向量数据库:usearch的简单使用+实现图片检索应用
发布时间:2024年01月07日
usearch的简单使用
- usearch是快速开源搜索和聚类引擎×,用于C++、C、Python、JavaScript、Rust、Java、Objective-C、Swift、C#、GoLang和Wolfram 🔍中的向量和🔜字符串×
// https://github.com/unum-cloud/usearch/blob/main/python/README.md
$ pip install usearch
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting usearch
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ba/f4/24124f65ea3e940e54af29d55204ddfbeafa86d6b94b63c2e99baff2f7d6/usearch-2.8.14-cp38-cp38-manylinux_2_28_x86_64.whl (1.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.5/1.5 MB 17.0 MB/s eta 0:00:00
Requirement already satisfied: numpy in /home/ubuntu/anaconda3/envs/vglm2/lib/python3.8/site-packages (from usearch) (1.23.1)
Requirement already satisfied: tqdm in /home/ubuntu/anaconda3/envs/vglm2/lib/python3.8/site-packages (from usearch) (4.66.1)
Installing collected packages: usearch
Successfully installed usearch-2.8.14
- 一个简单的例子(注:本例子在运行时向index中不断添加项目,并将最后的index持久化为一个文件,在运行时由于添加项目内存占用会不断增加)
import numpy as np
from usearch.index import Index, MetricKind, Matches
ndim = 131072
index_path = "test.usearch"
index = Index(
