Kafka消费者组
消费者总体工作流程
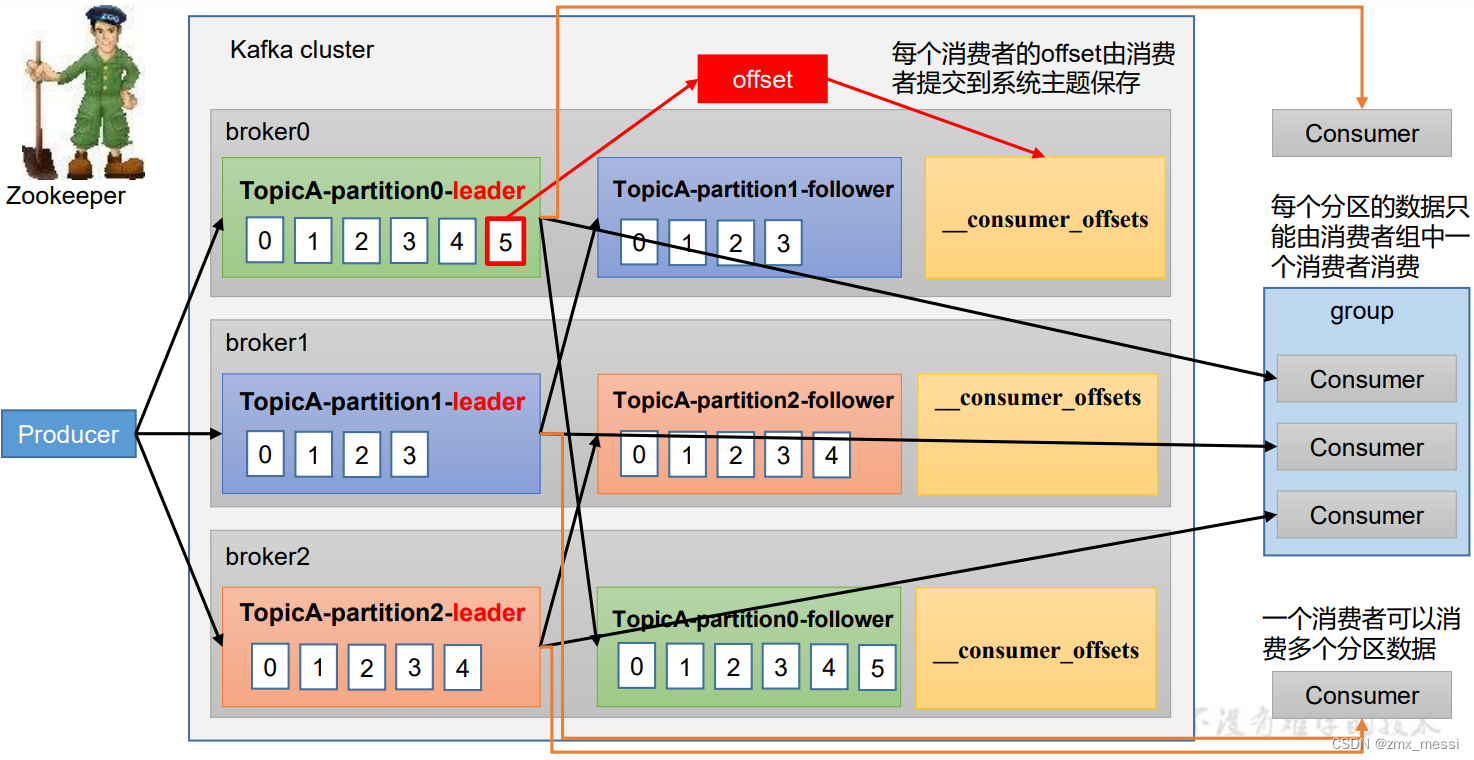
????????Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
? 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
? 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
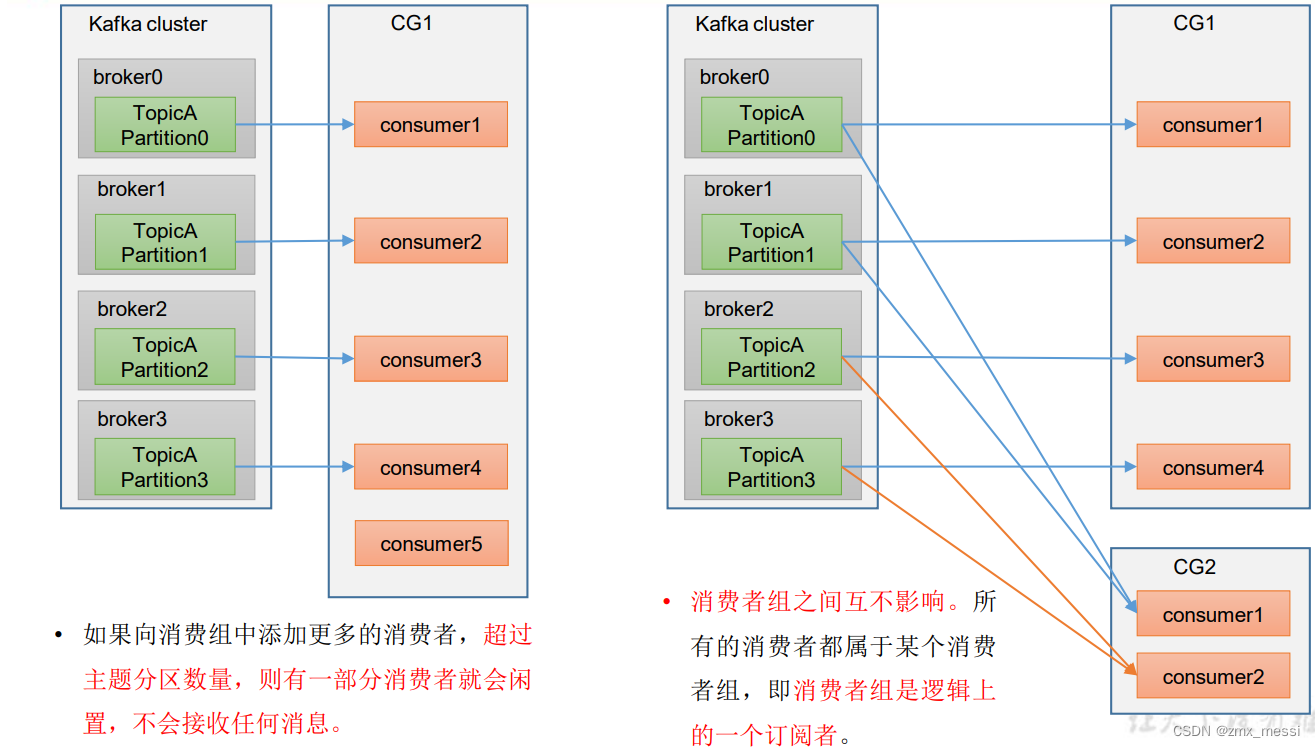
消费者组初始化流程
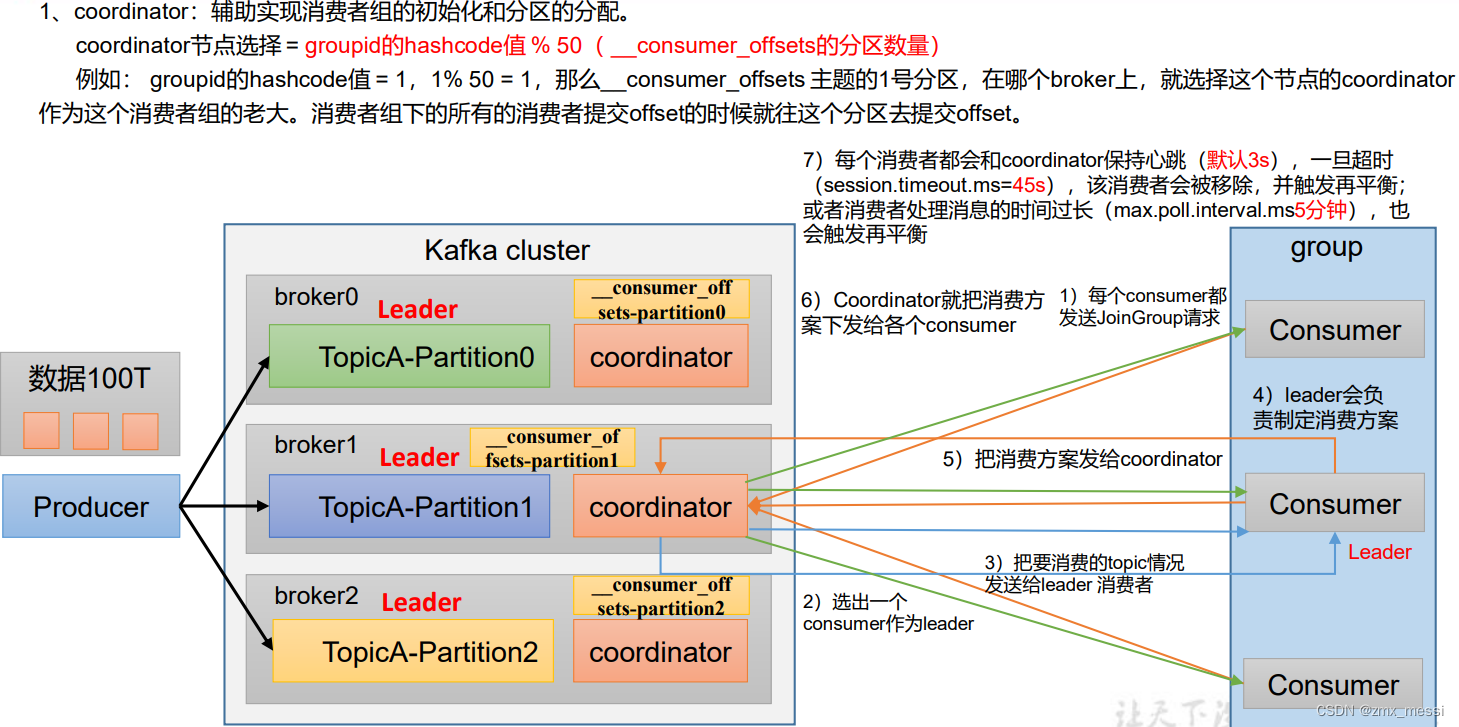
????????1、coordinator:辅助实现消费者组的初始化和分区的分配。 coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量) 例如: groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator 作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset;
