【Linux系统编程二十八】基于条件变量的阻塞队列(生产消费模型)
【Linux系统编程二十八】基于条件变量的阻塞队列(生产消费模型)
一.同步问题
什么是同步问题呢?
就比如自习室的例子呢,如果一个线程频繁的叫做申请锁,释放锁。
或者频繁的我们把钥匙挂墙上,或者从墙上拿下来。
那么这个线程,他其实可能在我们自习室里没做其他动作,可能甚至都没有创造任何价值,那么这种情况就叫做同步问题。
这个过程还存在着互斥问题。
也就是说申请锁,释放锁,我们只有一个执行者能进来。这样呢可以保证任何一个时刻只允许一个执行人进入到我们的自习室里自习。
但是他的衍生问题就是大家申请钥匙的能力是不一样的。
所以有的线程申请锁能力比较强,有的线程申请锁的能力比较弱。
那么此时你一个强的线程,频繁的申请和释放所必然会导致其他线程出现饥饿问题。
好,所以呢我们为了保证不要产生这个问题呢,我们规定,让你出来之后呢,不要立马直接就去申请。
所我们定个原则,第一,外面的人必须得排队。
那么二你自己一旦出来之后,不能释放锁,不能直接就是释放锁之后再去申请锁,而是必须排到队列的尾部。
最终结果是我们所有人一旦把这个自习室用完了,剩下的线程按照一定的顺序再来进行竞争式的申请。
所以同步是保证数据安全的前提条件下,让我们的多线程按照一定的顺序来访问临界资源。
那通常你怎么保证数据安全呢? 一般我们都是要对数据进行加锁。
这个问题我们就称之为叫做线程所对应的同步。
【问题1】为什么要排队?
一个线程,一进来之后,他就直接去在我们对应的队列里去排队了吗?还是他被迫去排队了?
我们永远不要忽略一个前提,所有一个线程到来的时候,他并不是直接说我闲了没事干,我就直接去排队了。
所有线程过来的时候,他都是要先试着去访问资源的。他是访问资源失败的。才去进行我们定的排队。
所以在线程访问临界资源时,它防的外面突然进行的线程,而不是防的排队的线程。外面的线程需要判断资源是否就绪,才可以访问,如果不满足那么就需要进入队列里排队。
二.条件变量
所以怎么样能够让线程做到按照一定的顺序去进行访问临界资源呢?
这个概念解决方案我们称为Linux当中的条件变量.
什么叫做条件变量呢?
条件变量呢它提供两个东西。
第一个
他得给我提供一个队列,这个队列呢能够让我们的所有线程去在我们对应的等待队列当中排队。
第二个
它得给我们去提供一种简单的通知机制。 它这个通知机制里面呢可以想办法帮我能够把线程就从队列里唤醒。
这两个东西就叫做条件变量。其他它就是一个结构体对象,里面封装了队列,唤醒机制等。
你可以定义一个条件变量,申请条件变量,释放条件变量,就跟锁一样。
整个线程都可以通过库来申请很多锁资源和条件变量这样的资源。
你管他呢啊,你申请就申请的呗,但你将来想释放,我怎么知道你想释放哪一个?
你想让我告诉我哪个条件变量就绪了,我怎么知道是哪一个条件变量。你想让我线程去排队,我系统里会存在那么多条件变量,你让我到条件变量下去排队,我去哪排队呀?有那么多队列我去哪排队啊?
你的线上库给我提供了这么多排队,呃,这么多我们
毕竟要把我们的锁了,条件变量这玩意儿都要管起来。
所以后面啊凡是你听过的概念,其中大部分只要他能创建多个呢,他都是需要被管理。
怎么管理?
