shell编程-3
文章目录
shell学习第三天
while 循环
循环就是做重复的事情
for:
- for i in {1…20}
- for i in $(seq $1)
- for i in $@
- for i in /boot/* 循环boot下的所有文件夹
[root@gh-shell 1-13]# cat for.sh
#!/bin/bash
for i in {1..10}
do
mkdir -p gao$i
done
#位置变量
for i in $(seq $1)
do
mkdir -p fei$i
done
#所有的位置变量
for i in $@
do
mkdir -p $i
done
#指定一个文件夹的路径
for i in /boot/*
do
echo "sanchaung $i"
done
[root@gh-shell 1-13]#
[root@gh-shell 1-13]#
[root@gh-shell 1-13]# bash for.sh 3 gaohui gaofei jiang ding
sanchaung /boot/config-3.10.0-1160.el7.x86_64
sanchaung /boot/efi
sanchaung /boot/grub
sanchaung /boot/grub2
sanchaung /boot/initramfs-0-rescue-c006f125490d4e4abd655f2202c54dec.img
sanchaung /boot/initramfs-3.10.0-1160.el7.x86_64.img
sanchaung /boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
sanchaung /boot/symvers-3.10.0-1160.el7.x86_64.gz
sanchaung /boot/System.map-3.10.0-1160.el7.x86_64
sanchaung /boot/vmlinuz-0-rescue-c006f125490d4e4abd655f2202c54dec
sanchaung /boot/vmlinuz-3.10.0-1160.el7.x86_64
[root@gh-shell 1-13]# ls
3 fei1 fei3 gao1 gao2 gao4 gao6 gao8 gaofei jiang
ding fei2 for.sh gao10 gao3 gao5 gao7 gao9 gaohui
[root@gh-shell 1-13]#
$# 位置变量的个数
$* 所有位置变量的内容
$@ 所有位置变量的内容
while:
- 控制次数的循环
- 死循环
控制次数 break contune
[root@gh-shell 1-13] cat while.sh
#!/bin/bash
i=1
while (( i<10 ))
do
echo "sanchuang $i"
sleep 1
(( i++ ))
if (( i==6 ));then
#break
continue
fi
echo "gaohui $i"
done
[root@gh-shell 1-13]#
死循环 true 和 : 是一样的
[root@gh-shell 1-13] cat while2.sh
#!/bin/bash
i=1
while true
do
echo "sanchaung $i"
((i++))
sleep 1
if (( i==5 ));then
break
fi
done
[root@gh-shell 1-13]#
[root@gh-shell 1-13] cat while2.sh
#!/bin/bash
i=1
while :
do
echo "sanchaung $i"
((i++))
sleep 1
if (( i==5 ));then
break
fi
done
[root@gh-shell 1-13]#
找出语文成绩大于等于90分的人,输出他的名字和语文成绩
[root@gh-shell 1-13] cat grade.txt
name chinese math english
cali 80 91 82
tom 90 80 99
lucy 99 70 75
jack 60 89 99
[root@gh-shell 1-13] cat grade.txt|awk '$2 >=90{print $1,$2}'
name chinese
tom 90
lucy 99
[root@gh-shell 1-13]#
[root@gh-shell 1-13] bash while3.sh
tom 90
lucy 99
[root@gh-shell 1-13] cat while3.sh
#!/bin/bash
while read uname chinese math english
do
#对chinese成绩进行判断,大于等于90的就输出
if [[ $uname == "name" ]];then
continue
fi