? ? ? ? 2、coordinator选出一个 consumer作为leader;
????????3、coordinator把要消费的topic情况发送给leader消费者;
????????4、leader会负责制定消费方案;
? ? ? ? 5、把消费方案发给coordinator;
????????6、Coordinator就把消费方 案下发给各个consumer;
????????7、每个消费者都会和coordinator保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡; 或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也 会触发再平衡
消费者组详细消费流程
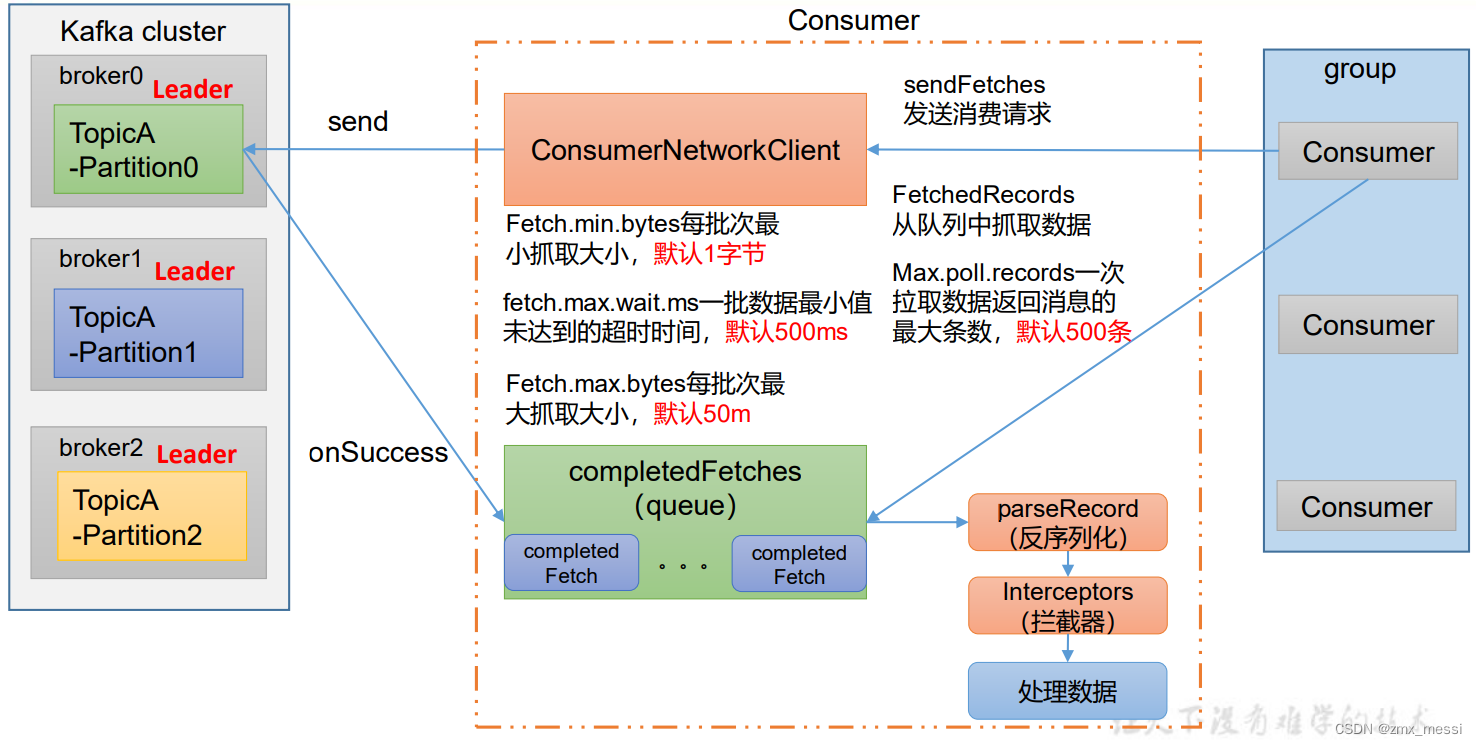