先描述再组织嘛,所以说它一定是个结构体。
1.实现原理
1.所有的线程一上来,先判断资源是否就绪,如果资源不就绪,那么就去条件变量下去等待。如果就绪那么就往下执行。
2.注意①,因为判断资源这个行为,就是在访问临界资源,所以需要先加锁,再进行判断。
3.注意②,所以线程是在持有锁的状态去判断临界资源是否就绪的,当临界资源不就绪时,那么它就是相当于是持有锁去队列里等待的。
4.当拿着锁的线程执行完后,出来,第一件事不是释放锁,而是先唤醒队列里某个线程。然后再释放锁。
5.被唤醒的线程就会立刻去竞争持有锁,往下继续执行。
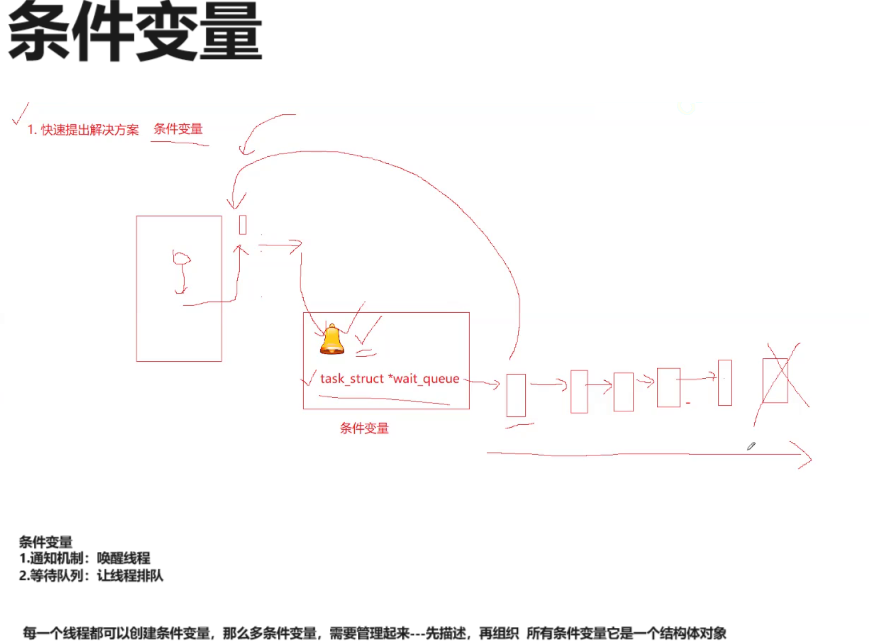

你在条件变量下去排队了,问题不在于你直接去条件变量去排队了,问题在于你为什么去调节变量下去排队。
所有在条件队列,条件变量的队列当中去排队的,一定是曾经都是先去进行申请资源,申请失败了,然后你才来条件变量下去排队的。而申请资源是持有锁去申请的,所以条件变量的存在必定要配合互斥锁。
因为同步的概念是保证在数据安全的情况下,然后让访问资源具有一定的顺序性。
2.等待的前提

就是我们我们比如说我们现在想要一个线程去休眠。你凭什么让我休眠啊?
我们讲究大家雨露均沾,有福同享,怎么能让我直接去休眠呢?
我们一定是临界资源不就绪了,我们无法执行,我们才让线程去休眠的。
比如说你今天呢想从一个队列里取数据。 那么这个地点有没有可能满呢? 有没有可能为空呢?
所以如果他满了,他空了,那么其中你的他的访问条件不就是不那么不满足时,那么此时我们是不是就应该让一个线程去休眠?

所以这里有一个非常重要的前提,就是我怎么知道我要让线程去休眠呢?
我怎么知道我们要访问的共享资源或者临界资源当前不就绪呢?
需要我们自己判断!
那么判断本身就是在访问临界资源。
你当前对应的一个线程,你们要进行决定,让我这个线程后续是休眠还是去做什么,你得先判断。 你得先判断资源是不是就绪。
如果资源就绪,那我就直接不休眠,我就直接自己去访问了。 如果不就绪,那我就去休眠。
关键问题在于资源是否就绪? 我们判断资源是否就绪就是在访问该资源。
所以那么我们就注定了休眠一定是在加锁和解锁之间的。
就相当于是我们未来想进行我们对于临界资源的访问呢,你必须先加锁,然后才能再判断,然后才能休眠,所以注定了等待的过程在加锁和解锁之前。

3.使用接口
那么当一个线程互斥的访问某个共享资源时。这个资源不就绪时,也就是不满足使用条件时,你当前只能等待。
那么只能将线程添加到等待队列当中,这种情况我们就需要条件变量了啊。
那么我怎么使用条件变量呢?
①.【定义条件变量】
条件变量类型是一种pthread_cond_t类型,这是原生线程库给我提供的数据类型,这个数据类型定义的变量就是我们的条件变量。
我们要用它呢必须得先做初始化。
②.【初始化条件变量】
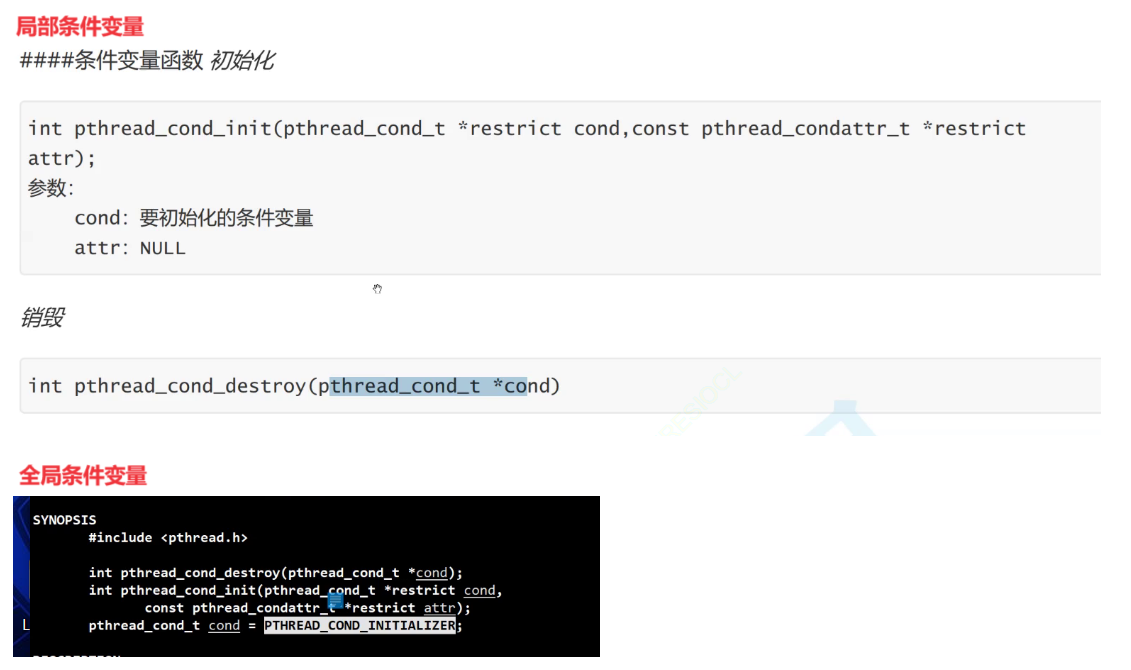
定义条件变量和定义锁是类似的,有局部初始化和全局初始化两种初始化方式。
局部定义条件变量,需要使用pthread_cond_init()接口。
1.第一个参数,就是要使用的条件变量地址。
2.第二个参数呢叫做条件变量所对应的叫做属性。默认伪nullptr。
【销毁条件变量】