if (( $chinese >=90 ));then
echo "$uname $chinese"
fi
done < grade.txt
[root@gh-shell 1-13]#
也可以:
[root@gh-shell 1-13] cat while3.sh
#!/bin/bash
cat grade.txt|while read uname chinese math english
do
#对chinese成绩进行判断,大于等于90的就输出
if [[ $uname == "name" ]];then
continue
fi
if (( $chinese >=90 ));then
echo "$uname $chinese"
fi
done
[root@gh-shell 1-13]#
第一天的小游戏
'编写一个抽奖程序,先随机产生一个中奖号码 在10以内,然后让用户去猜,顺便统计一下猜的次数,没用猜中就一直,如果在三次以内猜中的,输出你是天才,三次以上的就输出运气不好。'
[root@gh-shell 1-13]# cat lucky_game.sh
#!/bin/bash
#产生一个随机数
lucky_num=$((RANDOM%10))
#计数器
count=1
#游戏程序
while true
do
read -p "请输入你的中奖号码:" num
if (( $num==$lucky_num ));then
echo "恭喜你猜中了号码,中了500大奖"
if (( count<4 ));then
echo "你是天才,累计猜了 $count 次"
else
echo "运气不佳,累计猜了 $count 次"
fi
break
else
echo "对不起,请继续猜中奖号码"
if (( $num > $lucky_num ));then
echo "大了"
else
echo "小了"
fi
fi
#增加猜的次数
((count++))
done
练习: 编写抽同学回答问题的脚本
编写抽同学回答问题的脚本answer.sh,定义一个名单name.txt,然后从名单里抽取同学的名字,抽过的不再抽
[root@gh-shell 1-13] cat name.txt
高辉
高菲
张渊
胡亚
唐荣
张宇
高琛茗
高定江
高铭雪
史名龙
李忠奇
朱俊学
宋长爱
[root@gh-shell 1-13]#
'抽中的同学存放到另一个文件里 a_name.txt'
[root@gh-shell 1-13] cat answer.sh
#!/bin/bash
#描述:这是一个抽同学名字的脚本
#作者:gh
#time: 2024-1-13
#mail: 3515979791@qq.com
#公司: 不冤不乐
#先统计name.txt文件里用户的数量,然后产生一个随机数,根据这个数字抽取name.txt文件里对应的行的同学名字
#知道name.txt有多少行
total_line=$(cat name.txt|wc -l)
while true
do
#得到保存已经抽过奖的同学文件a_name.txt的总行数
total_a_name_line=$(cat a_name.txt|wc -l)
if (( $total_line == $total_a_name_line ));then
echo "所有的同学已经抽完了,重新开始抽同学"
#清空一下a_name.txt文件
>a_name.txt
break
fi
#得到一个name.txt文件里的一个随机的行数
lucky_num=$((RANDOM%total_line + 1))
#得到对应的行的人的名字
sname=$(cat name.txt|head -n $lucky_num|tail -1)
#输出中奖同学的名字,使用grep去a_name.txt文件里查找是否已经抽取过了
if grep "$sname" a_name.txt &>/dev/null ;then
echo "$sname 同学已经抽过了,继续抽奖"
sleep 1
else
echo "请 $sname 同学回答问题"
#保存已经抽取的名字到a_name.txt
echo "$sname" >>a_name.txt
break
fi
done
要想让这个脚本永久有效
1.修改环境变量
[root@gh-shell 1-13] PATH=/shell/1-13/:$PATH
2.修改 ~/.bashrc 文件
在最后一行加上
PATH=/shell/1-13/:$PATH
3.给这个脚本加上可执行权限
[root@gh-shell 1-13] chmod +x answer.sh
[root@gh-shell 1-13] answer.sh
4.起一个别名,把别名放到 ~/.bashrc 文件夹下边
[root@gh-shell 1-13]# alias ans=answer.sh
[root@gh-shell 1-13]# ans
所有的同学已经抽完了,重新开始抽同学
在 ~/.bashrc 最后一行添加
alias ans=answer.sh
如何知道两个文件里的内存一样?
