【陈工笔记】Transformer的认识
对Transformer生动形象的比喻
Transformer包括了Encoder和Decoder,在知乎上看到了对两个部分关系的一种理解,非常有趣。即,“一个人学习跳舞,Encoder是看别人是如何跳舞的,Decoder是将学习到的经验和记忆,展现出来。”
Transformer编码器的学习
Encoder的总概
以下是Transformer的内部结构图,左侧为 Encoder block,右侧为 Decoder block,红色圈中的部分为?Multi-Head Attention,是由多个?Self-Attention组成。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
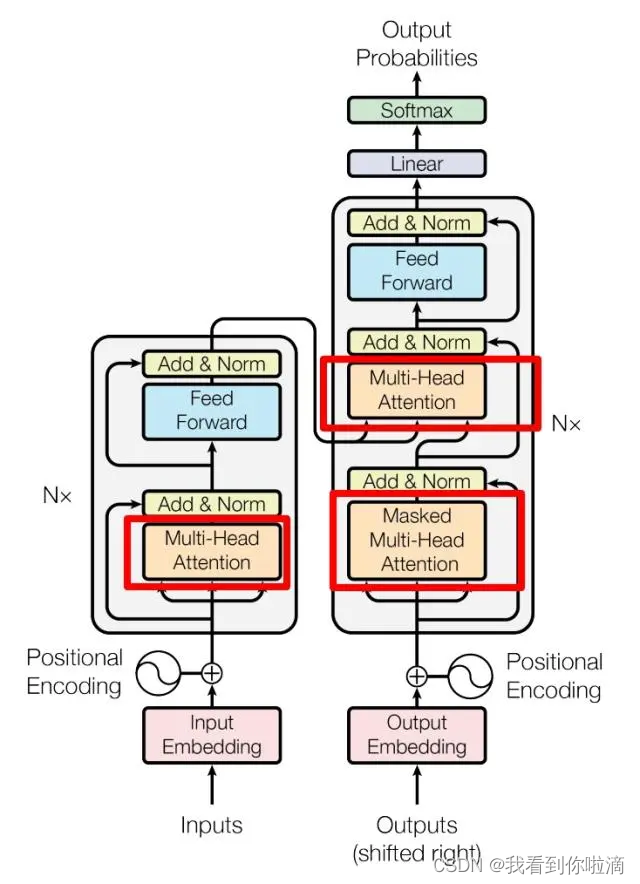
Multi-Head Attention 以及 Self-Attention机制
在框架图中,?Self-Attention是 Transformer 的重点,所以重点关注 Multi-Head Attention 以及 Self-Attention。
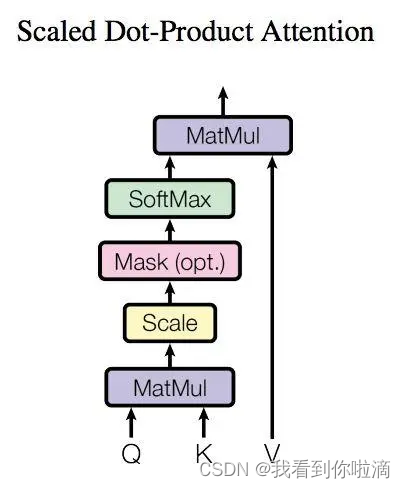
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵?Q(查询),?K(键值),?V(值)。得到矩阵?Q,?K,?V之后就可以计算出 Self-Attention 的输出了,计算的公式如下。

公式中计算矩阵?Q和?K?每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。使用 Softmax 计算?attention 系数,得到 Softmax 矩阵之后可以和?V相乘
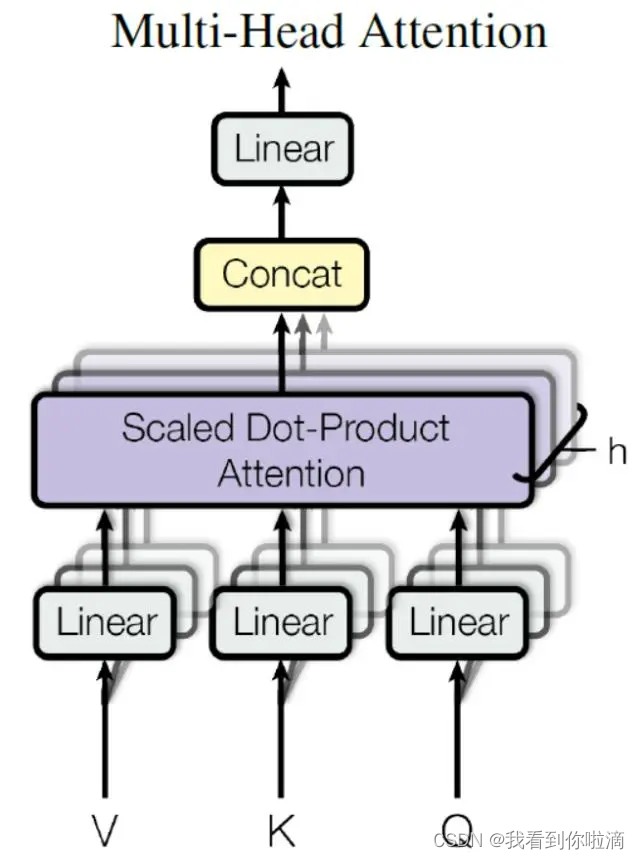
Multi-Head Attention 是由多个 Self-Attention 组合形成的,如下图所示
Add & Norm 层
在完成Transformer较为核心的多头注意力计算过程之后,进入下一步,即Add & Norm 层,它由 Add 和 Norm 两部分组成

Add指?X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛
Feed Forward层
然后,经过Feed Forward层,由一个两层的全连接层组成,第一层的激活函数为 ReLU,第二层不使用激活函数
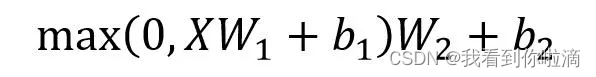
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block
(内容持续更新ing)
上述内容借鉴自:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【秒懂程序、进程、线程的概念与区别】
- 7-34 通讯录的录入与显示 分数 10
- vue.js怎么保证计算精度
- 【MATLAB】CEEMD_LSTM神经网络时序预测算法
- vue3 setup + ts 项目模块找不到问题解决:Cannot find module ...
- 热钱涌向线控底盘!XYZ全栈集成引领新风向
- Mac环境下反编译apk
- yolov8实时获取视频预测结果
- JAVA版随机抽人
- C++ Qt开发:DateTime日期时间组件