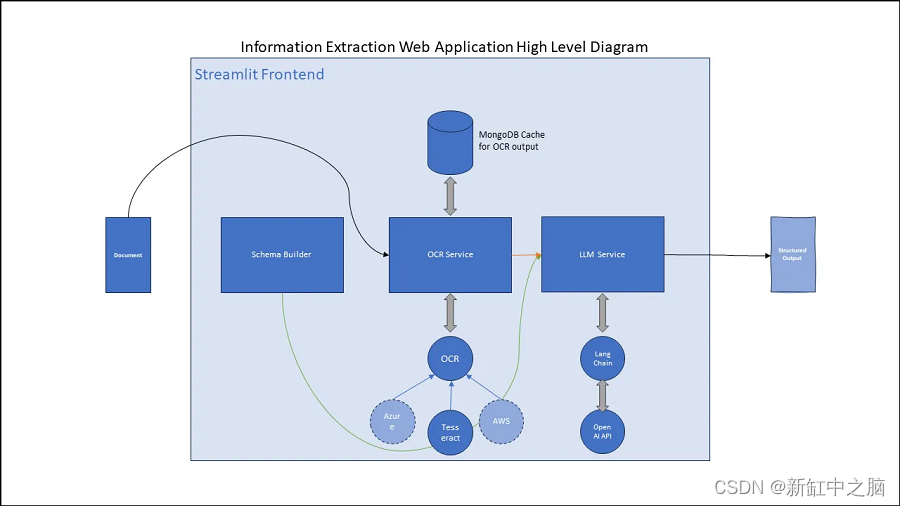
信息提取系统示意图
1、光学字符识别
从图像中提取机器可读格式的文本称为光学字符识别 (OCR)。 任何信息提取产品或服务的第一步都是从文档中提取文本。 该文档可以是 PDF 文件或扫描/捕获的图像。 最终,PDF 被转换为图像集合,其中每个页面都被转换为单个图像。 因此,OCR 模型本身仅适用于图像。
有许多付费和开源 OCR 服务可用。 在本文中,我使用一个名为?Tesseract?的开源项目来执行 OCR 并检索文本。
项目中的 OCR 类是一个?Python Protocol,可以扩展以实现不同的付费 OCR 服务,如 Tesseract、AWS Textract、Azure Vision API 等。
from typing import Protocol
class OCR(Protocol):
"""
OCR Protocol Class
"""
def get_text_response(self, images: list) -> list:
pass使用 Tesseract 扩展 OCR类:
import pytesseract
from ocr import OCR
class TesseractOCR(OCR):
def get_text_response(self, images: list) -> list:
"""Generates ocr response from list of images
Args:
images (list): list of images to be processed.
Returns:
list: list of ocr responses for each image.
"""
pdf_texts = []
for image in images:
text = pytesseract.image_to_string(image)
pdf_texts.append(text)
return pdf_texts同样,可以扩展相同的 OCR 协议来实现 OCR 产品的其他类,例如 AWS Textract 和 Azure Vision。
2、LangChain 提取和模式生成器
Schema Builder(模式生成器)从LLM获得结构化的输出。 模式是属性的集合。 该模式将以提供的格式输出结果。 模式中的每个属性都需要定义三个属性:属性名称、属性类型以及属性是否必需。
一旦构建了模式,它就可以用于生成LLM的结构化输出:

来源:https://python.langchain.com/docs/use_cases/extraction
在上图中,输入充当 LLM 的上下文。 模式提供了输出的格式,还指定了需要提取的字段及其相应的数据类型。 LangChain支持的可能的数据类型是“字符串”和“整数”。 一旦我们有了上下文和模式,就可以将它们提供给 LLM 以生成响应。
3、LangChain
LangChain 是一个用于开发利用语言模型力量的应用程序的框架。 它使应用程序能够:
- 具有上下文感知能力
- 进行推理
本文使用了LangChain中与Extraction相关的功能。 一些 LLM(例如 OpenAI)可以调用函数从 LLM 响应中提取任意实体。 这些函数可用于获取具有指定模式的结构化模型输出。
"""
LLM Handler Code
"""
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_extraction_chain
class LLM:
"""Handles communication with OpenAI LLMs"""
def __init__(self, temperature: float, openai_api_key: str) -> None:
self.llm = ChatOpenAI(temperature=temperature, openai_api_key=openai_api_key)