1.对比行数: wc -l 统计行数
2.hash值
3.diff
如何判断某个人已经抽过了
利用grep过滤查找
[root@gh-shell 1-13] cat name.txt
高辉
高菲
张渊
胡亚
唐荣
张宇
高琛茗
高定江
高铭雪
史名龙
李忠奇
朱俊学
宋长爱
[root@gh-shell 1-13] cat name.txt|grep "高"
高辉
高菲
高琛茗
高定江
高铭雪
[root@gh-shell 1-13]#
文本处理相关命令
seq
seq:用于生成数列,可以指定起始值、结束值和步长等参数。例如,生成1到10的数列:
seq 1 10
xargs
xargs:用于从标准输入中读取数据,并将其作为参数传递给其他命令。例如,使用xargs将标准输入的每一行作为参数传递给echo命令:
echo "apple banana cherry" | xargs echo
argumens 参数
xmen 很多
把一列的数据转换成一行
[root@gh-shell 1-13] seq 5
1
2
3
4
5
[root@gh-shell 1-13] seq 5|xargs
1 2 3 4 5
xargs是一个传递参数的命令
很像 |管道符号
[root@gh-shell gao] seq 5|xargs mkdir
[root@gh-shell gao] ls
1 2 3 4 5
[root@gh-shell gao]#
uniq
uniq:用于去除重复的行。可以与sort命令配合使用,先按需要的字段排序,再去除重复行。例如,去除文件file.txt中的重复行:
sort file.txt | uniq
[root@gh-shell 1-13]# cat test.txt
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
[root@gh-shell 1-13]# cat test.txt |sort
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaofei
gaofei
gaofei
gaohui
gaohui
gaohui
gaohui
gaohui
gaohui
[root@gh-shell 1-13]# cat test.txt |sort|uniq
gaodingjiang
gaofei
gaohui
[root@gh-shell 1-13]#
一般uniq和sort是一起用的,去重之前先sort一下。因为去重只能去连续的
选项:
-c 统计重复出现的次数
[root@gh-shell 1-13] cat test.txt |sort|uniq -c
6 gaodingjiang
3 gaofei
6 gaohui
[root@gh-shell 1-13]#
-u打印不重复的行
[root@gh-shell 1-13] cat test.txt |sort|uniq -u
gaofei1
[root@gh-shell 1-13]#
-d是打印出重复的行
[root@gh-shell 1-13] cat test.txt |sort|uniq -d
gaodingjiang
gaofei
gaohui
[root@gh-shell 1-13]#
sort
sort:用于排序文件的行。可以按照字典顺序或数值顺序进行排序,也可以根据特定字段进行排序。例如,按照数字大小对file.txt进行排序:
默认是根据第一个字母的ASCII的大小进行升序排列
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符。
sort -n file.txt
[root@gh-shell 1-13] cat test.txt
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
gaohui
gaodingjiang
gaohui
gaodingjiang
gaofei
[root@gh-shell 1-13] cat test.txt |sort
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaodingjiang
gaofei
gaofei
gaofei
gaohui
gaohui
gaohui
gaohui
gaohui
gaohui
[root@gh-shell 1-13]#
-n选项—>让字符串识别成数值去排序
[root@gh-shell ~] echo -e "123\n26\n3" | sort -n
3
26
123
[root@gh-shell ~]#
-r选项是降序排列
[root@gh-shell ~] echo -e "123\n26\n3" | sort -n -r
123
26
3
[root@gh-shell ~]#
[root@gh-shell ~] echo -e "123\n26\n3" | sort -nr
123
26
3
[root@gh-shell ~]#
-k 指定字段(哪一列)进行排序(最好加上-n)
[root@gh-shell 1-13] cat grade.txt |sort -k 2 -n
name chinese math english
jack 60 89 99
cali 80 91 82
tom 90 80 99
lucy 99 70 75
[root@gh-shell 1-13]#
[root@gh-shell 1-13] cat grade.txt |sort -k 2 -nr
