Python 序列之列表
前言
列表、字典、字符串这些数据类型可谓是天天见,不止在学习的过程中,你有没有发现它们操作上的相似性?其实,它们还有一个共同的名字——序列。

一、序列是什么?
序列并不是某种新的、特殊的数据类型,而是一系列数据类型的统称。字符串、列表、元组、字典、集合都是序列大家族种的成员,它们的操作具有相似性,且在内存中,它们都是一块用来存放多个值的连续的内存空间,故放在了一起,统称“序列”。
序列是一种数据存储方式,用来存储一系列的数据。在内存中,它们都是一块用来存放多个值的连续的内存空间。比如一个整数序列[10,20,30,40],示意表示:

由于Python3中一切皆对象,在内存中实际是按照如下方式存储的:

从图示中,我们可以看出序列中存储的是整数对象的地址,而不是整数对象的值。
二、列表
1.列表简介
- 列表:用于存储任意数目、任意类型的数据集合。
- 列表是内置可变序列,是包含多个元素的有序连续的内存空间。列表的标准语法格式:
a=[10,20,30,40]
其中,10,20,30,40这些称为:列表a的元素。 - 列表中的元素可以各不相同,可以是任意类型。比如:
a=[10,20,abc'True] - Python的列表大小可变,根据需要随时增加或缩小。
列表对象的常用方法汇总如下,方便大家学习和查阅。
| 方法 | 操作类型 | 描述 |
|---|---|---|
list.append(x) | 增加元素 | 将元素x增加到列表list尾部 |
list.extend(aList) | 增加元素 | 将列表alist所有元素加到列表list尾部 |
list.insert(index,x) | 增加元素 | 在列表list指定位置index处插入元素x |
list.remove(x) | 删除元素 | 在列表list中删除首次出现的指定元素x |
list.pop([index]) | 删除元素 | 删除并返回列表list指定为止index处的元素,默认是最后一个元素 |
list.clear() | 删除所有元素 | 删除列表所有元素,并不是删除列表对象 |
list.index(x) | 访问元素 | 返回第一个x的索引位置,若不存在x元素抛出异常 |
list.count(x) | 计数 | 返回指定元素x在列表list中出现的次数 |
len(list) | 求列表长度 | 返回列表中包含元素的个数 |
list.reverse() | 翻转列表 | 所有元素原地翻转 |
list.sort() | 排序 | 所有元素原地排序 |
list.copy() | 浅拷贝 | 返回列表对象的浅拷贝 |
2.列表创建
(1)[]创建
a = [10, 20, 'yyy', 'good', True]
b = [] # 创建一个空列表
print(a) # 输出:[10, 20, 'yyy', 'good', True]
print(b) # 输出:[]
(2)list创建
使用list()可以将任何可选代的数据转化成列表。
a = list() # 创建一个空列表
b = list(range(10))
c = list('yyydaydayup') # 可以把字符串中的每个字符转换为列表元素
print(a) # 输出:[]
print(b) # 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(c) # 输出:['y', 'y', 'y', 'd', 'a', 'y', 'd', 'a', 'y', 'u', 'p']
上面列表b使用了range()函数,它是Python经常会用到的用来创建整数列表的函数。
(3)range()创建整数列表
range()可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为:
range([start,] end [step])
start参数:可选,表示起始数字。默认是0
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1
注意:python3中range()返回的是一个range对象,而不是列表 。我们需要通过list()方法将其转换成列表对象。
a = list(range(0, 10))
b = list(range(0, 10, 1))
c = list(range(2, 10, 2))
d = list(range(2, -10, -2))
print(a) # 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(b) # 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(c) # 输出:[2, 4, 6, 8]
print(d) # 输出:[2, 0, -2, -4, -6, -8]
(4)推导式生成列表
上面的range()只能生成特定条件的整数列表,如果我想生成满足更复杂条件的列表呢?当学习了for循环和if语句后,我们可以写一个代码块来完成该任务,这也是其他语言中的实现方案。但在Python中,我们有一种更为优雅的方式——推导式。
# 生成一个列表,里面装有0~5的2.5倍
a = [x * 2.5 for x in range(5)]
# 生成一个列表,里面装有0~100内所有能被9整除的数的2倍
b = [x * 2 for x in range(100) if x % 9 == 0]
print(a) # 输出:[0.0, 2.5, 5.0, 7.5, 10.0]
print(b) # 输出:[0, 18, 36, 54, 72, 90, 108, 126, 144, 162, 180, 198]
3.增加元素