def analyze_text(self, text: str, schema: dict) -> dict:
"""Analyze text according to schema
Args:
text (str): OCR Output to be analyzed
schema (dict): Schema to be processed
Returns:
dict: LLM Response
"""
chain = create_extraction_chain(schema, self.llm)
return chain.run(text)所以,管道是这样的,我们从 OCR 模块获取机器可读格式的文本,并且我们还构建架构来指定输出的结构。
OCR 输出的文本是上下文,架构生成器帮助准备所需格式的架构。 一旦我们有了这两个,那么我们就使用 LangChain 的?create_extraction_chain?函数来生成输出。
可以从这里?了解有关 LangChain 提取技术的更多信息。
4、Streamlit前端
所有机器学习应用程序都需要交互式 Web 应用程序,以便更轻松地呈现其结果和性能。?Streamlit?是一个免费、开源、全 Python 框架,使数据科学家能够快速构建交互式仪表板和机器学习 Web 应用程序,而无需前端 Web 开发经验。
为了展示使用 Streamlit 和 Langchain 构建交互式应用程序是多么容易,这里有一个代码片段和生成的 Web 应用程序。
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# Streamlit App Title
st.title("🦜🔗 Langchain - Blog Outline Generator App")
# OpenAI API key required to access their APIs
openai_api_key = st.sidebar.text_input("OpenAI API Key", type="password")
def blog_outline(topic:str):
# Instantiate LLM model
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", openai_api_key=openai_api_key)
# Prompt
template = "As an experienced data scientist and technical writer, generate an outline for a blog about {topic}."
prompt = PromptTemplate(input_variables=["topic"], template=template)
prompt_query = prompt.format(topic=topic)
# Run LLM model
response = llm(prompt_query)
# Print results
return st.info(response)
with st.form("myform"):
topic_text = st.text_input("Enter prompt:", "")
submitted = st.form_submit_button("Submit")
if not openai_api_key:
st.info("Please add your OpenAI API key to continue.")
elif submitted:
blog_outline(topic_text)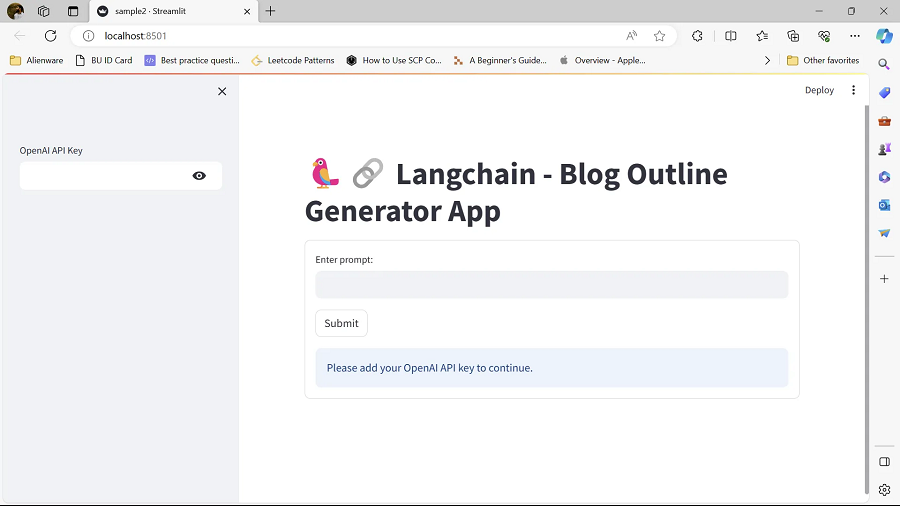
请在你的数据上尝试更多?Streamlit?应用程序示例,并阅读其文档和教程以了解更多信息。 整个信息提取应用程序是使用 Streamlit 设计的!
