cnstd使用效果测试
发布时间:2024年01月04日
使用参考:https://github.com/breezedeus/CnSTD/tree/master
原理参考:https://cnocr.readthedocs.io/zh/latest/intro-cnstd-cnocr.pdf
模型:
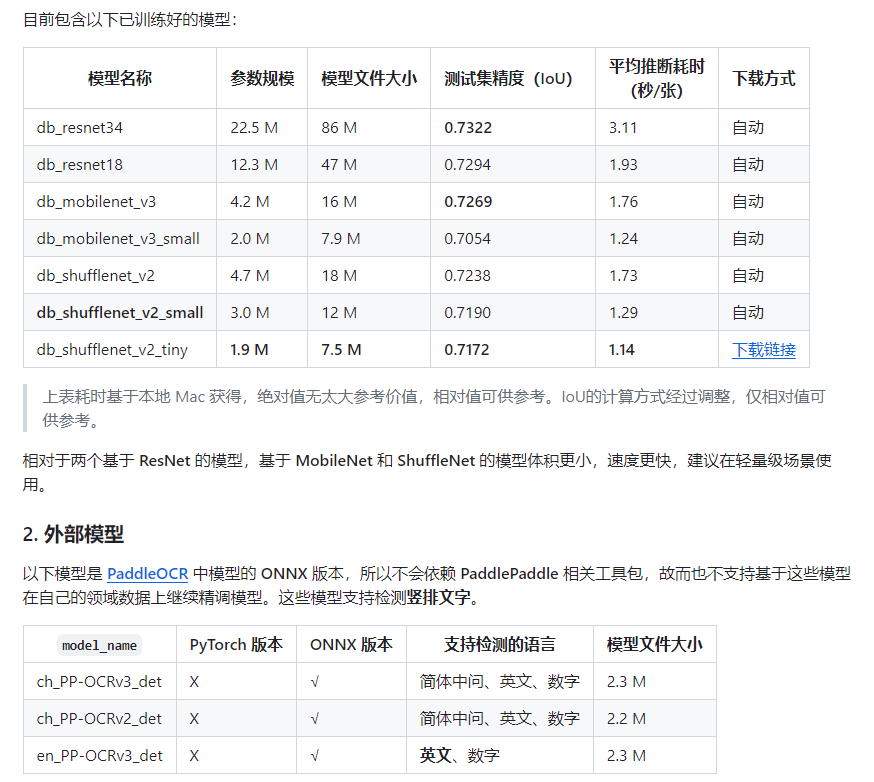
结论:
经过测试, 长文本检测效果不错,短文本可能角度不对

from cnstd import CnStd
import cv2
from cnocr import CnOcr
#文字检测模型使用的是 DBNet
std = CnStd(
model_name='db_resnet34',
auto_rotate_whole_image=True,
rotated_bbox=False,
context ='cpu',
model_fp=None,
model_backend='onnx', # ['pytorch', 'onnx']
root = r'E:\db_resnet34-pan\db_resnet34', #模型文件所在的根目录。
use_angle_clf=False,#对于检测出的文本框,是否使用角度分类模型进行调整
angle_clf_configs=None
)
cn_ocr = CnOcr()
image_org = cv2.imread(r'xxxx.jpg')
box_info_list = std.detect(
img_list=image_org,
resized_shape = (image_org.shape[0]//8,image_org.shape[1]//8), # 这个取值对检测结果的影响较大,可以针对自己的应用多尝试几组值,再选出最优值。例如 (512, 768), (768, 768), (768, 1024)等。
preserve_aspect_ratio = True,#
min_box_size = 8,
box_score_thresh = 0.3,
batch_size = 20,
)#
image_list = [x['cropped_img'] for x in box_info_list['detected_texts']]
for i,image in enumerate(image_list):
ocr_res = cn_ocr.ocr_for_single_line(image)
print('ocr result: %s' % str(ocr_res))
cv2.imwrite(str(i)+'.jpg', image)
文章来源:https://blog.csdn.net/weixin_38235865/article/details/135389891
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!