| 方法 | 是否生成新列表 | 描述 |
|---|---|---|
list.append() | 否 | 将元素x增加到列表list尾部 |
list.extend(aList) | 否 | 将列表alist所有元素加到列表list尾部 |
list.insert(index,x) | 否 | 在列表list指定位置index处插入元素x |
aList+bList | 是 | 将原列表的元素和新列表的元素依次复制到新的列表对象中 |
aList*3 | 是 | 生成一个新列表,新列表元素是原列表元素的多次重复 |
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。因此除非必要,我们一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
(1)append()方法
原地修改列表对象,是真正的列表尾部添加新的元素,速度最快,推荐使用。
a = [20, 30]
a.append(40)
print(a) # 输出:[20, 30, 40]
(2)+拼接
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
a = [20, 40]
print(id(a)) # 输出:2601031170048
a = a + [50, 60]
print(id(a)) # 输出:2601859293120
通过如上测试,我们发现变量a的地址发生了变化。也就是创建了新的列表对象。
(3)extend()方法
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
a = [20, 40]
print(id(a)) # 输出: 2934488037376
b = [50, 60]
a.extend(b)
print(id(a)) # 输出: 2934488037376
a = a + b
print(id(a)) # 输出: 2935316488128
(4)insert()插入元素
使用insert()方法可以将指定的元素插入到列表对象的任意制定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:remove()、pop()、del,它们在删除非尾部元素时也会发生操作位置后面元素的移动。
a = [1, 2, 3]
a.insert(2, 999)
print(a) # 输出:[1, 2, 999, 3]
(5)乘法扩展
使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复。
a = ['yyy', 123, True]
b = a * 3
print(a) # 输出:['yyy', 123, True]
print(b) # 输出:['yyy', 123, True, 'yyy', 123, True, 'yyy', 123, True]
print(id(a)) # 输出:2650058717184
print(id(b)) # 输出:2650887230528
4.删除元素

(1)del方法
a = [1, 2, 999, 3, 4]
del a[2]
print(a) # 输出:[1, 2, 3, 4]
(2)list.pop()方法
list.pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
a = [10, 20, 30, 40, 50]
b1 = a.pop() # 结果:b1=50
print(a, b1) # 输出:[10,20,30,40]50
b2 = a.pop(1)
print(a, b2) # 输出:[10,30,40],20
(3)list.remove()方法
删除首次出现的指定元素,若不存在该元素抛出异常。
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
a.remove(20) # 结果:[10,30,40,50,20,30,20,30]
a.remove(100) # 报错:ValueError:list.remove(x):x not inlist
5.访问&计数