5、状态机
因此,关于 Streamlit 需要注意的一件事是,每当有人与应用程序“交互”时,脚本就会从上到下重新执行。 所以在这里,交互意味着单击按钮或移动滑块。 因此,要构建具有多个阶段的 Streamlit 应用程序,在编写代码时使用状态设计模式是有益的。

上面是该信息提取应用程序的整个代码中使用的状态图和转换。 为了遵守状态设计模式的规则,使用了名为?Transitions?的 Python 包,它提供了轻量级状态机实现。 但人们也可以实现自己的状态机。
6、应用程序
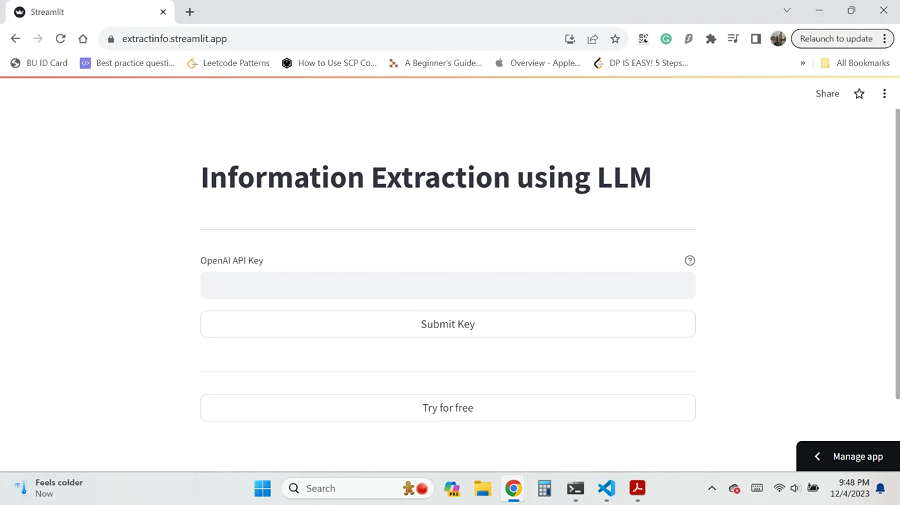
欢迎页提示你输入 OpenAPI 密钥以继续操作。 我还提供了免费试用最多五次的功能。
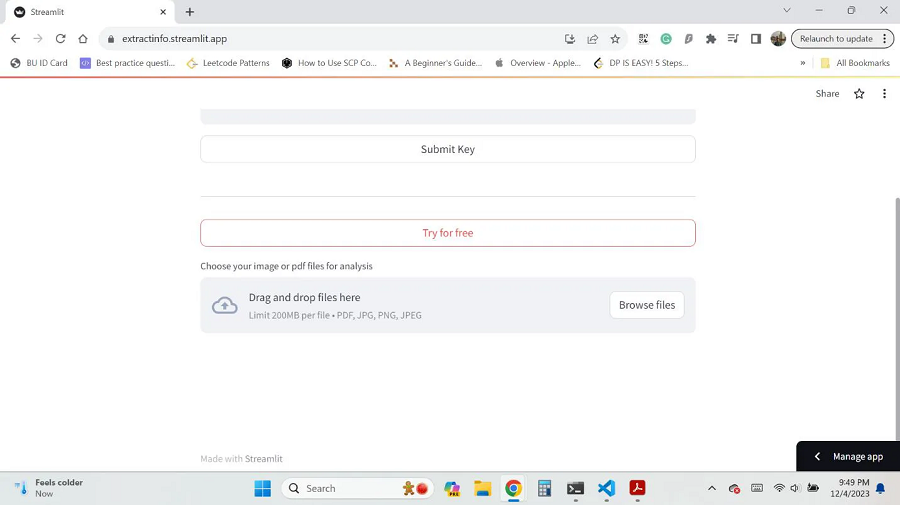
文件上传页等待上传要上传的文件(图像或 PDF)。 也可以上传多个文件。 该应用程序支持 JPG、PNG 和 PDF 文件格式。
架构生成器页用来构建模式来接收来自 OpenAI 提取 API 的结构化输出。
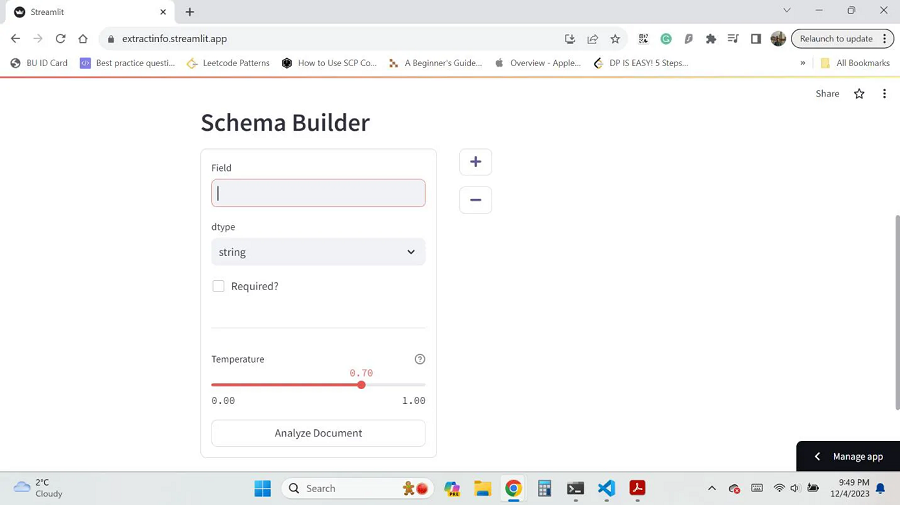
LLM输出页将提取 API 的输出显示为数据框。 每个上传的文件都会被分析,其输出显示为单独的选项卡。 侧边栏还显示原始架构,可以更改它以重新分析所有文档。
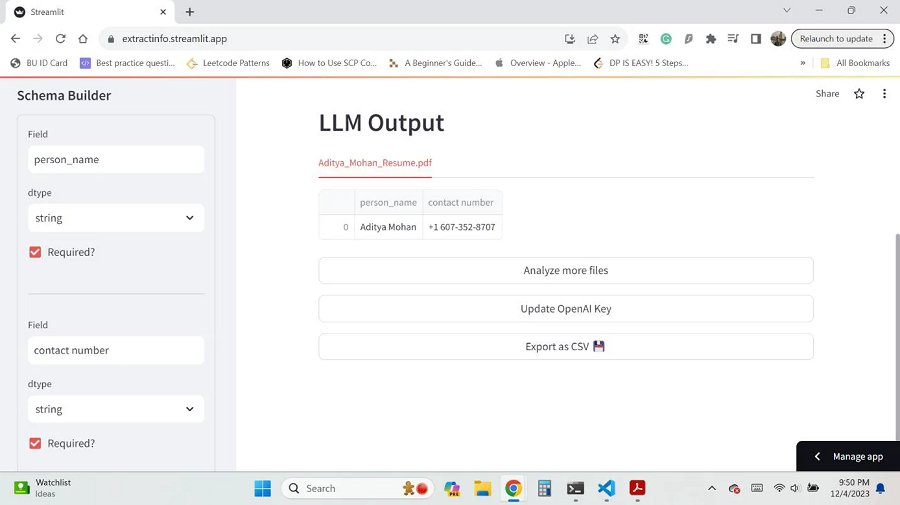
因此,正如你在 LLM 输出屏幕中看到的那样,数据框的列是我指定的字段,值是 OpenAI LLM 输出的值。
7、GitHub 存储库
在这里,我提供了包含此应用程序代码的两个存储库的链接。 我使用 Flask 和单独的 Streamlit App 存储库创建了一个 OCR API。
