YOLO-NAS姿态简介:姿态估计技术的飞跃
文 | BFT机器人?

YOLO-NAS姿态模型是对姿态估计领域的最新贡献。今年早些时候,Deci凭借其开创性的物体检测基础模型YOLO-NAS获得了广泛认可。在YOLO-NAS成功的基础上,该公司现在推出了YOLO-NAS Pose作为其姿态估计的对应产品,这种姿势模型在延迟和准确性之间提供了很好的平衡。

YOLO-NAS姿势
姿态估计在计算机视觉中起着至关重要的作用,涵盖了广泛的重要应用。这些应用包括监测医疗保健中的患者运动、分析运动员在运动中的表现、创建无缝的人机界面以及改进机器人系统。
01
YOLO-NAS姿态模型架构
2.1?基于规划空间的分类及特点
传统的姿态估计模型遵循以下两种方法之一:
-
检测场景中的所有人物,然后估计其关键点并创建姿势,自上而下的两阶段过程;
-
检测场景中的所有关键点,然后生成姿势,自下而上的两阶段过程。
YOLO-NAS Pose与传统的Pose Estimation模型相比,其工作方式有所不同。它不是先检测人,然后估计他们的姿势,而是可以在一个步骤中同时检测和估计人及其姿势。
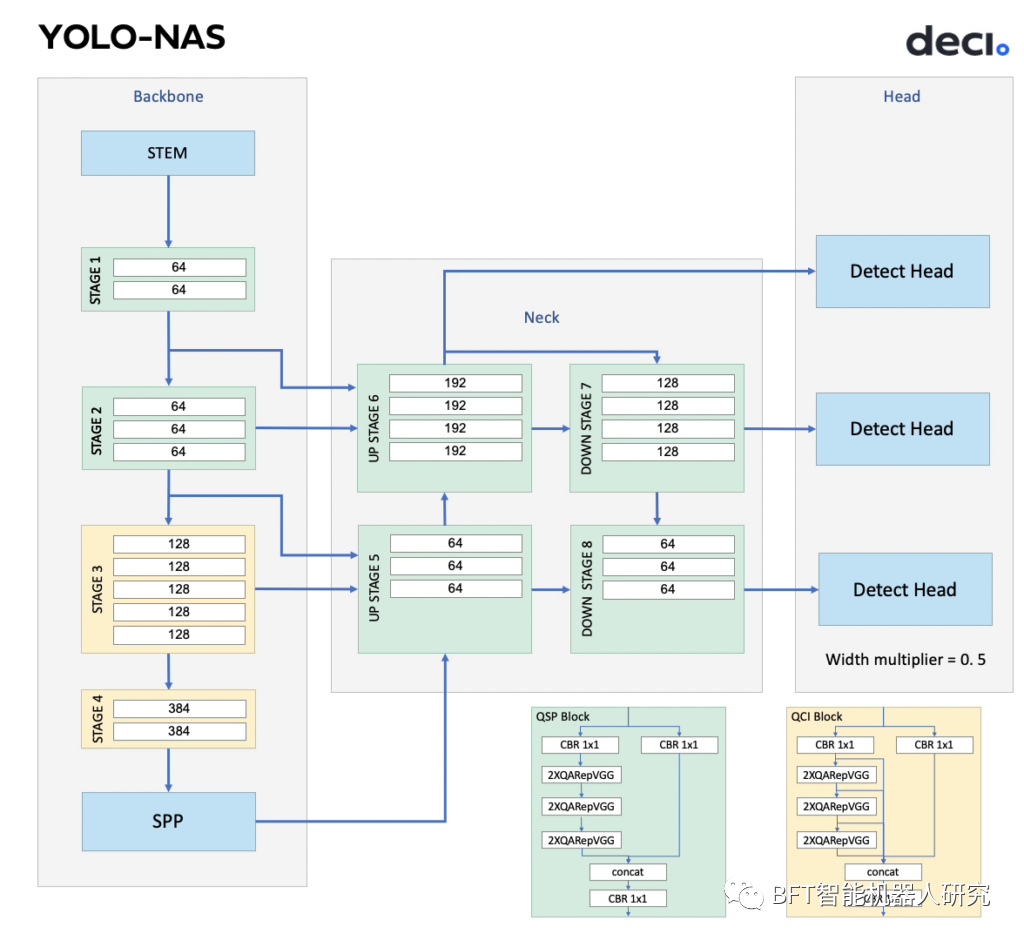
YOLO-NASPose架构–骨干和颈部设计
姿势模型建立在YOLO-NAS目标检测架构之上,目标检测模型和姿态估计模型具有相同的脊柱和颈部设计,但头部不同。YOLO-NAS?Pose的头部专为其多任务目标而设计,即检测单个类别的物体(如人或动物)并估计物体的姿势。

YOLO-NAS Pose架构–头部设计
这种令人印象深刻的组合是Deci专有的神经架构搜索(NAS)引擎AutoNAC的结果,它在广阔的架构搜索空间中导航并返回最佳架构设计。以下是搜索的超参数:
-
姿势和框回归路径的Conv-BN-Relu块数;
-
两条路径的中间通道数;
-
在姿势/框回归的共享词干或不同词干之间做出决定。
YOLO-NASPose模型在COCOVal2017数据集上进行评估,该模型的准确性和延迟是最先进的。nano模型速度最快,在T4GPU上达到高达425fps的推理速度,同时大模型可以达到113fps。