lucy 99 70 75
tom 90 80 99
cali 80 91 82
jack 60 89 99
name chinese math english
[root@gh-shell 1-13]#
-t指定分隔符
[root@gh-shell 1-13] cat /etc/passwd|sort -t ":" -k 3 -nr
sc20:x:1019:1019::/home/sc20:/bin/bash
sc19:x:1018:1018::/home/sc19:/bin/bash
sc18:x:1017:1017::/home/sc18:/bin/bash
sc17:x:1016:1016::/home/sc17:/bin/bash
sc16:x:1015:1015::/home/sc16:/bin/bash
sc15:x:1014:1014::/home/sc15:/bin/bash
sc14:x:1013:1013::/home/sc14:/bin/bash
sc13:x:1012:1012::/home/sc13:/bin/bash
sc12:x:1011:1011::/home/sc12:/bin/bash
sc11:x:1010:1010::/home/sc11:/bin/bash
sc10:x:1009:1009::/home/sc10:/bin/bash
sc9:x:1008:1008::/home/sc9:/bin/bash
sc8:x:1007:1007::/home/sc8:/bin/bash
sc7:x:1006:1006::/home/sc7:/bin/bash
sc6:x:1005:1005::/home/sc6:/bin/bash
sc5:x:1004:1004::/home/sc5:/bin/bash
sc4:x:1003:1003::/home/sc4:/bin/bash
sc3:x:1002:1002::/home/sc3:/bin/bash
sc2:x:1001:1001::/home/sc2:/bin/bash
sc1:x:1000:1000::/home/sc1:/bin/bash
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
halt:x:7:0:halt:/sbin:/sbin/halt
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
sync:x:5:0:sync:/sbin:/bin/sync
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
tr
字符串转换的命令
tr:用于字符转换或删除。可以将输入中的字符进行替换或删除。例如,将文件file.txt中的所有小写字母转换为大写字母:
tr '[:lower:]' '[:upper:]' < file.txt
1.转换功能
[root@gh-shell 1-13] echo 112233
112233
[root@gh-shell 1-13] echo 112233|tr 123 abc
aabbcc
[root@gh-shell 1-13] echo 1122333333|tr 123 abc
aabbcccccc
[root@gh-shell 1-13] echo 1122333333123123|tr 123 abc
aabbccccccabcabc
2.删除功能
tr -d
-d delete删除
[root@gh-shell 1-13] df -Th|grep "/$"|awk '{print $6}'|tr -d "%"
5
[root@gh-shell 1-13]#
[root@gh-shell 1-13] echo "gaohui"
gaohui
[root@gh-shell 1-13] echo "gaohui"|tr -d "ah"
goui
[root@gh-shell 1-13]#
3.压缩功能
-s 压缩连续的字符串
[root@gh-shell 1-13]# echo 1111111111222222223333333333|tr -s 123
123
[root@gh-shell 1-13]#
cut
-c 指定字符串的长度
-f 指定字段数
-d 指定分隔符
cut:用于从文件的行中提取指定字段。可以指定分隔符和字段位置。例如,提取文件file.txt的第1列和第3列:
cut -f1,3 file.txt
截取字符串和列
1.截取字符串:
[root@gh-shell 1-13] echo "shemengjie"
shemengjie
[root@gh-shell 1-13] echo "shemengjie"|cut -c 1
s
[root@gh-shell 1-13] echo "shemengjie"|cut -c 1-5
sheme
[root@gh-shell 1-13] echo "shemengjie"|cut -c 5-10
engjie
-7是1-7
7-是7到最后一个
[root@gh-shell 1-13] echo "asdasfsgsgsfsdfasfas"|cut -c -7
asdasfs
[root@gh-shell 1-13] echo "asdasfsgsgsfsdfasfas"|cut -c 7-
sgsgsfsdfasfas
[root@gh-shell 1-13]#