pthread_cond_destroy()
参数就是要销毁的条件变量
③.【让线程去条件变量下等待】

当你申请某个资源时,或者发现某些条件不满足时。
那么你就应该让自己直接去我们对应的条件变量下的队列里去等待。所以怎么把自己投入到等待队列呢?
使用pthread_cond_wait()系统接口让线程去指定的条件变量下等待。1.第一个参数,[条件变量],就是让线程要在指定的条件变量下等待。
2.第二个参数,[锁],是一把锁,为什么要有一把锁在这里呢?
(注意条件变量和锁接口都设到涉及到这个接口上了,说明它俩关系非常密切)
④.【为什么第二个参数是锁?】条件变量和锁的关系是什么?
当你申请某个资源之前,需要判断该资源是否就绪,是否满足使用条件,注意这里判断资源是否就绪,也是在访问临界资源的,所以需要持有锁判断,而如果不满足使用条件,就需要到条件变量下去等待,也就是持有锁等待。那么其他线程就无法抢到锁了。所以需要将这个线程持有的锁给释放掉,这样其他线程才有机会进来访问。
你要知道,当线程在我们条件变量下等待的时候,你不能让他直接去等啊。因为它身上还挂着锁呢,所以你得先让他把锁释放掉。不释放锁,其他线程进不来呀。
所以你一个线程去等的时候,释放掉锁后其他线程可以继续进来。
而这个函数它自然而然设计的时候就这样设计的。自然而然就让我们释放锁了。
pthread_cond_wait()在调用的时候,线程去指定的条件变量下等待时,它会自动将线程持有的锁进行释放。这就是为什么要把锁传进来的一个原因之一。它需要知道释放的是哪一把锁。
其他线程进来的时候,也是持有锁进来(竞争锁)
如果条件不满足,直接让它去条件变量下等待,然后释放锁。
所以这个等待队列的可能在这个时候会存在大量的线程。
那么线程呢他都去休眠了,就不会执行后面的动作了。


⑤.【唤醒等待队列的线程】

在条件变量下等待的线程就无法再往后执行了,那么当资源条件满足时就可以唤醒等待队列里的线程,继续执行,而刚被唤醒的线程,会立刻去竞争锁,持有锁,往后执行。
1.参数就是要唤醒哪个条件变量的线程。
2.signal是唤醒队列的头部一个线程,
3.broadcast是唤醒队列里的所有线程。
【细节】
好,那么呃这里呢再说一个细节,就是我在这儿没有地址,同学们啊我在这里没有取地址。
如果我在这里取地址,我将来要取出对应的数据,我肯定是要把它先强转成先强转成我们对应的叫做仓,然后呢再做简用啊。为什么我这里不取地址啊,我这样去写不是挺好的吗?来那么为什么我在这里就是直接去直接这样去写不行吗? 啊,然后这样写有问题啊,为什么呢?
因为你对应的这个i啊你创建线程成功之后呢,新线程跑过去就直接执行它了。 好,那么我们的主线程的跑过去继续循环了。
但是呢这个a变量呢其实你把地址传过来,就是这个线程里面拿到这个i未来这个i值啊,a r
s指针就是这个东西,指向的就是这个a啊传递者实现这个i的话,那么说明新线程和主线程访问的是同一个i访问的是同一个i的话呢,那么在我们多线程并发的时候,你并不清楚这个线程还是这个线程哪个先跑。
如果这个先跑了,他把a这个值直接就给你一瞬间干到了我们对应的四或s者五啊,那么同学们此时你的所有线程打出来的这个传递来的整数就全部变成四和五了啊,所以这里会有并发问题啊,我们这里直接拷贝,为什么这样写就可以了呢?