????????左侧为Kafka集群,右侧为消费者组,消费者创建网络连接客户端,消费者组调用sendFetches,抓取数据,同时还会准备两个参数,Fetch.min.bytes:每批次最小抓取大小,默认1字节,fetch.max.wait.ms一批数据最小值未达到的超时时间,默认500ms,任一条件满足,都会拉取数据;Fetch.max.bytes每批次最 大抓取大小,默认50m
? ? ? ? send->拉取数据将数据放进completedFetches队列,消费者一批次拉取默认500条进行处理:反序列化->拦截器->处理数据
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
//配置
Properties properties = new Properties();
//链接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//1.创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//2。订阅主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
//3.消费数据
while(true){
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));//拉数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord);
}
}
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络总是宕机,这个绝招必须收藏!
- 探寻数据压缩——第一代小波构造的统一框架
- 【无标题】
- 智能助手的巅峰对决:ChatGPT对阵文心一言
- MySQL8主从复制之一主一从实战
- Compose——下拉刷新、上拉加载更多
- 全局代理IP的工作原理和实现方法
- 日志切割,如果mv elink.log 20231220/elink.log.2023120 ,filebeat不会继续采集
- 【Linux系统编程二十六】:线程控制与线程特性(Linux中线程库/线程创建/线程退出/线程等待)
- Erlang、RabbitMQ下载与安装教程(windows超详细)