2.截取列:
cut默认的分隔符是 tab
[root@gh-shell 1-13] cat grade.txt |cut -f 3
math
91
80
70
89
[root@gh-shell 1-13] cat grade.txt |cut -f 2,3
chinese math
80 91
90 80
99 70
60 89
指定分隔符
-d
[root@gh-shell 1-13] cat /etc/passwd|cut -d ":" -f 1,3
root:0
bin:1
daemon:2
adm:3
lp:4
sync:5
shutdown:6
halt:7
mail:8
operator:11
games:12
ftp:14
nobody:99
systemd-network:192
dbus:81
polkitd:999
tss:59
sshd:74
postfix:89
chrony:998
[root@gh-shell 1-13]#
awk也可以
[root@gh-shell 1-13] cat /etc/passwd|awk -F":" '{print $1,$3}'
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 99
systemd-network 192
dbus 81
polkitd 999
tss 59
sshd 74
[root@gh-shell 1-13]#
[root@gh-shell 1-13] df -Th|tr -s " "|cut -d " " -f 1,2
文件系统 类型
devtmpfs devtmpfs
tmpfs tmpfs
tmpfs tmpfs
tmpfs tmpfs
/dev/mapper/centos-root xfs
/dev/sda1 xfs
/dev/mapper/centos-home xfs
tmpfs tmpfs
[root@gh-shell 1-13]#
截取字段的时候 一般使用 awk方便些
cut默认的分隔符是tab
awk默认的分隔符是空白(tab,空格)
[root@gh-shell 1-13] df -Th|awk '{print $1,$3}'
文件系统 容量
devtmpfs 898M
tmpfs 910M
tmpfs 910M
tmpfs 910M
/dev/mapper/centos-root 50G
/dev/sda1 1014M
/dev/mapper/centos-home 47G
tmpfs 182M
[root@gh-shell 1-13]#
awk
awk:强大的文本处理工具,可以用于数据提取、格式化等。可以通过设置字段分隔符和执行操作来处理文本。例如,打印文件file.txt的第2列:
awk '{print $2}' file.txt
paste
paste:用于将多个文件的内容按列合并。可以指定分隔符和输出格式。例如,将file1.txt和file2.txt按列合并:
paste -d',' file1.txt file2.txt
[root@gh-shell 1-13] paste grade.txt name.txt
name chinese math english 高辉
cali 80 91 82 高菲
tom 90 80 99 张渊
lucy 99 70 75 胡亚
jack 60 89 99 唐荣
张宇
高琛茗
高定江
高铭雪
史名龙
李忠奇
朱俊学
宋长爱
[root@gh-shell 1-13]# cat grade.txt >grade2.txt
[root@gh-shell 1-13]# paste grade.txt grade2.txt
name chinese math english name chinese math english
cali 80 91 82 cali 80 91 82
tom 90 80 99 tom 90 80 99
lucy 99 70 75 lucy 99 70 75
jack 60 89 99 jack 60 89 99
[root@gh-shell 1-13]#
split
split:用于将一个大文件分割为多个小文件。可以指定分割大小和输出文件名格式。例如,将bigfile.txt按10MB大小进行分割:
split -b 10M bigfile.txt
split 拆分(切割)命令
有一台机器内存比较小,只有4G,但是有个文件有20G的文本文件
网络传输的时候,网速比较慢,但是文件比较大,例如100G的文件,传输需要一天
思路
-
根据大小拆(字节)
- -b 10 以十个字节进行拆分
- -C 10 尽量保持每行的完整性,也是根据字节来截取,多余的就不放到这个文件里
[root@gh-shell gaofei] split -C 100 passwd -d sc_ [root@gh-shell gaofei] ls gaohui_000 gaohui_003 sc_01 sc_04 sc_07 sc_10 sc_13 sc_16 sc_19 gaohui_001 passwd sc_02 sc_05 sc_08 sc_11 sc_14 sc_17 sc_20 gaohui_002 sc_00 sc_03 sc_06 sc_09 sc_12 sc_15 sc_18 sc_21 [root@gh-shell gaofei] split -b 100 passwd -d gh_ [root@gh-shell gaofei] ls gaohui_000 gh_00 gh_04 gh_08 gh_12 gh_16 sc_01 sc_05 sc_09 sc_13 sc_17 sc_21 gaohui_001 gh_01 gh_05 gh_09 gh_13 gh_17 sc_02 sc_06 sc_10 sc_14 sc_18 gaohui_002 gh_02 gh_06 gh_10 gh_14 passwd sc_03 sc_07 sc_11 sc_15 sc_19 gaohui_003 gh_03 gh_07 gh_11 gh_15 sc_00 sc_04 sc_08 sc_12 sc_16 sc_20 [root@gh-shell gaofei]# -
