读《Open-Vocabulary Video Anomaly Detection》
2023 西北工业大学和新大
引言
视频异常检测(VAD)旨在检测不符合预期模式的异常事件,由于其在智能视频监控和视频内容审查等应用前景广阔,已成为学术界和工业界日益关注的问题。通过几年蓬勃发展,VAD 在许多不断涌现的工作中取得了重大进展。
传统的VAD可以根据监督模式大致分为两类,即半监督VAD[17]和弱监督VAD[38]。它们之间的主要区别在于异常训练样本的可用性。虽然它们在监督模式和模型设计方面有所不同,但两者都大致可以被视为分类任务。在半监督 VAD 的情况下,它属于一类分类的类别,而弱监督 VAD 属于二元分类。具体来说,半监督VAD假设在训练阶段只有正常样本可用,不符合这些正常训练样本的测试样本被识别为异常,如图1(a)所示。大多数现有方法本质上试图通过单类分类器[50]或自监督学习技术(如帧重建[9]、帧预测[17]、拼图[44]等)来学习单类模式,即正常模式。
弱监督VAD可以看作是一个二元分类任务,假设在训练阶段都有正常和异常样本,但异常事件的精确时间注释是未知的。以往的方法通常采用多实例学习(MIL)[38]或TopK机制[27]的二进制分类器来区分正常和异常事件。一般来说,现有的半监督和弱监督VAD方法都限制了它们对分类的关注,并使用相应的鉴别器对每个视频帧进行分类。虽然这些实践在几个广泛使用的基准上取得了显著的成功,但它们仅限于检测一组封闭的异常类别,无法处理任意不可见的异常。这种限制限制了它们在开放世界场景中的应用,并带来了增加缺失报告的风险,因为训练数据中不存在实际部署中的许多现实世界异常。(本来想说这个开放世界的点子提出有点强行,类似生物特征识别闭集分类器不行我要搞开集匹配。但是类比弱监督是fewshot的话,开放世界就有点zeroshot了)
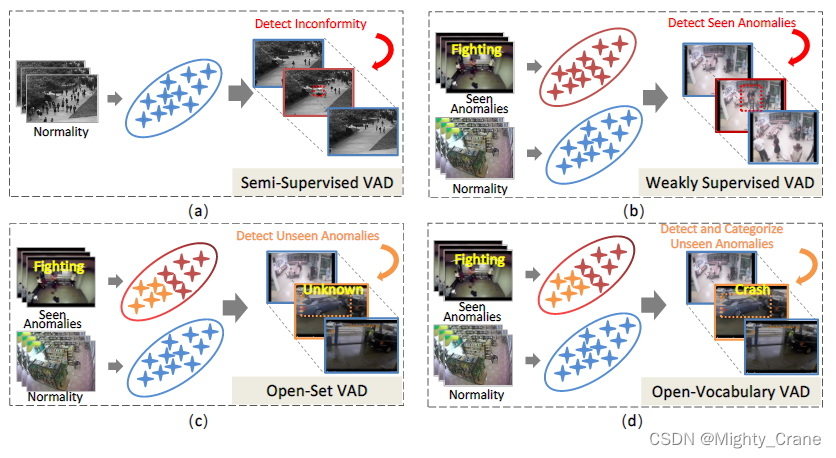
贡献总结部分提到“该模型将 OVVAD 任务分解为两个相互互补的子任务——类不可知检测和类特定分类——并联合优化它们以实现准确的 OVVAD。”不过这本就有种解耦头的感觉啊,起码yolo6就有这种了吧 哦不对,那种目标检测本质上还是闭集分类器,只找出已知类别的东西,这里是要适用于任意的缺陷,只要置信度满足就检测出来,不管他有什么类别
相关工作
之后再说吧,先看看大模型的部分
框架
大致就是两条支路,检测这条路就是很直观的逐帧编码得到异常置信度
分类这条路聚合帧级特征得到视频级特征,然后生成一个异常类别的文本嵌入,再把这俩跨模态的特征对齐来估计类别。这个生成的模块就是用的LLM
TAM
这里提出CLIP虽然很牛逼但是只能得到静态的帧级特征,缺乏时序性,所以引入图卷积。但是这里又不急着涉及跨模态,只是单纯地获取帧级图像特征的时序性,那么类似步态识别3D卷积后接temporal pooling或者Gaitgl里的LTA不就完事了吗?我觉得可能是想利用上CLIP这样一样预训练模型,比如它的图像编码器很牛逼,直接用它的图像图像特征,所以一直逼逼赖赖CLIP,那么话都到这份上了就不得不祭出别的时域聚合方法了,总之就是觉得有点牵强
这里的图卷积公式里,对邻接矩阵的归一化是直接用的softmax!?要说一般图领域是左右乘度矩阵的-1/2次方才对吧
这里softmax函数被用于归一化邻接矩阵的每一行,以确保每一行的和为一。这种设计是为了捕获基于位置距离的上下文依赖性。具体来说,softmax归一化强调了与当前节点相近的节点的权重,从而可能捕捉到与时间距离相关的局部性质。再要结合文中对邻接矩阵的定义
邻接矩阵 H(i,j) 元素被定义为第i 帧和第 j 帧之间的相对时间位置关系的倒数,其中 σ 是一个超参数,用于控制距离相关性的影响范围。根据这个公式,两个帧之间的时间距离越近,它们之间的邻近关系得分越高,反之则越低。
所以这种归一化方法的一个可能优势是它在时间维度上直接建模了帧之间的邻近性,这对于捕捉视频序列中的时序依赖性可能是有益的。然而,它与传统的图归一化方法不同,可能无法完全捕捉节点的度分布,这可能会影响模型学习的全局结构特性。
总的来说,虽然这种归一化方法与传统的GCN中使用的方法不同,但它可能特别适用于处理视频数据的时序问题。而且作者可能发现在这个特定上下文中,使用softmax进行归一化能够更好地捕捉时间上的局部性质。