(1)通过索引直接访问
我们可以通过索引直接访问元素。索引的区间在[0,列表长度-1]这个范围。超过这个范围则会抛出IndexError异常。
a = [1, 2, 3, 'yyy', 4, 5]
print(a[3]) # 输出:yyy
print(a[30]) # 报错:IndexError: list index out of range
(2)list.index()获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的索引l位置。语法是:index(value,[start,[end]])。 其中,start和end 指定了搜索的范围。
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
a.index(20) # 结果:1
a.index(20, 3) # 结果:5 从索引位置3开始往后搜索的第一个20
a.index(30, 5, 7) # 结果:6从索引位置5到7这个区间,第一次出现30元素的位置
a.index(10000) # 报错:ValueError: 10000 is not in list
(3)list.count()获得指定元素在列表中出现的次数
count()可以返回指定元素在列表中出现的次数。
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
print(a.count(20)) # 输出:3
print(a.count(100000)) # 输出:0
(4)len()返回列表长度
len()是单词length的缩写,用来求序列的长度,即序列中包含元素的个数。
a = [1, 2, 3]
print(len(a)) # 输出:3
(5)成员资格判断
判断列表中是否存在指定的元素,我们可以使用count()方法,返回0则表示不存在,返回大于0则表示存在。但是,一般我们会使用更加简洁的in关键字来判断,直接返回True或False
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
print(20 in a) # 输出:True
print(100 not in a) # 输出:True
print(30 not in a) # 输出:False
6.切片操作
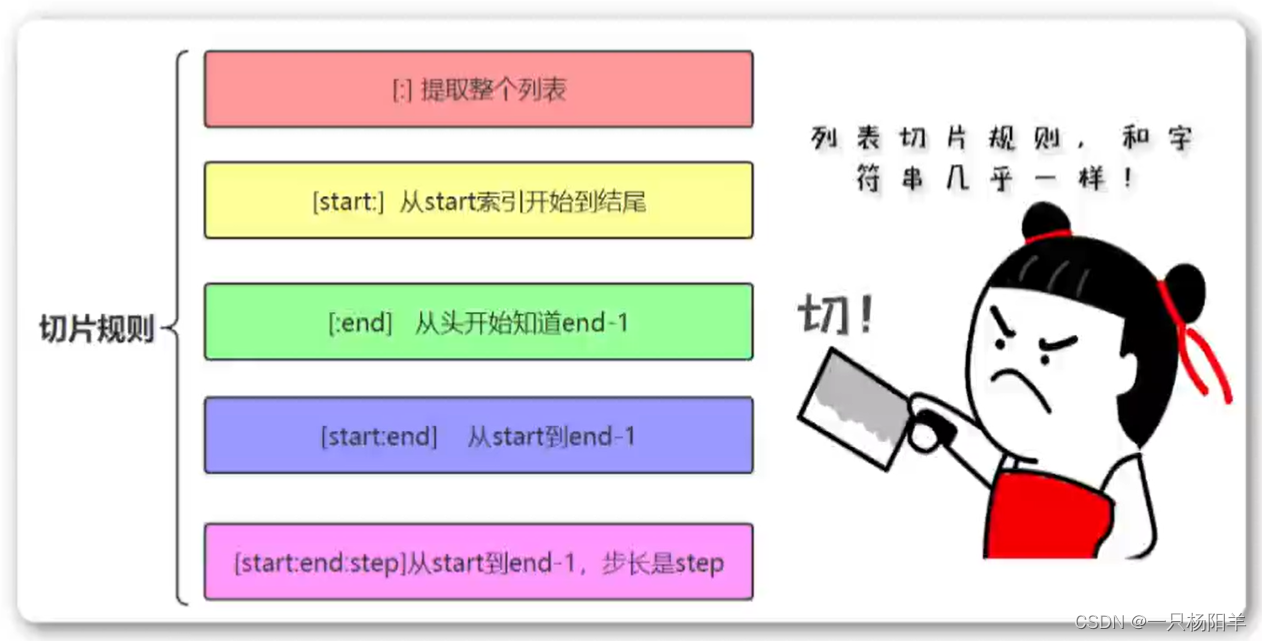
切片是Python序列及其重要的操作,适用于列表、元组、字符串等等。切片slice操作可以让我们快速提取子列表或修改。标准格式为:[起始偏移量start:终止偏移量end[:步长step]]
典型操作(三个量为正数的情况)如下:
| 操作和说明 | 示例 | 结果 |
|---|---|---|
[:]提取整个列表 | [10,20,30][:] | [10,20,30] |
[start:]从start索引开始到结尾 | [10,20,30][1:] | [20,30] |
[end]从头开始知道end-1 | [10,20,30][:2] | [10,20] |
[start:end] 从start到end-1 | [10,20,30,40][1:3] | [20,30] |
[start:end:step]从start提取到end-1,步长是step | [10,20,30,40,0,60,70][1:6:2] | [20, 40, 60] |
其他操作(三个量为负数)的情况:
| 示例 | 说明 | 结果 |
|---|---|---|
[10,20,30,40,50,60,70][-3:] | 倒数三个 | [50,60,70] |
[10,20,30,40,50,60,70][-5:3] | 倒数第五个到倒数第三个(包头不包尾) | [30,40] |
[10,20,30,40,50,60,70][::-1] | 步长为负,从右到左反向提取 | [70,60, 50, 40, 30,20,10] |
切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始偏移量小于0则会当做0,终止偏移量大于“长度-1"会被当成“长度-1”。例如:
a = [10, 20, 30, 40]
print(a[1:30]) # 输出:[20, 30, 40]
我们发现正常输出了结果,没有报错。
7.列表的遍历、复制
(1)列表遍历
a = [10, 20, 30]
for i in a: # i是临时变量名称,随便起的
print(i)
(2)复制列表所有元素到新列表对象
list1 = [10, 20, 30]
list2 = list1
上述代码实现列表元素的复制了吗?我们再加一行:
list1 = [10, 20, 30]
list2 = list1
print(id(list1) == id(list2)) # 输出:True
由此看来,第2行代码只是将list2也指向了列表对象,也就是说list2和list1持有地址值是相同的,列表对象本身的元素并没有复制。
我们可以通过如下简单方式,实现列表元素内容的复制:
list1 = [10, 20, 30]
list2 = [] + list1
print(id(list1) == id(list2)) # 输出:False
注:我们后面也会学习copy模块,使用浅复制或深复制实现我们想要的复制操作。
8.列表的排序
(1)修改原列表

