【MySQL】数据库之存储引擎
目录
一、什么是存储引擎
存储引擎是MySQL数据库中的一个【组件】,【负责执行实际的数据I/O操作】,工作在文件系统之上,数据库的数据会先传到存储引擎,在按照存储引擎的格式,保存到文件系统。
常用的存储引擎:InnoDB 、MyISAM

?MySQL 整个查询执行过程,即MySQL的工作原理?
1、MySQL服务器接收到来自客户端的数据请求;
2、数据库会先查询缓存记录,如果命中缓存,直接返回存储在缓存中的查询结果,如果没有命中,则进行下一步操作;
3、数据库会先由解析器来解析SQL语句的,然后进行预处理,接着用优化器生成最优的执行计划;
4、数据库根据最优的执行计划,调用存储引擎的API接口来执行查询结果,并将结果返回给客户端,同时缓存查询结果;
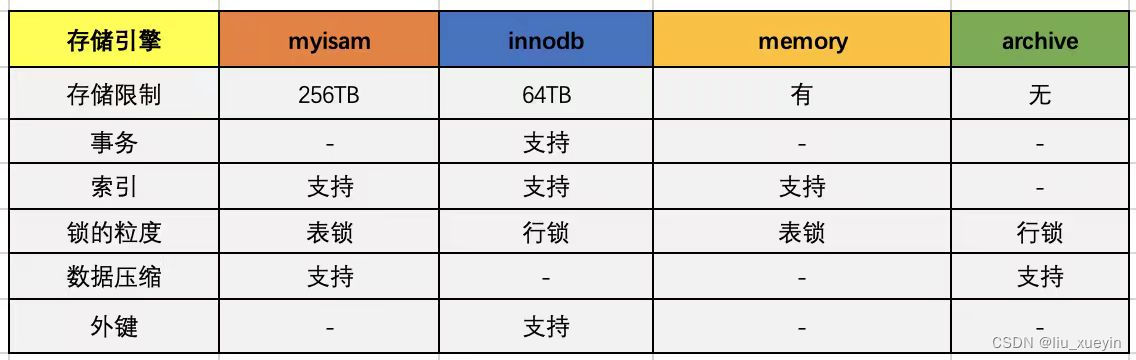
二、MyISAM 与 InnoDB 的区别?
| 序号 | 类型 | MyISAM | InnoDB |
| 1 | 事务 | 不支持事务 | 支持事务 |
| 2 | 外键约束 | 不支持外键约束 | 支持外键约束 |
| 3 | 锁定方式 | 只支持表级锁定 | 支持行级锁定,全表扫描时会表级锁定 |
| 4 | MVCC | 不支持MVCC | 支持MVCC(多版本并发控制) |
| 5 | 读写性能 | 只支持单独的查询与插入,读写阻塞 | 读写和事务并发能力较好 |
| 6 | 全文索引 | 支持全文索引 | 支持全文索引(5.5版本以后支持) |
| 7 | 硬件 | 硬件资源占用较小 | 缓存能力较好,可以减少磁盘IO的压力 |
| 8 | 存储文件 | 数据文件和索引文件分开存储,存储为三个文件(.frm的表结构文件,.MYD的数据文件,.MYI的索引文件) | 数据文件也是索引文件,存储成两个文件(.frm的表结构文件,.ibd的数据和索引文件) |
| 9 | 使用场景 | 使用场景:使用不需要事务支持,单独的查询和插入的业务场景 | 使用场景:使用于需要事务支持,一致性要求比较高,数据会频繁更新,读写并发高的业务场景; |
 ?
?
三、如何查看当前表的存储引擎?
1.查看当前的存储引擎
show create table 表名;
show table status [from 库名] where name='表名'\G
 ?
?
