spark的任务提交方式及流程
发布时间:2024年01月05日
本地模式
local
测试用,不多赘述
分布式模式
standalone
standalone集群是spark 自带的一个资源调度集群,分为两个角色,master/worker,master负责接收任务请求、资源调度(监听端口7077),worker负责运行executor
在提交任务前需要将spark集群启动好/start-all.sh,而且它有自己的webUi,http://xx:8080,这种模式下spark是可以不依赖hadoop的
client
Driver 是在 SparkSubmit 进程中
spark-submit任务会等任务结束之后才退出,因为driver负责切分stage,封装task交给executor运行,但是这个任务提交是有先后顺序的,task必须从头到尾依次提交,所以spark-submit任务会等任务结束才退出。

cluster
Driver 是在 Worker 节点上运行
随机挑选一个Worker执行Driver,因此如果你想在driver中使用本地资源文件,你需要保证所有的worker上都有你这个资源文件,或者说使用外部文件系统

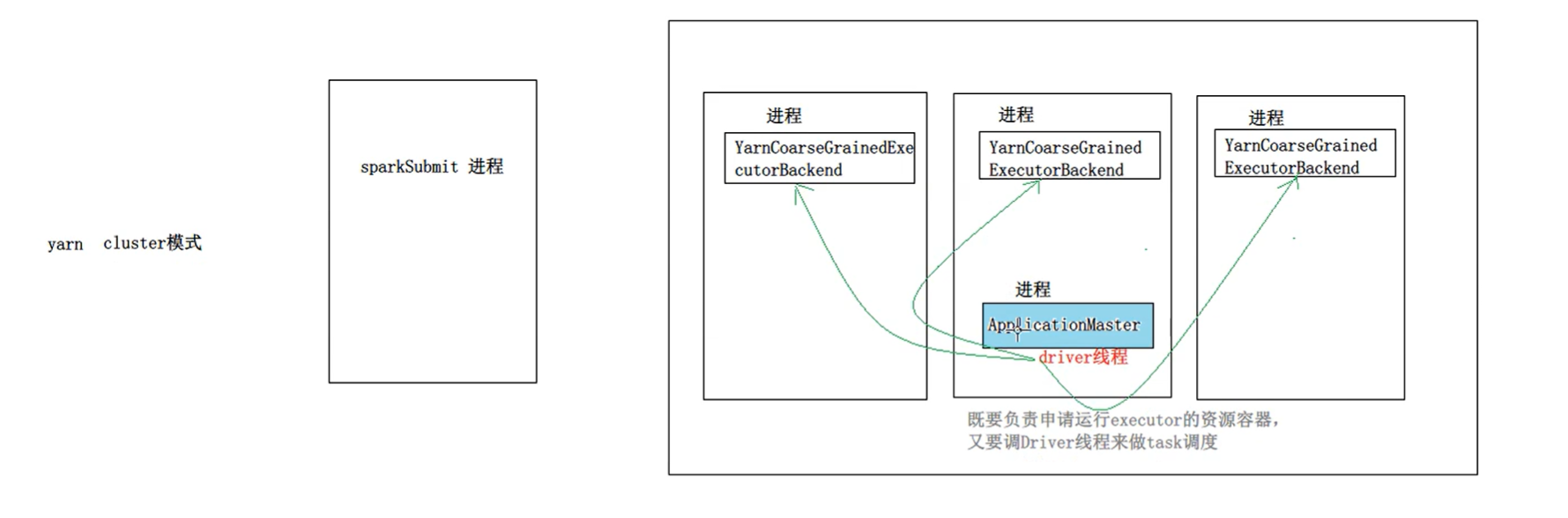
yarn
client
Driver 是在 SparkSubmit 进程中

cluster
Driver 是在 ApplicationMaster 进程中
文章来源:https://blog.csdn.net/java_creatMylief/article/details/129545404
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!