因为我们这里传它是拷贝式的,我相当于把这个a呢直接拷贝给了a r g s。 拷贝给了a r g
s的话,那么其中你我的线程运行我的你的主线线程你就跑你的我我们俩双方不会影响指针,也会发生拷贝,这就是细节。其实这里有特别细的细节,就是你会发现如果你在这里刚刚是直接传地址的话,这个线程和这个for循环外面的哎它使用的是同一个变量,使用的同一个变量的话,那么就可能会出问题啊。
所以这里呢我们尽量让它不要将来访问同一个变量啊,尽量传三的说,除非你就是想共享,除非你就是想共享,让主线程和新线程共享三个变量,否则不要这么干啊,否则的话尽量还是保证它的变量是独立的。往后呢我们如果想要县城独立的话,尽量不要传地址啊,除非你自己vlog的对空间啊,否则的话一定要注意一下啊。

三.生产消费模型
我们以供应商,超市,消费者举例说明:超市就相当于一个缓存,那么供应商因为有缓存的存在呢,它本质上其实是可以调整供货商和消费者因为速度不一致而带来的我们的效率问题。
好,那么因为供货商的存在呢,它可以把我忙的时间靠前,直接生成卖批。
然后呢那么我放假的时候消费者就可以来进行消费了。
所以这种超市的存在它可以做到叫做支持忙闲不均。也就是说呢,我们因为超这个存在,生产者的发送生产很快,消费者消费成本还不影响。
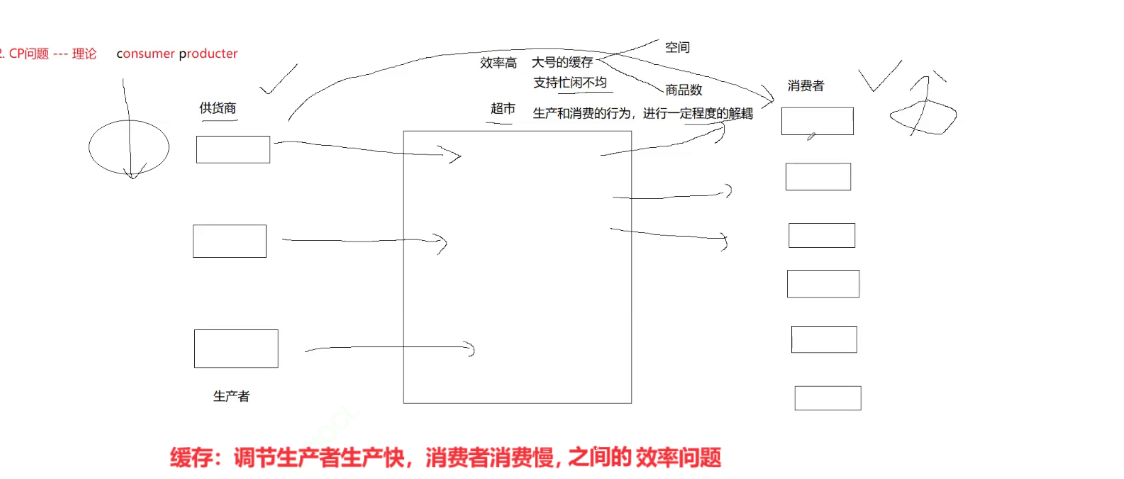
对于供货商来讲呢,最看重的根本就不是你的超市里摆了多少商品,供货商最关注的是你超市里还有多少个空位置。
而消费者他才不关注你这个呃超市有多少空位置,消费者最关心你商品多少啊,所以呢因为我们的资源的侧重点不一样。
因为我们有缓存存在,我们对应的供货商和消费者他呢就可以做到忙闲不均,供货商在生产时,消费者可以来消费吗?消费者在消费时,供货商可以生产吗?当然可以。
消费者只关注超市里的商品,具体这个供货商到底是不是正在生产,跟你什么关系呢?供货商只关心超市里有没有空位置,你消费者买没买商品跟我有什么关系?
