Java 第13章 常用类 课堂练习
文章目录
三元运算符输出结果
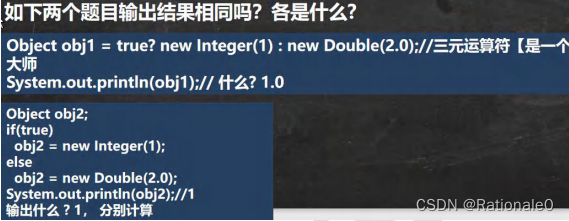
第一个输出1.0,因为三元运算符是一个整体,冒号后的double类使得整体精度提升;第二个输出1,正常情况。
包装类的 == 问题

new Integer(1) (然鹅,现在已经不支持new Integer()了…)创建对象,i == j中的 == 是判断是否是同一个对象,很明显不是,i == j 为false。
Integer m = 1;使用Integer中valueOf方法,其底层源码如下,可知:
- 如果 i 在 IntegerCache.low(-128)~IntegerCache.high(127),就直接从数组返回(其实就是直接返回原值);
- 如果不在 -128~127,就直接 new Integer(i)
所以 m == n 为true,x == y 为false
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
拓展:

示例5:i9返回值127,i10返回对象,故false;
示例6、7:只要有基本数据类型,比较的就是两个的值是否相同,故true。
String类对象内存问题1

a == b 为true,因为两个的地址是相同的,内存情况如下图:
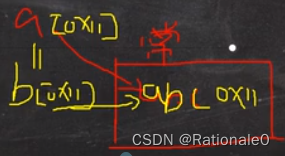
String类对象内存问题2

a指向常量池中的“hsp”;b指向堆中对象(value),由value在指向堆中的对象,两者指向不一样,所以 a == b 是false
当调用intern方法时,如果池已经包含一个等于此 String 对象的字符串(用equals(Object)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此 String对象的引用。即: intern()方法最终返回的是常量池的地址(对象)
已知a为常量池的地址,b为堆中的地址,故a == b.intern()为true,b == b.intern()为false。
String类对象内存问题3

p1.name == "hspedu"中,"hspedu"返回的地址就是常量池中的地址,所以true。
s1和s2分别指向堆中自己的value,所以只有最后一个为false。
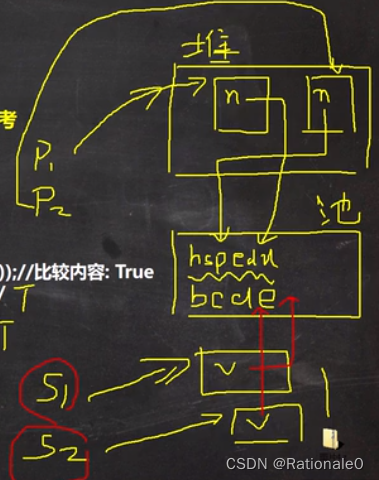
String类对象内存问题3
题目1

创建了2个。先在常量池中创建“hello”,s指向它;之后由于之前常量池中没有“haha”,现在常量池中创建然后s指向“haha”

题目2

编译器不傻,会做优化,即判断创建的常量池对象 是否有引用指向。
String a = “hello” +“abc”; 会自动解释为 String a = “helloabc”;所以只创建了一个对象。字符串常量相加,直接看池地址。
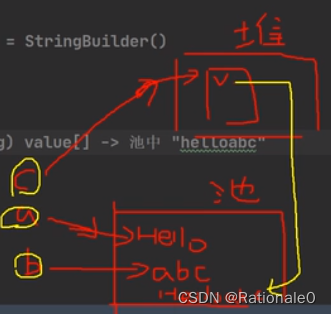
题目3

c是如何创建的:
1.先创建一个StringBuilder sb = StringBuilder()
2.执行sb.append(“hello”);
3. sb.append(“abc”);
4. String c= sb.toString()
最后其实是 c指向堆中的对象(String) value[] ->池中“helloabc"
韩老师启示:一定要靠看源码来学习
题目4
判断内存图和输出:

只要调用方法(change)就会产生新栈。str = "java"的时候,str直接从指向堆中的value 改为 指向常量池中新创建的“java”;同时,堆中ch的第一个元素被改为h。change调用结束后,新栈立刻销毁,此时ex.str仍然指向堆中的value,value指向最初的hsp;ex.ch则是会输出hava。
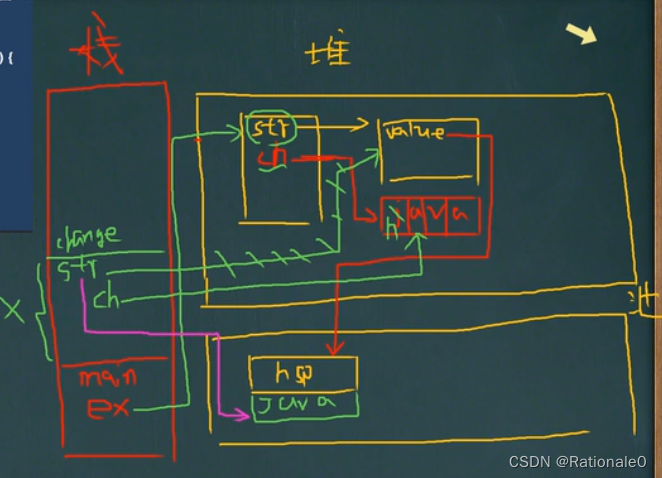
String使用注意说明:
string s=“a”;1/创建了一个字符串
s +=“b”;//实际上原来的"a"字符串对象已经丢弃了,现在又产生了一个字符串s+“b”(也就是"ab”)。如果多次执行这些改变串内容的操作,会导致大量副本字符串对象存留在内存中,降低效率。如果这样的操作放到循环中,会极大影响程序的性能。结论: 如果我们对String做大量修改,不要使用String
StringBuffer问题

看底层源码可知。结果如下:
4
null
// new StringBuffer时报错
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大模型微调LoRA训练与原理
- 河南工程学院第六届程序设计竞赛-A组-题解
- 【深度学习】序列生成模型(五):评价方法计算实例:计算BLEU-N得分【理论到程序】
- TCP协议传输中的粘包和拆包
- 【C语言(十六)】
- RT-Thread基于AT32单片机的485应用开发(二)
- STM32微控制器在HC-SR501红外感应模块中的能耗优化策略研究
- 怎么快速定位bug?如何编写测试用例?
- 【Docker篇】使用Docker操作镜像
- 计算机网络应用层(期末、考研)