ndim=ndim, # Define the number of dimensions in input vectors
metric='cos', # Choose 'l2sq', 'haversine' or other metric, default = 'ip'
dtype='f32', # Quantize to 'f16' or 'i8' if needed, default = 'f32'
connectivity=16, # How frequent should the connections in the graph be, optional
expansion_add=128, # Control the recall of indexing, optional
expansion_search=64, # Control the quality of search, optional
)# index = Index(ndim=ndim, metric=MetricKind.Cos)
for i in range(1,10):
vector = np.random.random((1000, ndim)).astype('float32')
index.add(None, vector, log=True)
index.save(index_path)
vector = np.random.random((1, ndim)).astype('float32')
matches: Matches = index.search(vector, 10)
ids = matches.keys.flatten()
print(matches)
# test.usearch大小: 10*1000*131072 =>2.2G (如果dtype='f32'=>4G+)
usearch-images
- https://github.com/ashvardanian/usearch-images
运行效果

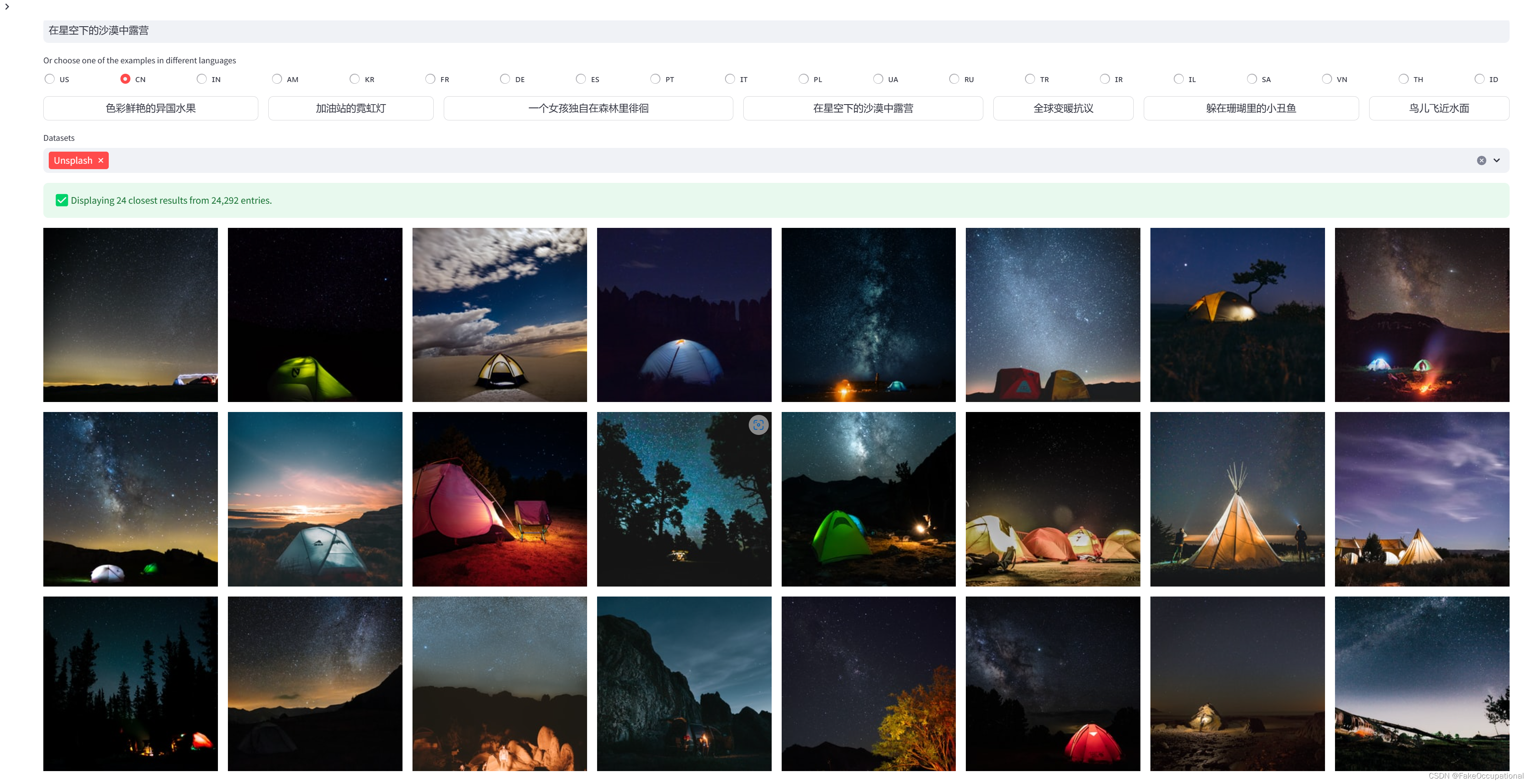
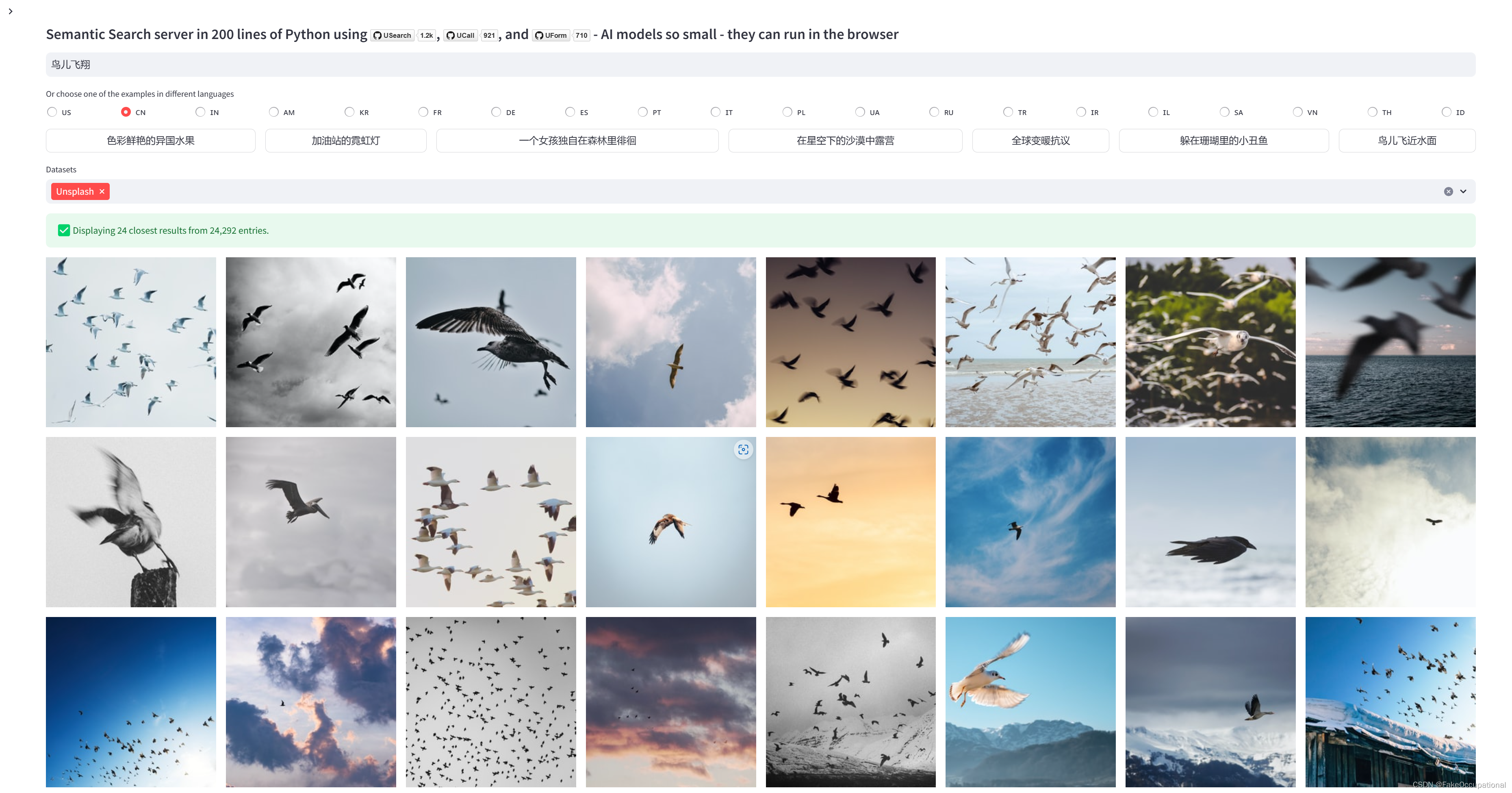
数据获取
- https://huggingface.co/datasets/unum-cloud/ann-unsplash-25k/tree/main
依赖 ucall
- Requires: Python >=3.9
- https://pypi.org/project/ucall/#files
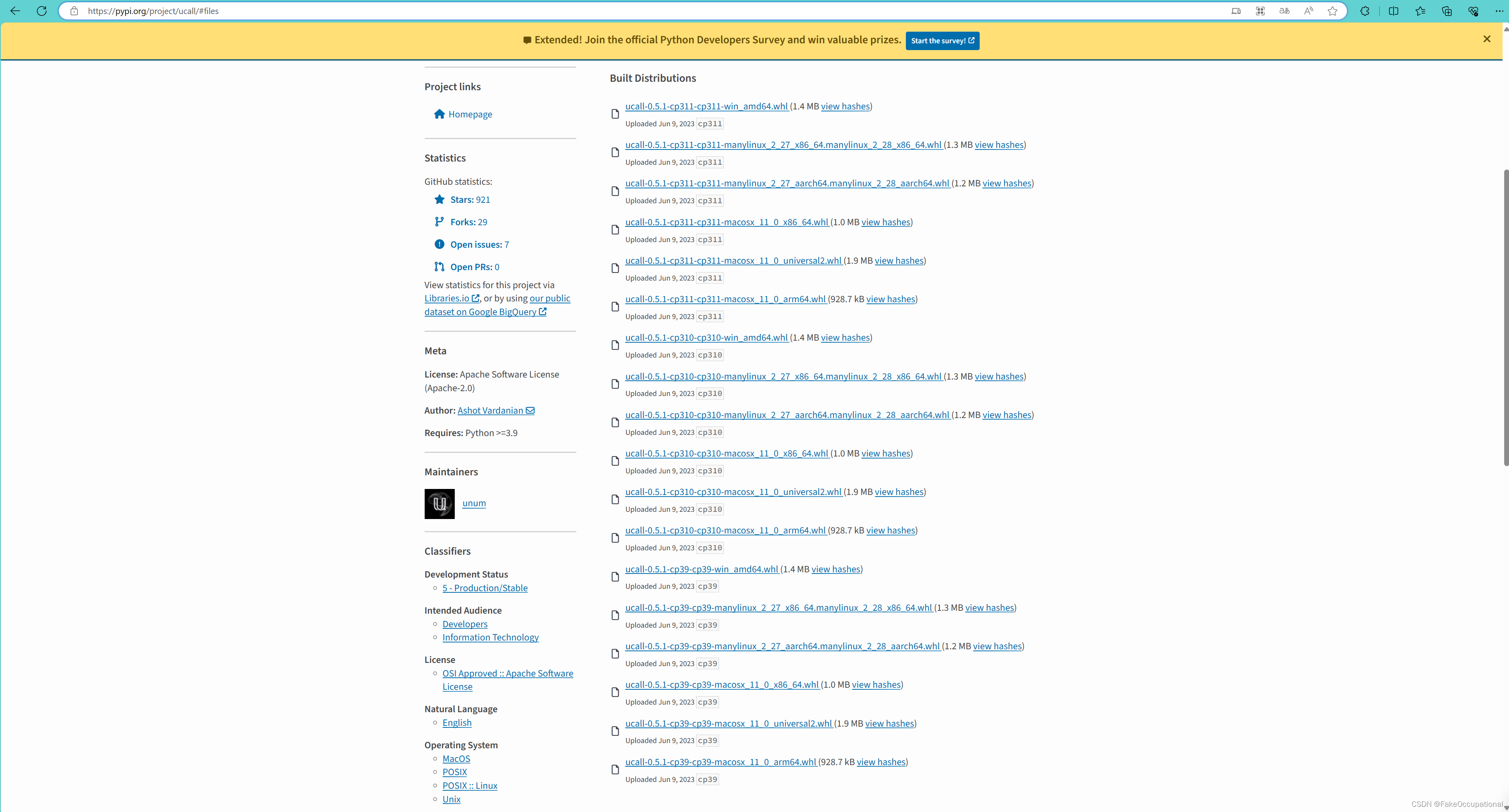
