【pytorch】手写backward
Affine如何实现
https://rising.readthedocs.io/en/latest/_modules/rising/transforms/functional/affine.html
https://github.com/pytorch/vision/blob/main/torchvision/transforms/functional.py
torchvision.transforms.functional.affine。在 PyTorch 中,仿射变换不是直接应用于原始图像张量的,而是应用于一个网络的一部分,这样可以在训练过程中通过自动微分机制实现反向传播。
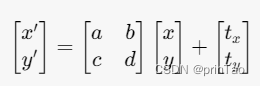
( x , y ) (x,y) (x,y) 是原始图像中的像素坐标, ( x ′ , y ′ ) (x', y') (x′,y′) 是变换后的坐标, a , b , c , d a, b, c, d a,b,c,d 是旋转和缩放矩阵的元素, t x , t y t_x, t_y tx?,ty? 是平移的距离。
在训练神经网络时,你需要计算损失函数相对于网络参数的梯度,然后用这个梯度来更新参数。这通过反向传播算法实现,PyTorch 的 autograd 系统自动帮你计算这些梯度。
torchvision.transforms.functional.affine 函数内部会创建一个可微分的仿射变换操作。当你在训练模式下应用这个变换,并且通过该变换得到的图像参与了损失函数的计算时,PyTorch 的自动微分机制会记录下这个仿射变换操作的所有相关信息。这样,在计算梯度时,它就能够根据链式法则反向传播这个操作的梯度。
扩展后的图像如何对应以前的图?
在仿射变换过程中,每个输出图像的像素位置 ( x ′ , y ′ ) (x', y') (x′,y′) 是通过上述矩阵乘法及平移向量来从输入图像的像素位置 ( x , y ) (x, y) (x,y) 映射得到的。因为这种映射是连续的,所以即便在旋转、缩放或者扭曲之后,输出图像中的每个像素仍然可以追溯到原始图像中的某个位置(尽管可能不再是整数坐标,而是通过插值得到的)。
透视如何实现
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【已解决】java 无法将类 XX类中的构造器 X应用到给定类型
- CentOS7搭建Elasticsearch与Kibana服务
- N-139基于springboot,vue宠物领养系统
- c++时间 作业
- web前端HTML基础(三)——文本及超链接
- TCP一对一聊天
- Selenium自动化
- 内外网文件交换系统实用技巧揭秘:安全、效率、便捷一个不少
- ADP荣膺Everest Group、NelsonHall和Ventana Research评选为全球薪酬市场领导者
- 【C++】union