借力 CodeArts Snap,助我打开“结果倒推过程“的新思路
重拾 Python 的学习之路
我之前学过一段时间的 Python,因为工作中一直用不上,所以后面就荒废了。
现在,智能化编程是一个趋势,所以我想着干脆重拾一下 Python,强化一下自身的技能树。
但是,想的容易,难在"坚持"二字。
于是,我想这次换个方法。
有时,学习像在搭积木
有时候,学东西就像在搭积木,先局部实现,最后拼装在一起。
如果一开始就像绘画那样完成一副画作,可能会有些难度。
但是,搭积木,初始状态下,不需要拥有太多的基础能力,能看得懂图纸就行。
因为入门快,所以能很快体会到搭积木的乐趣。
学东西亦是如此,先感兴趣,然后能上手并有所收获,得到持续的满足感,可以帮助保持学习的热情。
我这次选择的方法是:
先实现功能,然后根据实现的结果代码,倒推每一步实现思路。
CodeArts Snap 的编程之路
想要实现结果倒推结果,首先需要有工具能帮助生成结果。
正好,前几天体验了华为云的智能编程助手 CodeArts Snap,挺方便好用的。
所以,我准备借助 CodeArts Snap 帮助智能生成代码。
小试牛刀:查看表格的统计数据
CodeArts Snap 用起来挺方便的,在 PyCharm 中安装好插件,登录华为云的账户(前提是已经成功申请试用)。
新增 py 文件,在文件中加入功能注释,然后单击"return"键,便可以自动生成代码。
下面,我们来实验一个"查看表格的统计数据"的功能。
数据表格
| 日期 | 销量 |
| 2023/6/1 | 2742.8 |
| 2023/6/2 | 3014.3 |
| 2023/6/3 | 5 |
| 2023/6/4 | 865 |
| 2023/6/5 | 3036.8 |
| 2023/6/6 | 44 |
功能注释
CodeArts Snap 支持中英文双语注释,我一般会采用中文注释:
"""
实现一个函数并打印函数结果:
1、读取Excel表格,指定表格中的"日期"列为索引列;
2、返回描述性统计数据。
:return:
"""生成代码
在注释下方,单击"return"键,便可以自动生成代码。
import pandas
def read_excel(file_name):
data = pandas.read_excel(file_name)
return data
def describe_data(data):
print(data.describe())函数调用
上面的代码其实不太完美,没有自动生成函数调用的代码(也许我没有加对正确的注释),于是我自己加了一行:
describe_data(read_excel('abnormal.xlsx'))运行结果
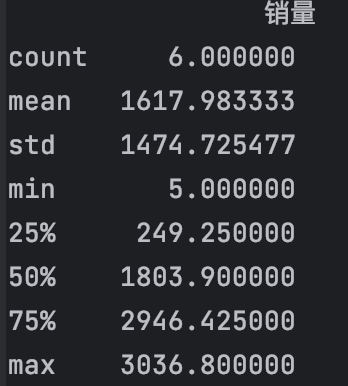
运行结果中每个值的释义如下:
count:观测的计数
mean:平均值
std:标准差
min:最小值
25%:1/4分位数
50%:1/2分位数
75%:3/4分位数
max:最大值
代码解析
因为我实验的这个功能相对简单,所以代码解析起来也不费劲。
这次代码实现的关键在于 pandas 库,借助它读取Excel文件并打印统计数据信息。
# pandas是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,建立在Python编程语言之上
import pandas
# 文件读取函数
# 根据文件名读取Excel文件,并返回读取到的数据
def read_excel(file_name):
# read_excel:pandas 提供的读取Excel文件的函数
data = pandas.read_excel(file_name)
return data
# 打印统计数据信息函数
# 根据文件数据,打印统计数据信息
def describe_data(data):
# describe 函数:生成描述性统计数据,总结数据集分布的集中趋势,分散和形状。
print(data.describe())注:想了深入了解 pandas,可以单击pandas 官网查看更多。
升级挑战:获取统计数据中的极差
极差公式
极差 = 最大值 - 最小值
功能注释
"""
实现一个函数:
1、读取Excel表格;
2、获取表格的描述性统计数据ds;
3、获取ds的最大值减去最小值的差值range,打印range。
:return:
"""生成代码
这个代码里,有两个小瑕疵:
- 把最大值和最小值都打印了,注释中没有写需要打印这两个值,说明对注释解析的还不够透彻;
- 虽然加了注释,但是注释加的不准确。
def get_min_max(file_name):
# 打开文件
data = pandas.read_excel(file_name)
# 获取表格的描述性统计数据
ds = data.describe()
# 获取表格的最大值去最小值的差值range,打印range
print(ds.loc['max'])
print(ds.loc['min'])
# 返回表格的最大值去最小值的差值range,打印range
print(ds.loc['max'] - ds.loc['min'])函数调用
get_min_max('abnormal.xlsx')运行结果
这个结果还是相对符合预期的

代码解析
def get_min_max(file_name):
# 打开文件,获取Excel文件的数据,保存到data中
data = pandas.read_excel(file_name)
# 获取表格的描述性统计数据,保存到ds中
ds = data.describe()
# loc:通过标签或布尔数组访问一组行和列。
# 打印描述性统计数据中的最大值
print(ds.loc['max'])
# 打印描述性统计数据中的最小值
print(ds.loc['min'])
# 打印最大值去最小值的差值
print(ds.loc['max'] - ds.loc['min'])总结
通过"结果倒推过程"的方式,实验过程充满乐趣,让我对较为陌生的知识的抵触感降低了很多。
CodeArts Snap 的功能很强大,可以快速帮忙生成代码,同时也是帮助开发者学习技术的一大助力。
优化建议
不过,在体验过程中,也发现了一些使用上的不方便的地方,整理了几个优化建议。
1、功能准确性还有待提升
有时候会出现代码不全的情况,有时候,代码结尾出现一个多出来且没有写完全的"if"语句

2、功能匹配的精度还有待提升
有时候,代码会比注释描述的内容多很多,且会出现重复循环的代码。

作者:非职业「传道授业解惑」的开发者叶一一
简介:「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。
如果看完文章有所收获,欢迎点赞👍 | 收藏?? | 留言📝。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringMVC执行流程
- pod进阶:
- return,break,continue
- Pytorch的GPU版本安装,在安装anaconda的前提下安装pytorch
- HOJ 项目部署-前端定制 默认勾选显示标签、 在线编辑器主题和字号大小修改、增加一言功能 题目AC后礼花绽放
- gif动图怎么快速生成?这一招快速生成
- STC8H系列单片机入门教程之NVC系列语音播报模块(九)
- Universal asynchronous receiver transmitter (UART)
- Redis设计与实现之简单的动态
- DockerFile