- OCR 存储库 —?https://github.com/mohan-aditya05/text_analysis_ocr_service
- 应用程序存储库 —?https://github.com/mohanbing/st_doc_ext
8、结束语
该应用程序有效地展示了大型语言模型的强大功能以及它们如何在不同文档上很好地泛化。 在LLM的帮助下,信息提取任务变得非常容易。 此外,使用 Streamlit,只需具备 Python 知识,无需任何前端经验,就可以轻松开发出外观非常现代的前端。 它是围绕机器学习模型构建概念验证和小型应用程序的完美框架。
警告!!!
认为仅使用 LLM 就能帮助你解决所有信息提取问题的想法并不谨慎。 像 ChatGPT 这样的LLM旨在理解自然语言。 它们可能不适用于仅包含键值对或表格信息且不同标记之间没有真正语言关系的文档。 为了处理这些类型的文档,使用其他传统的信息提取技术可能仍然更好。 不过,随着支持视觉的 GPT 4 的到来,这个问题也可能得到解决。
原文链接:LLM信息提取指南 - BimAnt
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在不确定的时代,程序员如何更好的经营家庭
- Vue布局秘籍:用这些技巧打造炫酷页面!
- Python---进程
- 玩转 Go 语言并发编程:Goroutine 实战指南
- 大小论文over,坐等毕业。写点ROS上建图与导航的心得,也不知道对错,欢迎讨论~(对,谨慎阅读,不存在误人子弟哈~.~)
- YOLOv5改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
- 画颜色圆圈icon
- 鸿蒙不兼容安卓!正式迈入“完全自主研发”阶段,余承东最新发声!
- 腾讯云轻量服务器和云服务器区别对比(超详细)
- Java SE入门及基础(17)