所以呢就是因为我们有超市的存在,我们可以做到让我们对应的供货商他的生产行为,和消费者的消费行为同时进行。
就是说呢整个系统那么不需要你生产者考虑消费者,消费者也不需要考虑生产者。我们双方就是互相就没关系的,毫无瓜葛,你生产你的,我做消费我的。
那么因为多线程为了强调并发,而并发就要强调解耦,你必须把解耦工作做好,这个时候工作才能更好。
那么所以说到底,供货商要做的最终目的,其实是要把商品交给消费者。
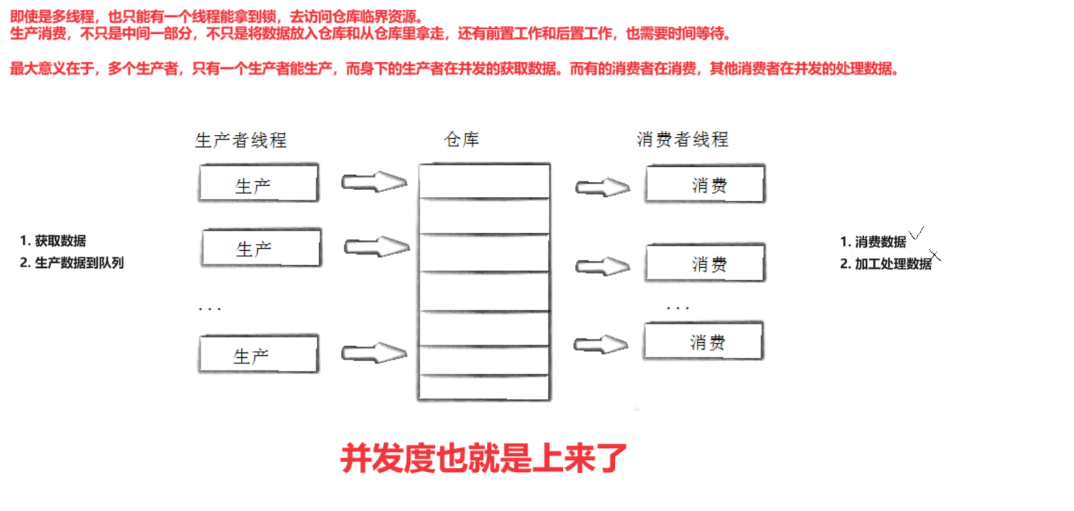
说白了对应于计算机就是一个线程把数据交给另一个线程。所以理论上这生产消费模型,它这背后的本质其实是执行流在做通信。
而线程之间是通过一个交易场所一个特定的数据内存结构的来进行数据交流的。而这个交易场所双方线程都是可以看到的,所以这个交易场所就相当于我们的共享资源。
我们的超市必须得被生产者都能看到吧,必须得给都得给消费者都能看到吧。所以你这里对应的这个超市的话,就是最典型的我们共享资源。
因为这超市本来就是共享资源嘛,所以呢我在生产他可能消费,我在消费来它在生产,这都有可能有问题就比如说我正在生产时,消费者就直接过来拿走,那可能就会导致我的生产过程就直接出错了,它会出现并发问题,但它会有具体什么并发问题呢?
321原则
3种关系
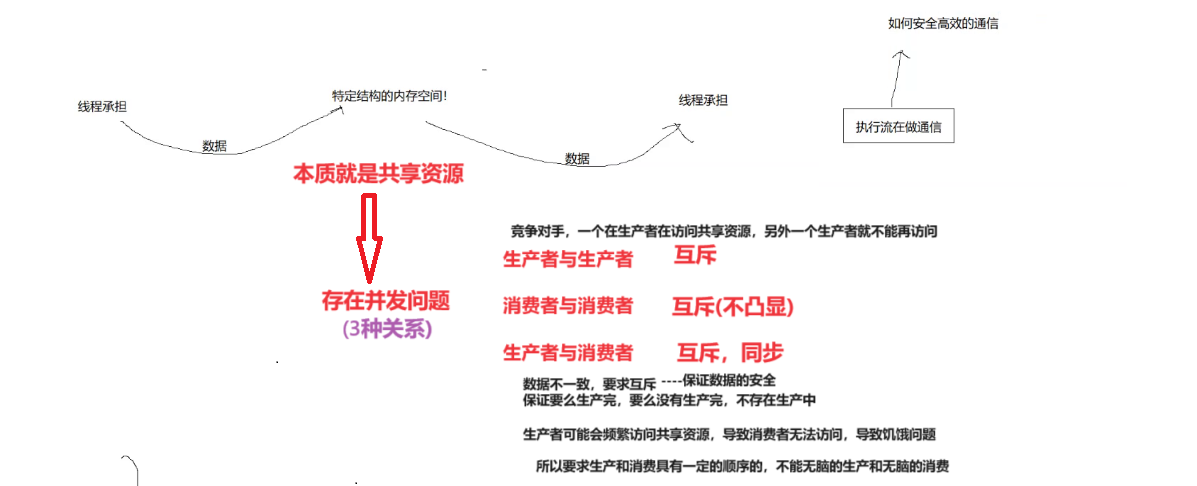
并发问题它的本质就是多线程访问共享资源造成的。
其实你最终要首先你要把这个并发的场景,你要把并发问题找到,你得把并发场景想明白,那么反正并存就在这儿啊,无非本质就是他们,生产者之间的关系,消费者之间的关系,生产者和消费者间的关系,只要你把它关系理顺了,未来怎么加锁,怎么同步互斥,其实我们思维就出来了。
生产者和消费者之间存在什么关系呢?
生产者和生产者之间什么关系啊?