COCOVal2017数据集上的YOLO-NAS姿态评估
02
YOLO-NAS与YOLOv8姿势
2.1?基于规划空间的分类及特点
下图是YOLO-NAS Pose和YOLOv8Pose模型的精度延迟权衡。这个空间也被称为效率前沿。所有模型均在COCOVal2017数据集和英特尔至强第四代CPU上进行评估,具有1个批处理大小和16位浮点运算。
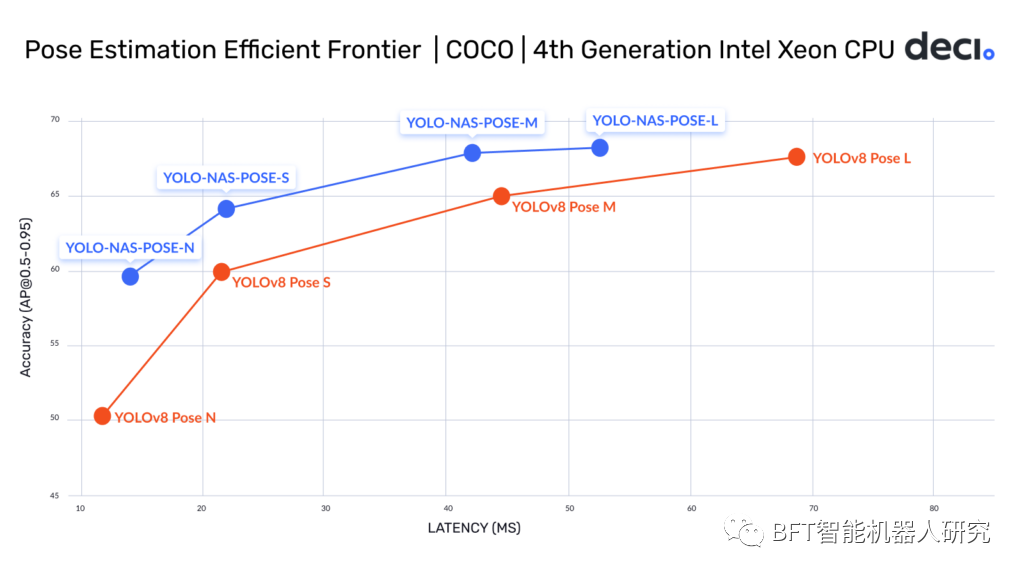
YOLO-NAS姿势与YOLOv8姿势高效前沿图
所有YOLO-NAS Pose模型的精度都高于YOLOv8 Pose模型,这可以被认可到AutoNAC的头部设计中,具体的细节是:
-
较小的YOLO-NAS Pose模型,即nano和small,虽然精度更高,但比YOLOv8Pose模型慢。
-
较大的YOLO-NAS Pose型号,如中型和大型,在准确性和延迟方面都更好。
03
姿势模型是如何训练的?
2.1?基于规划空间的分类及特点
YOLO-NAS姿态损失功能
为了确保模型有效地学习这两个任务,Deci改进了训练中使用的损失函数。我们不仅考虑了分配框的IoU(交集与并集)分数,还合并了对象关键点相似性(OKS)分数,该分数将预测的关键点与实际的关键点进行比较,此更改鼓励模型对边界框和姿态估计进行准确预测。
此外,还采用了直接OKS回归技术,超越了传统的L1/L2损失方法,这种方法具有以下几个优点:
-
它在0到1的范围内运行,类似于框IoU,表示姿势的相似程度。
-
它考虑了注释特定关键点的不同难度,每个关键点都与唯一的sigma分数相关联,该分数反映了注释和数据集细节的准确性,分数决定了模型因做出不准确的预测而受到的惩罚程度。
-
使用与验证指标一致的损失函数,这反过来又允许对指标进行定位和优化。

YOLO-NAS姿态估计
训练超参数
由于YOLO-NAS Pose采用了与YOLO-NAS模型类似的基础结构,因此在进行最终训练之前,使用YOLO-NAS的预训练权重来初始化模型的骨架和颈部。以下是训练超参数:
-
训练硬件:使用了8个NVIDIAGeForceRTX3090GPU和PyTorch2.0。
-
培训计划:培训进行了长达1000个epoch,如果在过去100个epoch中表现没有改善,则提前停止。
-
优化器:采用具有余弦LR(学习率)衰减的AdamW,在训练结束时将LR降低0.05倍。
-
权重衰减:应用了0.000001的权重衰减因子,不包括偏差层和BatchNorm层。
-
EMA(指数移动平均线)衰减:使用50的beta因子进行EMA衰减。
-
图像分辨率:图像经过处理后,最大边长为640像素,填充分辨率为640×640,填充颜色为(127,127,127)。
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C++初阶】第二站:类与对象(上) -- 下部分
- 239. 滑动窗口最大值
- 自动驾驶学习笔记(十七)——视觉感知
- 手把手教你搭建3D元宇宙场景!
- 径向基函数插值
- TCP协议传输中的粘包和拆包
- 2024最新最全【CTF攻防夺旗赛教程】,零基础入门到精通
- 面向企业人力资源管理网上智能考勤系统(JSP+java+springmvc+mysql+MyBatis)
- Java基础面试题(三)
- 02、Kafka ------配置 Kafka 集群