一文读懂「Self Attention」自注意力机制
发布时间:2024年01月08日
前言:Self-Attention是 Transformer 的重点,因此需要详细了解一下 Self-Attention 的内部逻辑。
一、什么是自注意力机制?
就上图为例,老实告诉我当你第一眼看到上图时,你的视线停留在哪个位置?对于我这种老二次元是在妹子身上,但是对于舰船迷来说,可能注意力就是在舰船上。同一张图片,不同的人观察注意到的可能是不同的地方,这就是人的注意力机制。attention 就是模仿人的注意力机制设计地。那么究竟是如何实现的呢?
二、自注意力机制结构
2.3 Self-Attention 结构
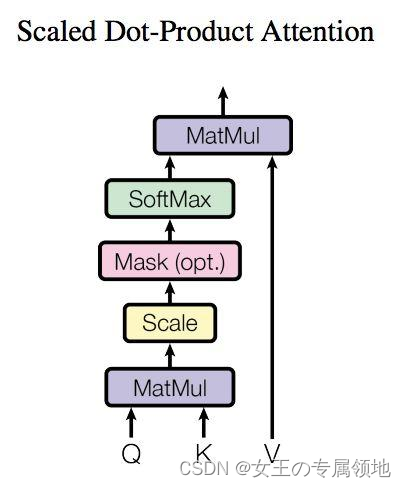
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
2.2 Q, K, V 的计算
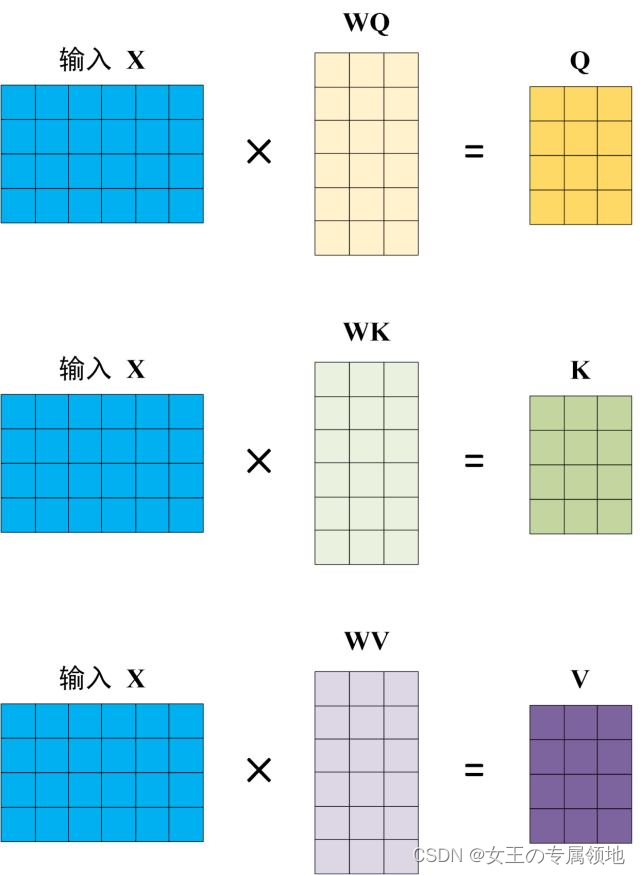
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
2.3 Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

文章来源:https://blog.csdn.net/Julialove102123/article/details/135457614
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [娱乐]索尼电视安装Kodi
- 代码随想录刷题第三十九天| 62.不同路径 ● 63. 不同路径 II
- 什么是预训练Pre-training—— AIGC必备知识点,您get了吗?
- IPD-PDP产品开发流程-PDT产品开发计划Charter文档模板(word)3
- HarmonyOS云开发基础认证考试满分答案(100分)【全网最全-不断更新】【鸿蒙专栏-29】
- 大模型训练过程概述
- 【PostgreSQL】函数与操作符-时间/日期函数和操作符
- Linux下编写zlg7290驱动(3)-键盘驱动编写
- 7-4 jmu-Java-01入门-开根号 --笔记篇
- 机器学习之实验过程02