消费者和消费者之间什么关系呢?
【生产者与消费者】
生产者和消费者之间肯定要求存在互斥关系,我在往超市里生产的时候,你消费者不能消费。我消费者从超市里消费时,生产者不能往超市里生产。
生产者和消费者之间还要求存在同步关系,生产者可能频繁的的服务共享资源,导致消费者无法访问,就会导致消费者饥饿问题所以要求生产和消费具有一定的顺序,不能无脑的生产和无脑的消费。
【生产者和生产者】
生产者和生产者之间肯定要求要存在互斥关系,不能并发的去访问同一个共享资源,造成数据不安全。
【消费者和消费者】
消费者和消费者之间也要求是互斥关系,对于同一个关系资源要求只能有一个消费者能访问。但现实生活并没有出现这样情况呢?
非常简单,因为我们当前的消费的消费者的货物太多了。好,你拿一个方面,别人想拿,你拿走了没关系,我还拿下一个呀。商品很多啊,所以才这个互质问题没有凸显。
2种角色
生产者和消费者这两种角色,可能存在多个生产者和多个消费者。
1个交易场所
这个交易场所就是我们刚刚口中所说的超市,以及未来我们所说的特定结构的内存空间啊。
好,那么那么特定的容器那么来帮我们去进行生产消费。

所以生产消费模型的特点呢,它的优点啊好,它带来对应的优点是什么呢?
一个呢叫做我们的支持,叫做忙闲不均。
好,第二个呢我们叫做解耦。
四.基于阻塞队列的生产消费模型。

阻塞队列里封装有普通队列作为生产者和消费者进行交易的场所,而交易具有最大的数量,超过最大数据,生产者就不要往队列里生产了。
生产者和消费者共用一把锁,互斥的访问共享资源。
生产者和消费者不能无序的生产和消费,需要按照一定的顺序来生产和消费,所以需要同步机制—条件变量。
生产者想生产就能生产吗?消费者想消费就能消费吗?当然不能!
生产者要生产,必须要满足生产条件,才能生产。
消费者要消费,必须满足消费条件,才能消费。
生产条件就是交易场所有位置可以生产,如果没有位置了,就说明生产条件不满足,而消费条件就是交易场所有数据可以消费,如果没有数据,就说明消费条件不满足。
Push—>当生产条件满足时,生产者就可以往队列里生产,而生产者成功生产出来一个数据,就代表着消费的条件是满足的,这时就可以唤醒消费者等待队列里的消费者线程。当生产条件不满足时,就去生产者条件变量下去等待。
Pop---->当消费条件满足时,消费者就可以去队列里消费,消费者消费一个数据,就代表,生产的条件是满足的,所以这时就可以唤醒生产者等待队列里的生产者线程。如果消费条件不满足时,消费者就需要到消费者条件变量下去等待。等待被唤醒。

#include "BlockQueue.hpp"
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include "TASK.hpp"
#include <ctime>
// 生产者消费者分别是两个线程,通过阻塞队列来进行交易,所有这个队列就是一个共享资源
// 共享资源首先要让两个线程都可以看到,如何做到呢?作为函数参数传给线程
void *Consumer(void *args)
{
// Bolckqueue<int> *bq = static_cast<Bolckqueue<int> *>(args);
Bolckqueue<TASK> *bq = static_cast<Bolckqueue<TASK> *>(args);
while (true)
{
// 消费者--从队列里消费数据
// int data=bq->pop();
//1.消费数据
TASK t = bq->pop();
// std::cout<<"消耗一个数据: "<<data<<std::endl;
//2.处理数据
t.run();
std::cout<<"处理任务: "<<t.GetTASK()<<" 运算结果是:"<<t.Getresult()<<" thread id: "<<pthread_self()<<std::endl;
}
}
void *Productor(void *args)
{
// Bolckqueue<int> *bq = static_cast<Bolckqueue<int> *>(args);
Bolckqueue<TASK> *bq = static_cast<Bolckqueue<TASK> *>(args);
// int data=0;
int len=opera.size();
while (true)
{
// 1.获取数据
int data1 = rand() % 10 + 1;
usleep(10);
int data2 = rand() % 10;
char op=opera[rand()%len];
// 生产者--往队列里生产数据
// data++;
//2.生产数据
TASK t(data1,data2,op);
bq->push(t);
// std::cout<<"生产一个数据: "<<data<<std::endl;
std::cout << "生产一个任务" <<t.GetTASK()<<" thread id: "<<pthread_self()<< std::endl;
sleep(1);
}
}
int main()
{
srand(time(nullptr));
pthread_t c, p;
// 阻塞队列作为交易平台,给生产者和消费者使用
Bolckqueue<TASK> *bq = new Bolckqueue<TASK>(5);
pthread_create(&c, nullptr, Consumer, bq);
pthread_create(&p, nullptr, Productor, bq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}
#pragma once
#include <iostream>
#include <queue>
#include <pthread.h>
//阻塞队列就使用sql中的队列
//这个交易平台肯定要保证资源的安全性,保证生产者和消费者之间数据一致性。和同步问题
//所有需要封装锁和条件变量
template <class T>
class Bolckqueue
{
public:
Bolckqueue(int maxcap):_maxcap(maxcap)
{
//队列会自己调用它的构造
//初始化锁,和条件变量
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_c,nullptr);
pthread_cond_init(&_p,nullptr);
}
public:
T pop()
{
pthread_mutex_lock(&_mutex);
while(_q.size()==0)//防止伪唤醒
{
//如果没有东西可以消费,那么当前线程就应该到条件变量的阻塞队列里等待,并将当前线程的锁释放,给其他线程使用
pthread_cond_wait(&_c,&_mutex);
}
T t=_q.front();
_q.pop();//消费数据,你想消费就消费的吗?必须得满足消费条件,有东西可消费才可以
//成功消费一个,说明生产条件是满足的
pthread_cond_signal(&_p);
pthread_mutex_unlock(&_mutex);
return t;
}
//那么谁来唤醒消费者中不满足消费条件而放进阻塞队列里的线程呢?