根据行数猜
- -5 5行
- -d 产生的文件的后缀以数字命名
- -a 3 表示用三位数据来顺序命名
- -l 是按行分割
[root@gh-shell gaofei] split -l 10 passwd -d -a 3 gaohui_
[root@gh-shell gaofei] ls
gaohui_000 gaohui_001 gaohui_002 gaohui_003 passwd
[root@gh-shell gaofei] cat gaohui_000
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@gh-shell gaofei]#
优化思路:
- 花钱上硬件—>效果最好,立竿见影 —>代价比较大
- 使用技术手段
拼接:
[root@gh-shell gaofei] cat gh_* >gh_passwd
有个问题,一个文件有200万行—>如何快速定位到80-100万行的内容进行分析
很简单:分成10份,每份20万行,第5份就是我们要分析的内容
col
col:用于处理列对齐的文本文件。可以进行对齐操作、提取指定列等。例如,将file.txt进行列对齐:
col -x file.txt
join
join:用于将两个文件的行按指定字段进行连接。可以指定字段分隔符和连接方式。例如,将file1.txt和file2.txt按第1列进行连接:
join -t',' -1 1 -2 1 file1.txt file2.txt
[root@gh-shell 1-13] cat grade.txt grade2.txt
name chinese math english
cali 80 91 82
tom 90 80 99
lucy 99 70 75
jack 60 89 99
name chinese math linux
cali 80 91 82
tom 90 80 99
lucy 99 70 75
jack 60 89 99
[root@gh-shell 1-13] join grade.txt grade2.txt
name chinese math english chinese math linux
cali 80 91 82 80 91 82
tom 90 80 99 90 80 99
lucy 99 70 75 99 70 75
jack 60 89 99 60 89 99
[root@gh-shell 1-13]#
[root@gh-shell 1-13] join -j 2 grade.txt grade2.txt
chinese name math english name math linux
80 cali 91 82 cali 91 82
90 tom 80 99 tom 80 99
99 lucy 70 75 lucy 70 75
60 jack 89 99 jack 89 99
[root@gh-shell 1-13]#
使用-j选项时,可以指定一个或两个匹配字段的列号或列名。匹配字段必须是两个文件中都存在的列,并且具有相同的顺序。
小结一下
uniq:去重
? -c 统计重复的次数 count
? -u 打印唯一的行,不重复的行
? -d 打印重复的行
sort: 排序
? -n 根据数值来排序
? -r 降序排列
? -k 指定字段进行排序
? -t 指定分隔符,默认是空白
作业
根据/etc/passwd文件里的uid进行降序排序,输出第1个字段和第3个字段
[root@gh-shell 1-13] cat /etc/passwd|sort -t ":" -k 3 -nr|awk -F ":" '{print $1,$3}'
sc20 1019
sc19 1018
sc18 1017
sc17 1016
sc16 1015
sc15 1014
sc14 1013
sc13 1012
sc12 1011
sc11 1010
sc10 1009
sc9 1008
sc8 1007
sc7 1006
sc6 1005
sc5 1004
sc4 1003
sc3 1002
sc2 1001
sc1 1000
polkitd 999
chrony 998
systemd-network 192
nobody 99
postfix 89
dbus 81
sshd 74
tss 59
ftp 14
games 12
operator 11
mail 8
halt 7
shutdown 6
sync 5
lp 4
adm 3
daemon 2
bin 1
root 0
[root@gh-shell 1-13]#
[root@gh-shell 1-13]# cat /etc/passwd|awk -F":" '{print $1,$3}'|sort -k 2 -nr
sc20 1019
