实例分割论文精读:Mask R-CNN
1.摘要
本文提出了一种概念简单、灵活、通用的实例分割方法,该方法在有效地检测图像中的物体同时,为每个物体实例生成一个实例分割模板,添加了一个分支,用于预测一个对象遮罩,与现有的分支并行,用于边界框识别,Mask R-CNN易于训练,只给Faster R-CNN增加了很小的开销,运行速度为5fps,另外,Mask R-CNN很容易推广到其他任务,例如,允许我们在同一框架中估计人类姿势,我们展示了COCO系列挑战的所有三个方面的最佳结果,包括实例分割、边界框对象检测以及人类关键点检测,没有任何花里胡哨的东西,Mask R-CNN在每项任务上都优于所有现有的模型参赛作品,包括COCO 2016挑战赛的获胜者。我们希望我们简单而有效的方法将作为一个坚实的基线,并有助于简化实例级识别的未来研究。
2.模型结构图
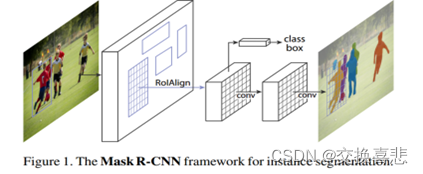
3.算法步骤
1.首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
2.然后,将其输入到一个预训练好的神经网络中(ResNet等)获得对应的feature map
3.接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
4.接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
5.接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
6.最后,对这些ROI进行分类(N类别分类)、BB回归和Mask生成(在每一个ROI里面进行FCN操作)。
4.模型结构解析
4.1 Mask R-CNN/FPN
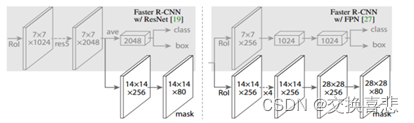
带和不带FPN结构的Mask R-CNN 在Mask分支上略有不同,对于带有FPN结构的Mask R-CNN它的class、box分支和Mask分支并不是共用一个RoIAlign,在训练过程中,对于class, box分支RoIAlign将RPN(Region Proposal Network)得到的Proposals池化到7x7大小,而对于Mask分支RoIAlign将Proposals池化到14x14大小(Mask分支,因为实例分割要保留更多的细节,所以没有池化到77格式,选择池化到1414格式)
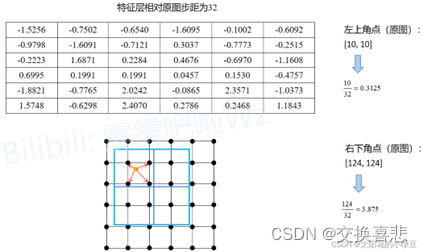
4.2 RoIpooling和RoIAlign
Faster RCNN使用RoIPool将RPN得到的Proposal池化到相同大小,过程涉及到取整操作,导致定位不是那么准确(misalignment)
RoI pooling:1.将Proposal映射到特征层上;2.将得到的Proposal强行划分成规定大小(55->22)
RoIAlign:1.不进行四舍五入2.期望输出是22大小的话,将proposal划分为22个子区域,设置sampling_ratio为每个子区域设置采样点,计算每个子区域中采样点的值(双线性插值),最后对每个区域内所有采样点取均值即为该子区域的输出。
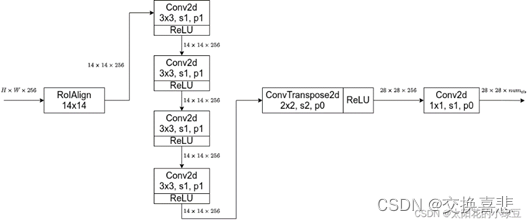
4.3 Mask分支
FCN中,对待每个像素的每个类别都会预测一个分数,然后通过softmax得到每个类别的概率(不同类别之间存在竞争关系),那个概率高就将像素分配给哪个类别,
在Mask R-CNN中,,对预测Mask以及Class进行解耦,对输入的RoI针对每个类别都单独预测一个Mask,最终根据box, cls分支预测的classes信息来选择对应Proposals:提议、提案、建议,在这里指的是二阶段方法中RPN的输出框,也就是对anchor第一次做回归得到的结果,就是候选框,用RPN生成候选框,然后分类和回归,region proposal指的是候选区域。类别的Mask
5.损失函数
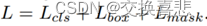
logits:网络预测的输出
targets:对应的GT
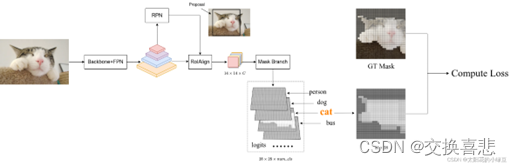
如下图所示,假设通过RPN得到了一个Proposal(图中黑色的矩形框),通过RoIAlign后得到对应的特征信息(shape为14x14xC),接着通过Mask Branch预测每个类别的Mask信息得到图中的logits(logits通过sigmoid激活函数后,所有值都被映射到0至1之间)。通过Fast R-CNN分支正负样本匹配过程我们能够知道该Proposal的GT类别为猫(cat),所以将logits中对应类别猫的预测mask(shape为28x28)提取出来。然后根据Proposal在原图对应的GT上裁剪并缩放到28x28大小,得到图中的GT mask(对应目标区域为1,背景区域为0)。最后计算logits中预测类别为猫的mask与GT mask的BCELoss即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Unity 点击对话系统(含Demo)
- 大众汽车宣布将ChatGPT,批量集成在多种汽车中!
- C#调用C++ dll异常排查
- 神舟飞船科普网站的设计与实现(JSP+java+springmvc+mysql+MyBatis)
- 分布式(6)
- jquery学习-1
- C //练习 5-2 模仿函数getint的实现方法,编写一个读取浮点数的函数getfloat。getfloat函数的返回值应该是什么类型?
- input 关闭输入的自动提示 autocomplate
- 从零学Java 泛型
- 设计模式:工厂方法模式(讲故事图文易懂)