OSError: [Errno 28] inotify watch limit reached
File "/home/ubuntu/anaconda3/envs/usearch/lib/python3.10/site-packages/watchdog/observers/inotify_c.py", line 428, in _raise_error
raise OSError(errno.ENOSPC, "inotify watch limit reached")
OSError: [Errno 28] inotify watch limit reached
这个错误表明在使用 watchdog 库时超过了 Linux 系统对 inotify 监视的文件数或目录数的限制。Linux 对于每个进程的 inotify 能够监视的文件和目录有一个限制,当达到这个限制时,会出现像上面的错误一样的问题。可以尝试增加系统对 inotify 的资源限制。可以通过修改 /etc/sysctl.conf 文件来增加 fs.inotify.max_user_watches 参数的值。例如:
```bash
sudo sysctl -w fs.inotify.max_user_watches=65536
```
然后,运行下面的命令使更改生效:
```bash
sudo sysctl -p
```
注意:增加监视数可能会对系统资源产生一些影响,因此请根据实际情况慎重调整。
模型加载
- https://huggingface.co/unum-cloud/uform-vl-multilingual-v2/tree/main
///home/ubuntu/anaconda3/envs/usearch/lib/python3.10/site-packages/uform/__init__.py
def get_checkpoint(model_name, token) -> Tuple[str, Mapping, str]:
model_path = snapshot_download(repo_id=model_name, token=token)
config_path = f"{model_path}/torch_config.json"
state = torch.load(f"{model_path}/torch_weight.pt")
return config_path, state, f"{model_path}/tokenizer.json"
def get_model(model_name: str, token: Optional[str] = None) -> VLM:
config_path, state, tokenizer_path = get_checkpoint(model_name, token)
with open(config_path, "r") as f:
model = VLM(load(f), tokenizer_path)
model.image_encoder.load_state_dict(state["image_encoder"])
model.text_encoder.load_state_dict(state["text_encoder"])
return model.eval()
- 修改成如下,调用时使用
_model = get_model("你的下载路径")
def get_checkpoint(model_name, token) -> Tuple[str, Mapping, str]:
model_path = model_name#snapshot_download(repo_id=model_name, token=token)
config_path = f"{model_path}/torch_config.json"
state = torch.load(f"{model_path}/torch_weight.pt")
return config_path, state, f"{model_path}/tokenizer.json"
def get_model(model_name: str, token: Optional[str] = None) -> VLM:
config_path, state, tokenizer_path = get_checkpoint(model_name, token)
with open(config_path, "r") as f:
model = VLM(load(f), tokenizer_path)
model.image_encoder.load_state_dict(state["image_encoder"])
model.text_encoder.load_state_dict(state["text_encoder"])
return model.eval()
其他细微的修改
数据源的修改
_datasets = {
name: _open_dataset(os.path.join("/home/ubuntu/userfile/***/Usearch/usearch-images-main/data", name))
for name in (
"unsplash-25k",
# "cc-3m",
# "laion-4m",
)
}
dataset_names: str = st.multiselect(
"Datasets",
[
dataset_unsplash_name,
# dataset_cc_name,
# dataset_laion_name,
],
[dataset_unsplash_name],#, dataset_cc_name],
format_func=lambda x: x.split(":")[0],
)
- 也可下载cc-3m数据:
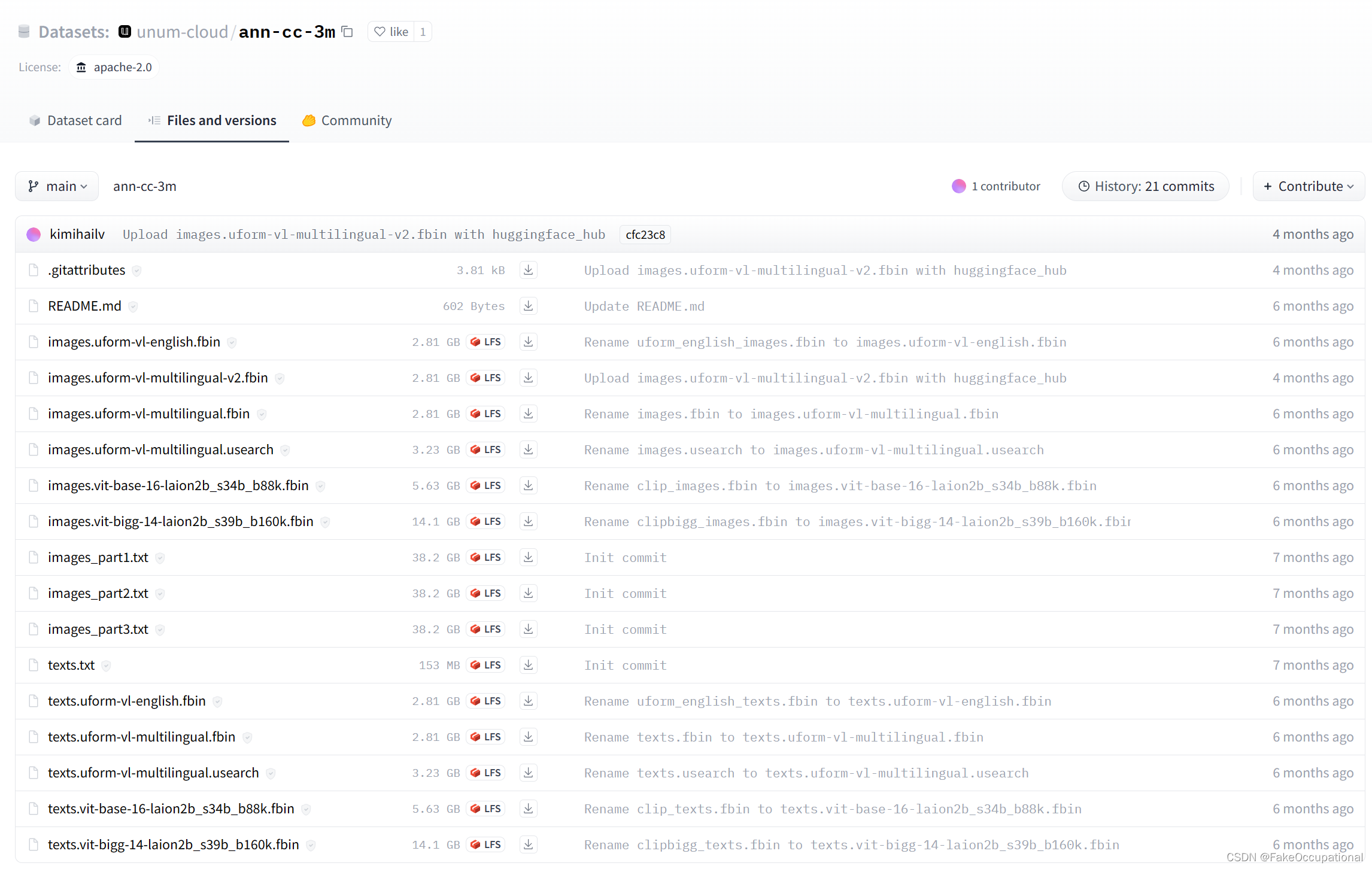
数据读取的修改
# uris: Strs = File(os.path.join(dir, "images.txt")).splitlines()
file_path = os.path.join(dir, "images.txt")
with open(file_path, 'r') as file:
uris = file.read().splitlines()
CG
- “usearch” 通常指的是一个生物信息学工具,用于对DNA和蛋白质序列进行搜索和比对。具体来说,它是由Qiime软件包提供的一个用于序列分析的工具,主要用于对微生物群落的高通量测序数据进行处理和分析。Qiime(Quantitative Insights Into Microbial Ecology)是一个用于分析和解释微生物群落结构的开源软件包。在Qiime中,usearch被用于处理和比对DNA序列,以便进行物种注释、多样性分析等。USEARCH —— 最简单易学的扩增子分析流程
文章来源:https://blog.csdn.net/ResumeProject/article/details/135432383
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 10 个值得收藏的顶级手机数据恢复软件【2024年最新】
- 设计模式——组合模式(结构型)
- 代码随想录算法训练营第十三天|239 滑动窗口最大值、347 前K个高频元素
- Backtrader 文档学习-Cerebro
- SparkSQL 是什么
- vue elementUI el-form 数据无法赋值且不报错解决方法
- 如何在面试中胜出?接口自动化面试题安排上!
- python程序打包成exe文件
- 黑马Java 集合(下)
- 一文读懂undolog和redolog的区别和联系