//当只要满足消费条件了,就可以唤醒阻塞队列里的线程,而谁最清楚是否满足消费条件了呢?
//当前是生产者,只要生产者能生产出来一个,就说明当前的交易平台是满足消费条件的,就可以唤醒在消费阻塞队列里的线程
public:
void push(const T & in)//生产的过程和消费的过程之间要互斥。
{
pthread_mutex_lock(&_mutex);//加锁
while(_q.size()==_maxcap)//防止伪唤醒
{
pthread_cond_wait(&_p,&_mutex);//当前线程不满足生产,进入阻塞队列里,并将锁释放给其他线程使用
//生产者和消费者需要放入不同的条件变量里的阻塞队列
}
_q.push(in);//生产数据就一定能生产吗?不一定,如果生产条件不满足就不要生产了,就进入阻塞队列里等待
//能生产出来,就说明消费条件是满足的,就可以唤醒消费阻塞队列里的线程
pthread_cond_signal(&_c);
pthread_mutex_unlock(&_mutex);//解锁
}
//那么谁来唤醒生产者中因为不满足生产条件而放入生产阻塞队列的线程呢?
//只要满足生产条件,就可以唤醒生产阻塞队列里的线程,而消费者最知道是否满足生产条件了
//只要消费者能成功消费一个,那么就肯定满足生产条件(不为满),那么就可以唤醒生产阻塞队列里的线程。
~Bolckqueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_c);
pthread_cond_destroy(&_p);
}
private:
std::queue<T>_q;//阻塞队列作为交易平台,共享资源
int _maxcap;//交易的最大量
pthread_mutex_t _mutex;//锁
pthread_cond_t _c;//条件变量
pthread_cond_t _p;
};
也就是这个阻塞队列里,数据呢可不可以放对象呢?
为什么写模板呢,不仅仅是为了传整数啊,那么内部可不可以传任务呢?当然可以!
#pragma once
#include <iostream>
#include <string>
std::string opera="+-*/%";
class TASK
{
public:
TASK()
{}
TASK(int data1, int data2, char op) : _data1(data1), _data2(data2), _oper(op)
{
}
void run()
{
switch (_oper)
{
case '+':
_result = _data1 + _data2;
break;
case '-':
_result = _data1 - _data2;
break;
case '*':
_result = _data1 * _data2;
break;
case '/':
{
if (_data2 == 0)
_exitcode = 1;
else
_result = _data1 / _data2;
}
break;
case '%':
{
if (_data2 == 0)
_exitcode = 2;
else
_result = _data1 % _data2;
}
break;
default:
_exitcode=3;
break;
}
}
std::string GetTASK()
{
std::string r=std::to_string(_data1);
r+=_oper;
r+=std::to_string(_data2);
r+="=?";
return r;
}
std::string Getresult()
{
std::string result=std::to_string(_data1);
result+=_oper;