2.查看数据库支持哪些存储引擎
show engines;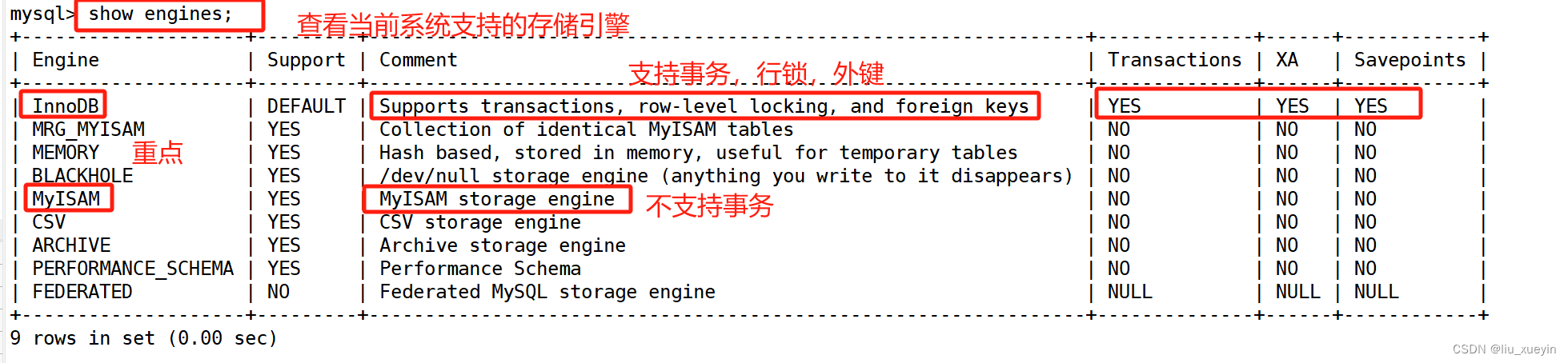
四、如何设置存储引擎?
1、当前表已经存在,想要修改其存储引擎
alter table 表名 engine=innodb/myisam;

2、想要修改表的默认储存引擎
vim /etc/my.cnf
[mysqld]
default-storage-engine=innodb/myisam
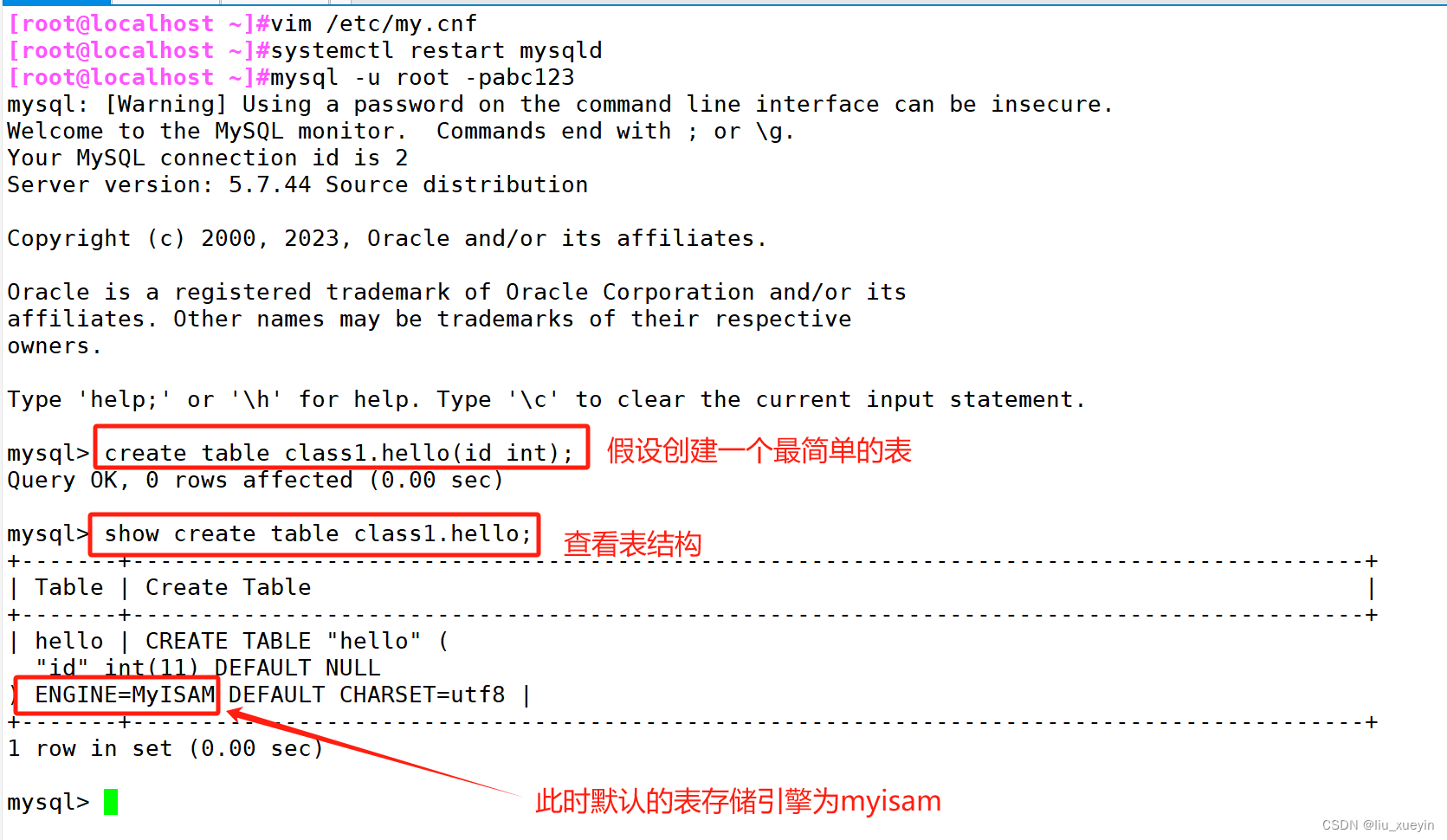
systemctl restart mysqld
mysql -uroot -p密码
create table 表名(字段 数据类型,...);