(2)不修改原列表
我们也可以通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。

通过上面操作,我们可以看出,生成的列表对象b和c都是完全新的列表对象。
(3)reversed()返回迭代器
内置函数reversed(也支持进行逆序排列,与列表对象reverse()方法不同的是,内置函数reversed()不对原列表做任何修改,只是返回一个逆序排列的选代器对象。

我们打印输出c发现提示是:list_reverseiterator。也就是一个迭代对象。同时,我们使用list(c)进行输出,发现只能使用一次。第一次输出了元素,第二次为空。那是因为迭代对象在第一次时已经遍历结束了,第二次不能再使用。
9.统计操作
a = [1, 2, 3]
print(max(a)) # 输出:3
print(min(a)) # 输出:1
print(sum(a)) # 输出:6
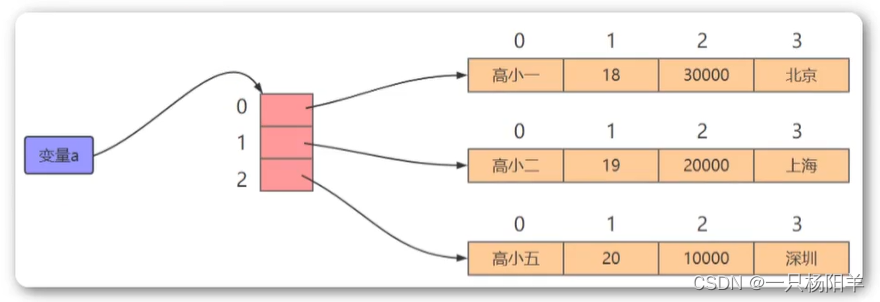
三、多维列表

一维列表可以帮助我们存储一维、线性的数据。
二维列表可以帮助我们存储二维、表格的数据。
例如下表的数据:
| 姓名 | 年龄 | 薪资 | 城市 |
|---|---|---|---|
| 高小一 | 18 | 30000 | 北京 |
| 高小二 | 19 | 20000 | 上海 |
| 高小五 | 20 | 10000 | 深圳 |
源码:
a = [
['高小一', 18, 30000, '北京'],
['高小二', 19, 20000, '上海'],
['高小三', 20, 10000, '深圳'],
]
print(a[1][0], a[1][1], a[1][2]) # 输出:高小二 19 20000
内存结构图:
a = [
['高小一', 18, 30000, '北京'],
['高小二', 19, 20000, '上海'],
['高小三', 20, 10000, '深圳'],
]
# for循环遍历二维列表
for i in range(3):
for j in range(4):
print(a[i][j], end='\t')
print()
打印结果如下:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 服务器日常怎么维护 有哪些
- 小白的python学习之路!掌握Pandas:Python中的数据分析利器
- RK3568开发笔记(十):开发板buildroot固件移植开发的应用Demo,启动全屏显示
- Elasticsearch中object类型与nested类型以及数组之间的区别
- 机器学习笔记 - 基于RAFT的光流估计进行稳健的运动物体检测
- 重学Java 6 流程控制语句
- 2024年【熔化焊接与热切割】报名考试及熔化焊接与热切割作业考试题库
- 从C向C++3——类和对象
- 开源Cloudreve云盘系统源码/ 支持本地储存+对接各大对象储存/带云盘系统安装教程/公私兼备网盘系统
- python之画动态图 gif效果图