result+=std::to_string(_data2);
result+='=';
result+=std::to_string(_result);
result+="[code:";
result+=std::to_string(_exitcode);
result+=']';
return result;
}
private:
int _data1;
int _data2;
char _oper;
int _result;
int _exitcode;
};
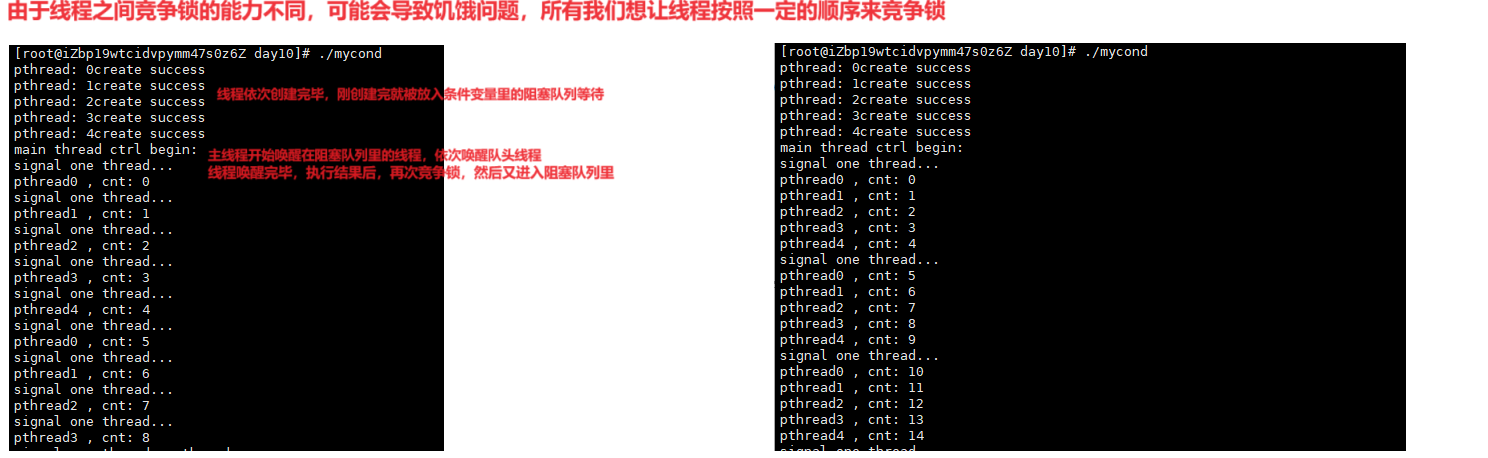
这样我们就使用条件变量来完成一个基于阻塞队列的生产和消费模型。
1.细节一:真正的生产和消费过程
生产的过程不只是将生产的数据放入到交易场所里,消费的过程也不只是从交易场所里将数据拿走。
真正的生产过程还有前置工作,真正的消费过程还有后置工作。
【生产过程】
你生产数据,那么你这个数据是从哪里来的呢?一般数据是从网络和用户那获取到的。而从网络和用户那获取到数据这个过程也需要花费时间的,也是属于生产过程中的。从网络或者用户那获取到数据后,生产者就可以往交易场所生产数据了。
【消费过程】
生产者生产完数据后,消费者从交易场所拿走数据,但消费者不是傻傻的就光把数据拿走就完事了,而是还需要对数据进行处理,这个过程也需要花费一定的时间,所以真正的消费过程是,消费者从交易场所里拿走数据,并对数据进行加工处理。

值得注意的是,在生产者往交易场所生产的时候和消费者从交易场所消费时,这个过程是互斥的,是加锁的,而生产者的前置工作和消费者的后置工作,并不是互斥的。它们是可以并发执行的,也就是会存在并发场景:
1.当生产者生产的时候,其他生产者虽然无法进入生产,但是可以并发获取数据。
2.当消费者消费的时候,其他消费者虽然无法进入消费,但是可以并发去处理数据。
3.当生产者生产的时候,消费者是无法进入消费的,但是其他消费者是可以去并发去处理数据的。
4.当消费者消费的时候,生产者是无法进入生产的,但是其他生产者是可以去并发获取数据的。
2.细节二:正确看待生产消费模型的高效问题
为什么说生产消费模型是高效的呢?
加锁保护变成互斥关系,并发度不是降低了吗?怎么能提高效率呢?生产者生产时,消费者不能消费,消费者消费时,生产者不能生产,这能提高个毛线效率啊。
我们要理解:生产者的生产过程是有两部分的,消费者的消费过程也是具有两部分的。生产者往交易场所生产数据和消费者从交易场所拿走数据,这个过程是互斥的,访问的是临界资源,也就是临界区,而生产者的前置工作:获取数据和消费者的后置工作:处理数据,并没有访问临界资源,不是临界区。
而中间的过程是互斥的,没有效率可言,但生产者持有锁往交易场所生产时,消费者虽然无法消费,但是消费者可能正在加工处理数据,那么生产和消费线程就是在并发执行!
一段执行临界代码,一段执行非临界区代码,两个线程就并发高效的执行起来了。
高效并不是指,生产和消费互斥这一段高效,这一段甚至是低效的,而是指生产者临界区代码和消费者的非临界区diamond,消费者的临界区代码和生产者的非临界区代码是可以并发执行的!。

3.细节三:伪唤醒

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RHCE9学习指南 第14章 文件系统
- [AutoSar]BSW_OS 07 Autosar OS_时间保护
- 游泳耳机有什么好处?四款适合水下听歌的优质游泳耳机分享
- Acrel-EIoT能源物联网云平台助力电力物联网数据服务 ——安科瑞 顾烊宇
- 软件测试面试题整理
- 海外云手机:跨境养号的新趋势
- illuminate/database 使用 五
- 【亚马逊云科技】通过高性能低延迟对象存储 S3实现网站资源托管
- Java_Swing程序设计
- VSCode远程开发配置