show create table 表名;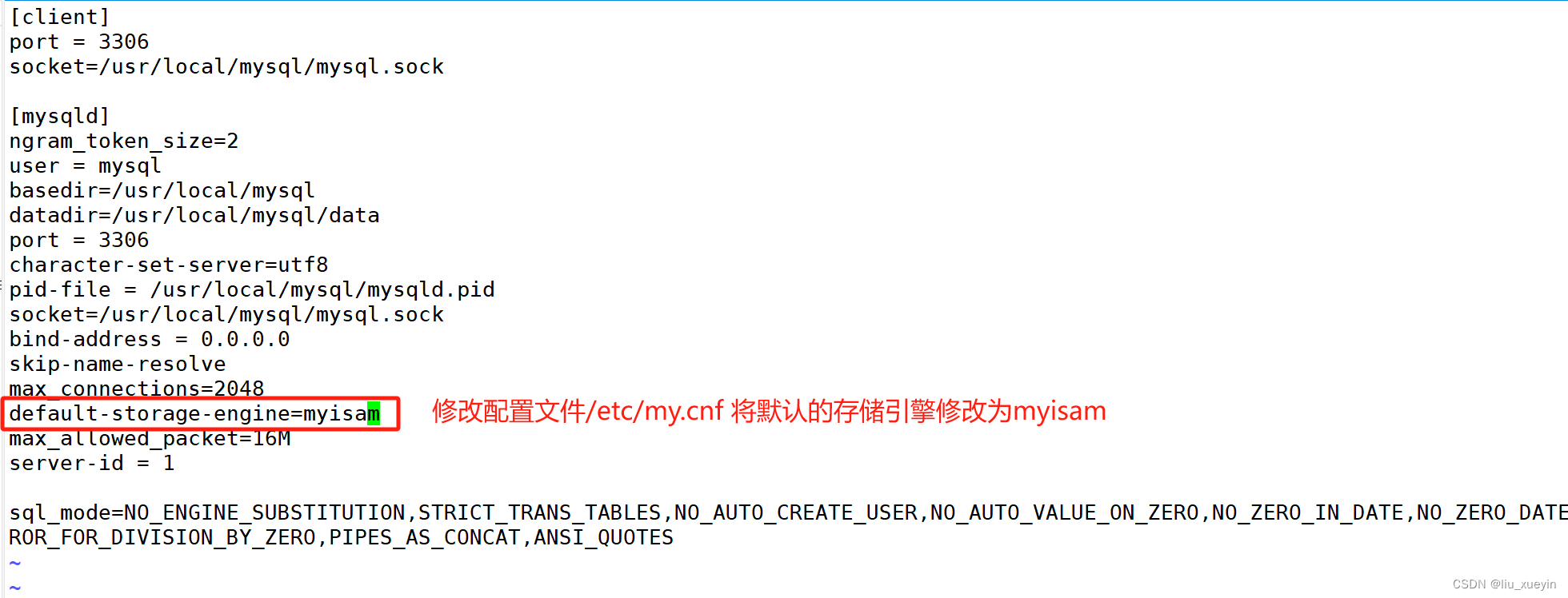

3、想要在创建表的时候,直接指定存储引擎
create table 表名 (字段 数据类型,...) engine=innodb/myisam;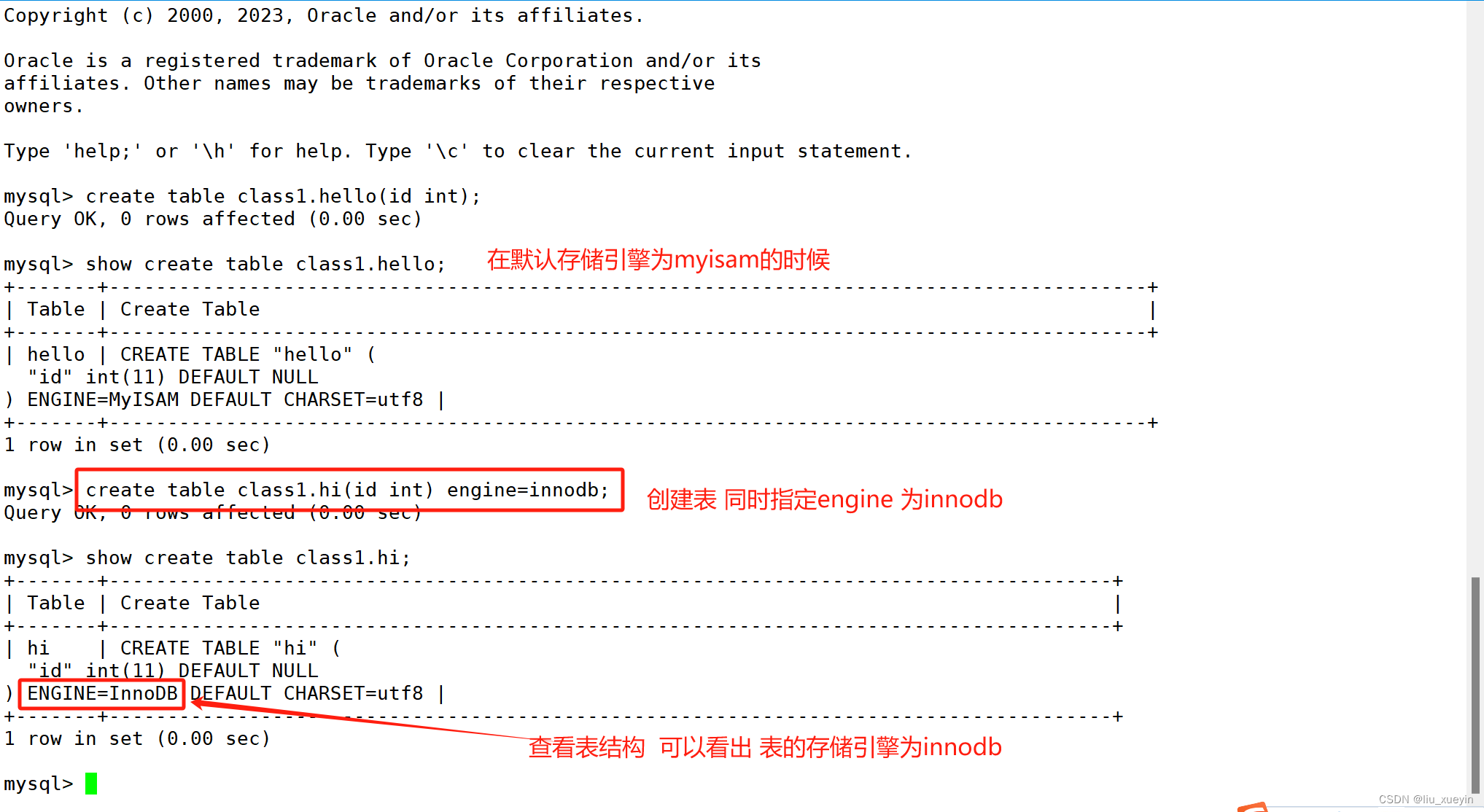
五、什么是死锁?以及怎么解决/预防?
死锁是指两个或多个事务在同一个资源上相互占用,并请求对方的锁定资源,从而导致恶性循环的现象,业务阻塞。
- 设置事务超时等待时间,innodb_lock_wait_timeout
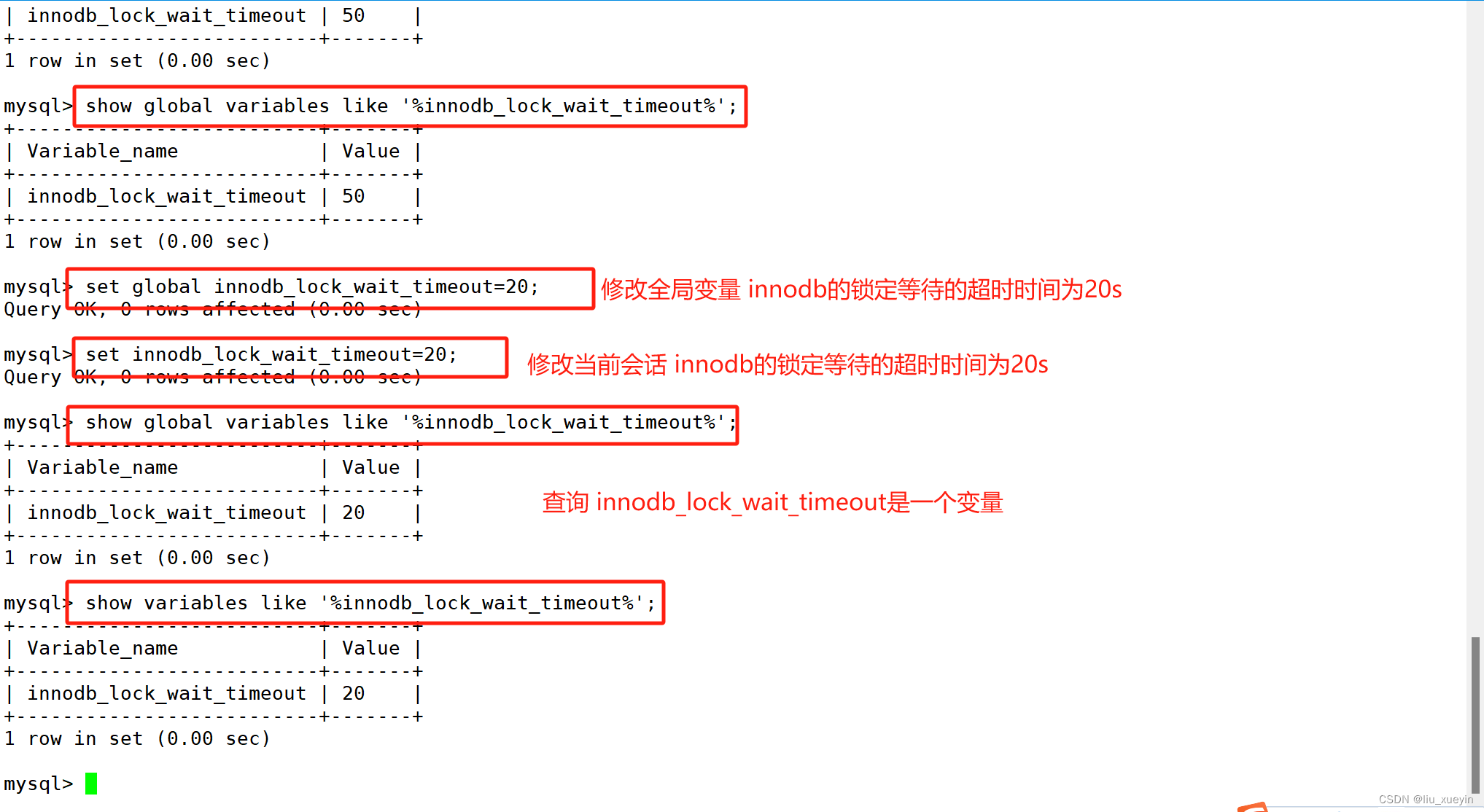
- 开启死锁检测,innodb_deadlock_detect

