运用AI翻译漫画(三)
运行程序
好啦,大功告成!现在要做的事就是点击F5来编译执行程序。如果一切顺利的话,将会看到界面设计部分所展示的窗口。
我们第一步先点击”Show”按钮,会得到:
再点击”OCR”按钮,等两三秒(取决于网络速度),会看到左侧图片中红色的矩形围拢的一些文字。有些文字没有被识别出来的话,就没有红色矩形。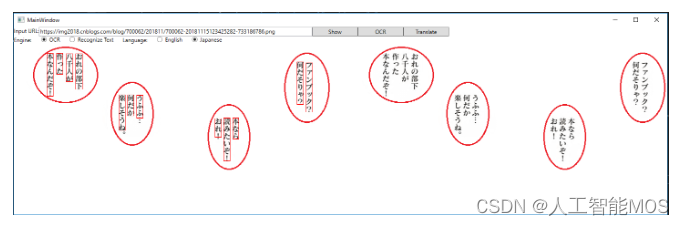
最后点击”Translate”按钮,稍等一小会儿,会看到右侧图片的变化:
Wow! 大部分的日文被翻译成了中文,而且位置也摆放得很合适。
习题与进阶学习
增加容错代码让程序健壮
目前的代码中没有很多容错机制,比如当服务器返回错误时,访问API的代码会返回一个NULL对象,在上层没有做处理,直接崩溃。再比如,当用户不按照从左到右的顺序点击上面三个button时,会产生意想不到的情况。
改进本应用让其自动化和产业化
本应用处理单页的漫画,并且提供了交互,目的是让大家直观理解工作过程,实际上这个过程可以做成批量自动化的,也就是输入一大堆URL,做后台识别/翻译/重新生成图片后,把图片批量保存在本地,再进行后处理。
当然,识别引擎不是万能的,很多时候不可能准确识别/翻译出所有对白文字。所以,可以考虑提供一个类似本应用的交互工具,让漫画翻译从业者在机器处理之后,对有错误的地方进行纠正。
小提示:请严格遵守知识产权保护法!在合法的情况下做事。
使用新版本的Engine做字符识别
还记得前面提到过新旧引擎的话题吗?我们在界面上做了一个Radio Button “Recognize Text”,但是并没有使用它。因为这个新引擎目前还只能支持英文的OCR,所以,如果大家对漫威Marvel漫画(英文为主)感兴趣的话,就可以用到这个引擎啦,与旧OCR引擎相比,不能同日而语,超级棒!
旧OCR引擎的文档在这里:Microsoft Cognitive Services
新Recognize Text引擎的文档在这里:
新的引擎在API交互设计上,有一个不同的地方:当你提交一个请求后,服务器会立刻返回Accepted (202),然后给你一个URL,用于查询状态的。于是需要在客户端程序里设个定时器,每隔一段时间(比如200ms),访问那个URL,来获得最终的OCR结果。
返回的结果JSON格式也有所不同,大家可以自己试着实现一下:
聚类处理待翻译的文字
观察力好的同学,可能会发现一个问题,如下图所示,左侧图的一个对白气泡里,有四句话,但其实它们是一句话,分开写到4列而已。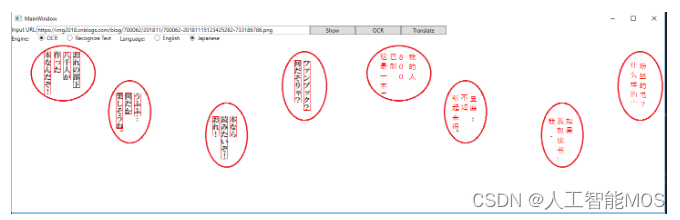
这种情况带来的问题是:这四句话分别送给翻译引擎做翻译,会造成前后不连贯,语句不通顺。可以考虑的解决方案是,先根据矩形的位置信息,把这四句话合并成同一句话,再送给翻译引擎。这就是标准的聚类问题,通过搜索引擎可以找到一大堆参考文档,比如这些:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- csrf和ssrf的区别,攻击如何防护
- QT上位机开发(通讯协议的编写)
- 阿里云弹性网络接口技术的容器网络基础教程
- Egg框架搭建后台服务【4】- 密码加密校验
- x-cmd pkg | procs - ps 命令的现代化替代品
- 怎么检查直线模组的故障?
- IDEA插件中的Postman!
- 【产品测试】Bug报告的四个元素,你知道吗?
- 通达OA general/score/flow/scoredate/result.php接口存在SQL注入漏洞 附POC软件
- Java 队列(Queue)简介与经典例子