SKI
- 自动生成语义提示:系统可能会自动生成与视频内容相关的语义提示。这些提示不一定来自人工输入,而是可能通过分析视频内容或使用其他指标自动产生的。
- 语言模型生成文本:大型语言模型(如ChatGPT)接收这些语义提示,生成描述视频内容的文本信息,这些信息反映了视频中可能出现的正常或异常情况。
- 文本信息的处理:生成的文本信息被送入CLIP的文本编码器,将文本转换成向量形式,这样就可以与视频帧的视觉特征进行结合。
- 跨模态特征聚合:文本向量与视觉特征结合,形成一个跨模态特征表示,这可以通过图卷积网络或其他结构来进一步处理,以实现异常检测。
NAS
所以说到底,CLIP和LLM的预训练模型还是更适用于一直类别,对于未见新异常还是逊色。所以要用LLM生成伪训练样本
- 生成潜在异常的文本描述:首先,使用大型语言模型(例如ChatGPT, ERNIE Bot)与预定义的模板提示来生成描述潜在新颖异常类别的文本。这些描述模拟了在真实世界中可能出现的异常事件。
- 使用AI生成模型制造图像和视频:随后,利用AI生成内容模型(如DALL·E)生成与文本描述相对应的图像或短视频。这些生成的内容(Igen和Sgen)旨在视觉上表示文本描述的场景。
- 模拟场景连续性的视频剪辑:对于生成的图像Igen,模块借鉴先前研究中的有效激活策略,将单张图片转换为模拟场景变化的视频片段。这可能涉及到选择图像的不同区域并将它们重新缩放以创造新视频剪辑Scat。
- 合成长视频样本:为了模仿真实世界中未经编辑的长视频中的异常情况,NAS模块将Scat或Sgen插入到标准视频中,生成最终的异常视频样本Vnas。插入的位置是随机选择的,以增加样本的多样性。
- 微调模型:拥有这些合成的异常样本Vnas后,模型进行微调,目的是提高其对真实世界中新颖异常的检测能力。
(感觉有点怪。这种情况让我想起来之前有过些老师质疑过我的事,这为了缺陷检测就直接生成若干假虚拟视频,凭啥直接拿来就用,人家正规数据集造出来也得写论文评估质量啥的呀)
损失函数
训练阶段不含伪异常样本
- 类别不可知的检测:使用Top-K机制在异常和正常视频中选择置信度最高的K个异常来作为视频级预测。在这里,K设置为异常视频的n/16和正常视频的n。
- 交叉熵损失:计算视频级预测和二进制标签之间的二进制交叉熵损失Lbce。
分类任务
- 分类损失:计算聚合视频级特征与文本类别嵌入的相似性,以推导视频级分类预测,并计算交叉熵损失Lce。
- 注意力机制:由于是弱监督任务,无法直接从帧级注释中获得视频级分类预测,因此采用基于软注意力的聚合方法。
- 语义知识注入(SKI)模块的参数:通过优化正常和异常知识嵌入间的相似度差异来显式优化。
微调阶段含伪异常样本
- 微调:使用NAS模块产生的伪异常样本Vnas进行微调,它为分类和检测提供了帧级注释。
- 分类损失:对于分类,损失函数Lce2保持不变,但考虑到潜在的新颖类别。
- 检测损失:Lbce2是帧级的二进制交叉熵损失。
总体损失函数
- 训练阶段:总损失函数Ltrain是Lbce,Lce和Lsim的和,其中Lsim是相似度损失。
- 微调阶段:总损失函数Ltune是Lbce2和Lce2的和,加上一个调节项λ 乘以Lbce和Lce。
总结来说,这个过程包括了针对异常检测的类别不可知的方法和对已知类别和新颖类别的分类方法的训练和微调。目标函数设计来优化模型对于异常行为的检测能力,并在微调阶段通过伪异常样本进一步增强模型对新颖异常的识别能力。
实验
之后再说吧
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL 8.0中新增的功能(八)
- 【LeetCode: 57. 插入区间+分类讨论+模拟】
- nginx日志目录详解
- flutter定义statefulwidget如果必须接收关键字但具体值不确定的情况下,可以使用required
- js 一个对象根据条件切割成对象数组
- Ceph的介绍与部署
- 51单片机LED点阵屏
- STL-string
- 3分钟快速了解Java泛型的extends通配符
- leetcode - 446. Arithmetic Slices II - Subsequence