- 使用更合理的业务逻辑,尽量按照顺序去处理表的操作,避免同时锁定两个资源;
- 保持事务剪短,减少对资源的占用时间和占用范围;
- 为表添加合理的索引,减少表锁发生的概率;
首先如果是由索引的情况下修改或删除数据使用where限定条件字段为索引字段,只会进行行级锁定。如果是where指定的条件的字段并没有索引,那么就会进行表级锁定。
- 如果业务允许的情况下,减低隔离级别,比如采用RC提交读隔离级别;可以避免掉很多因为间隙锁造成的死锁。
尽量避免脏读所以不使用RU,如果业务允许的恶化,可以降低隔离级别为RC,比如MySQL的默认隔离级别为RR,可以将其改为RC,支持较少的锁定
- 建议开发人员尽量采用乐观锁机制;
七、InnoDB如何避免全表扫描?
首先要知道全表扫描时非常耗时的,占用cpu资源,所以需要避免全表扫描
怎么看是否会不会全表扫描?
不是创建了索引就一定会在查询的时候用到索引的
使用explain加上select查询语句进行分析,如果是type字段的值为NULL那就说明没有用索引,会全表扫描。
如何避免全表扫描?
1、需要避免where的条件有null的判断;
2、避免where的条件是!=和<> 这都是在判断是否空;
3、避免where后面的条件中的字段存在运算,比如
select * from 表名 where age/2=15;
这种就是字段存在运算
需要修改为
select * from 表名 where age=15 * 2;4、避免where后面的条件中 字段使用了函数,这一点跟第3点很像
5、避免在使用like模糊查询的时候,引号内的关键字为%开头?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Day6、指针的基本学习
- Qt中moveToThread注意的地方
- 【SpringBoot】Spring Boot 单体应用升级 Spring Cloud 微服务
- 职业性格测试与求职应聘者的关系
- centos7安装node-v18版本
- 体系结构汇总复习(练习题)
- 羊大师讲解喝羊奶的好处,让女性坚持下去!
- 阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库
- 嵌入式系统的分类
- WordPress函数has_tag的介绍及用法示例,判断是否含有指定标签?