sc19 1018
sc18 1017
sc17 1016
sc16 1015
sc15 1014
sc14 1013
sc13 1012
sc12 1011
sc11 1010
sc10 1009
sc9 1008
sc8 1007
sc7 1006
sc6 1005
sc5 1004
sc4 1003
sc3 1002
sc2 1001
sc1 1000
polkitd 999
chrony 998
systemd-network 192
nobody 99
postfix 89
dbus 81
sshd 74
tss 59
ftp 14
games 12
operator 11
mail 8
halt 7
shutdown 6
sync 5
lp 4
adm 3
daemon 2
bin 1
root 0
[root@gh-shell 1-13]#
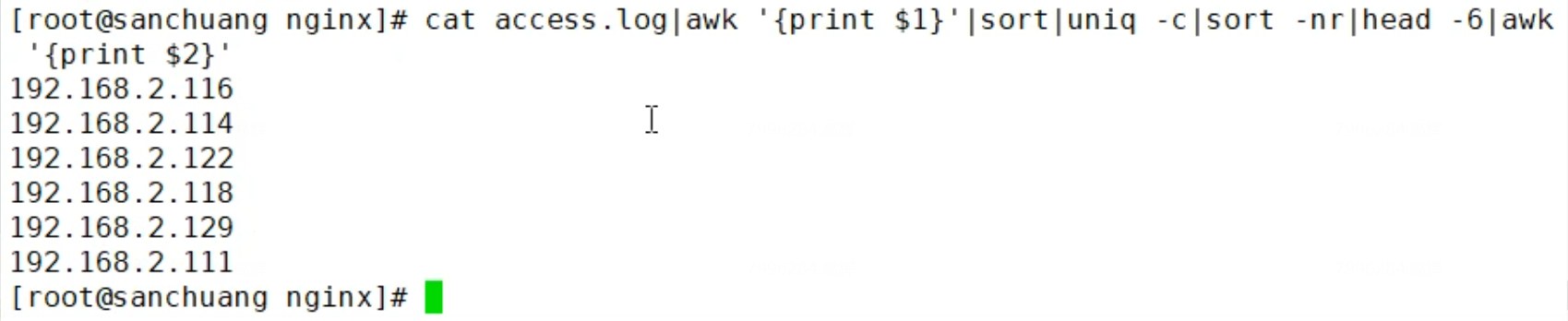
统计nginx的日志文件里访问量最大的6个ip地址,按照降序排序

小知识点
写脚本的流程
- 做需求分析
- 思路和技术
- 编写脚本
- 给脚本起名字
- 定义变量
- 用技术去实现
- 测试
- 修复bug
- 上线/交付
怎么统计行数
[root@gh-shell 1-13] cat name.txt|wc -l
13
怎么取出第几行的内容
[root@gh-shell 1-13] cat name.txt|head -5|tail -1
唐荣
在shell中多行缩进
'1.按ESC'
'2.把光标定位到你需要缩进的第一行'
'3.按大写的V,进入到可视化模式'
'4.利用上下方向键选择你需要缩进的行'
'5.按shift + >符号就是像右边缩进,<就是左边'
df -Th: 示磁盘空间使用情况
df -Th 是一个用于显示磁盘空间使用情况的命令。具体解释如下:
df是 “disk free” 的缩写,用于显示文件系统的磁盘空间使用情况。-Th是两个选项的组合。其中,-T用于显示文件系统类型,-h用于以人类可读的方式显示磁盘空间大小。
运行 df -Th 命令将会列出已挂载的文件系统的相关信息,包括文件系统类型、总容量、已使用的空间、可用空间、使用率和挂载点等。输出结果可以帮助用户快速了解磁盘空间的使用情况,并进行相应的管理和调整。
[root@gh-shell 1-13] df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 898M 0 898M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 9.6M 901M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 50G 2.1G 48G 5% /
/dev/sda1 xfs 1014M 151M 864M 15% /boot
/dev/mapper/centos-home xfs 47G 33M 47G 1% /home
tmpfs tmpfs 182M 0 182M 0% /run/user/0
[root@gh-shell 1-13]#
grep
利用grep取出以什么结尾的行
$符号的重要性—>表示以什么结尾
[root@gh-shell 1-13] df -Th|grep "/$"
/dev/mapper/centos-root xfs 50G 2.1G 48G 5% /
利用grep取出以什么开头的行
^表示以什么开头
[root@gh-shell 1-13] cat /etc/passwd|grep "^sc1"
sc1:x:1000:1000::/home/sc1:/bin/bash
sc10:x:1009:1009::/home/sc10:/bin/bash
sc11:x:1010:1010::/home/sc11:/bin/bash
sc12:x:1011:1011::/home/sc12:/bin/bash
sc13:x:1012:1012::/home/sc13:/bin/bash
sc14:x:1013:1013::/home/sc14:/bin/bash
sc15:x:1014:1014::/home/sc15:/bin/bash
sc16:x:1015:1015::/home/sc16:/bin/bash
sc17:x:1016:1016::/home/sc17:/bin/bash
sc18:x:1017:1017::/home/sc18:/bin/bash
sc19:x:1018:1018::/home/sc19:/bin/bash
[root@gh-shell 1-13]#
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- QGIS平常遇到的小问题汇总
- RocketMQ的一万字全面总结,带你快速入门消息队列
- 【Frontiers】“神仙期刊”,JCR1区,发文量3000+,录用率75%,1-2个月录用!
- React Portals
- Linux命令大全(狠狠爱住)
- android 分享文件
- 代码随想录算法训练营第六天|哈希表理论基础,242.有效的字母异位词,349. 两个数组的交集,202. 快乐数,1. 两数之和
- 我的创作纪念日
- Redis图形界面闪退/错误2系统找不到指定文件/windows无法启动Redis/不是内部或外部命令,也不是可运行的程序
- 帮助学妹用Python实现QQ音乐扫码登陆