如何加快 SQL 查询速度的同时保持SQL的简洁?
在本文中,我们将讨论如何提高SQL查询速度的同时,还能保持SQL语句的简洁。
在进入主题之前,我们先了解一下查询的实际处理过程:
1. 查询处理过程
查询处理过程被定义为通过一系列从数据库中提取数据的过程。这涉及将SQL语句的转换为数据库可以理解的形式,并查询出最终的结果。
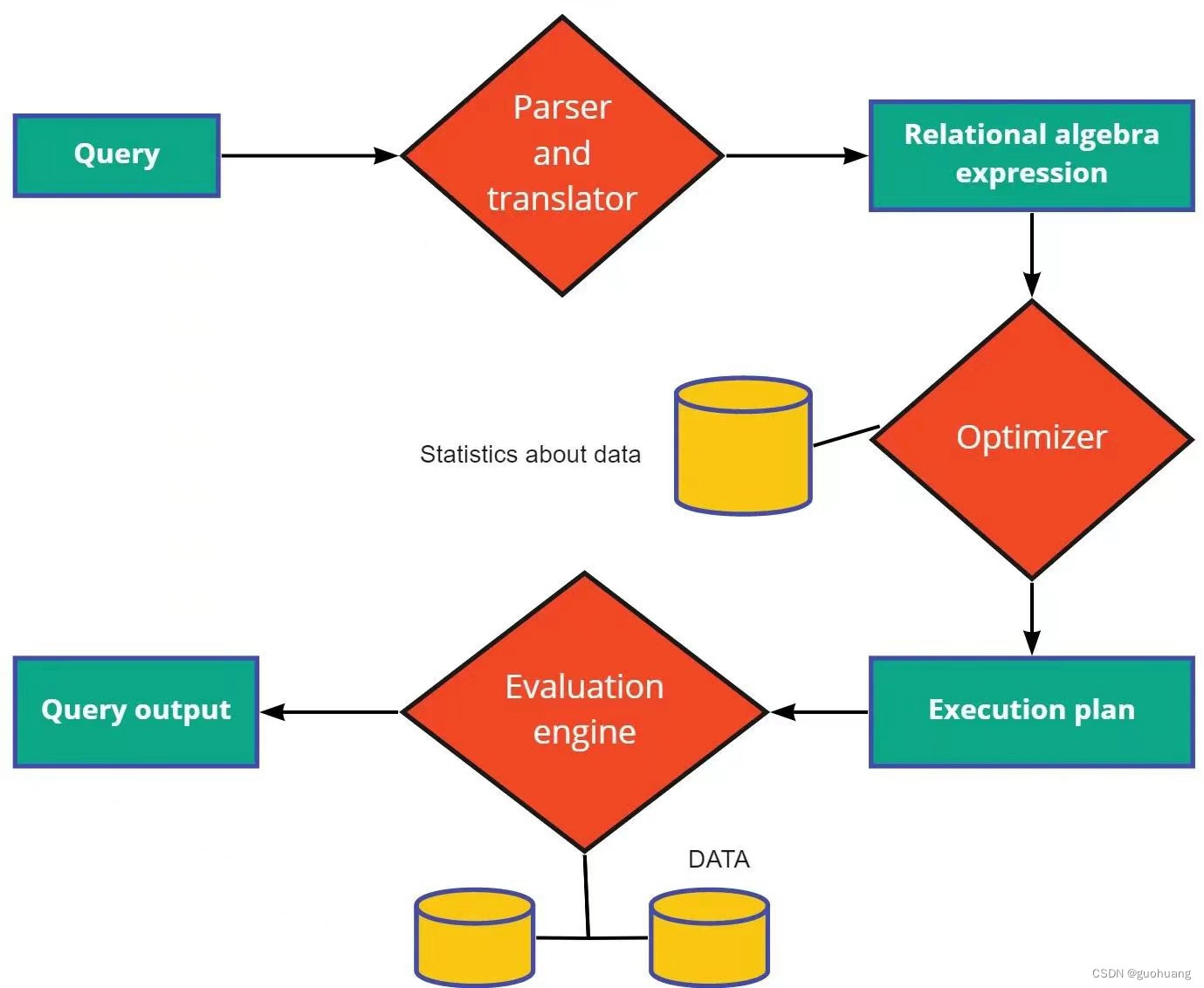
查询处理涉及三个主要步骤:
- 解析和翻译:查询处理从SQL的解析和翻译开始。与编译器中的解析器类似,解析器检查查询语法以查看提到的内容是否在数据库中。 SQL是一种高级查询语言,需要把它翻译成关系表达式。
- 优化:SQL 查询可以用多种不同的方式编写。优化的查询还取决于数据在文件组织中的存储方式。一个Query也可以有不同的关系表达式来对应。
- 执行计划:执行计划由系统地逐步执行基本操作组成,以从数据库获取数据。对于特定查询,不同的评估计划有不同的查询成本。包括磁盘访问次数、执行查询的 CPU 时间、分布式数据库情况下的通信时间等。
2. SQL查询优化
SQL 查询优化被定义为在执行时间、磁盘访问次数以及更多成本之间增强和加速查询性能的过程。应以尽可能最快的方式访问数据,以增强用户使用应用程序时的体验。
SQL查询优化的目的:
- 减少响应时间: 主要目标是通过减少响应时间来提高性能。用户请求数据和获得响应之间的时间差应最小化,从而获得更好的用户体验。
- 减少 CPU 执行时间:必须减少查询的 CPU 执行时间,更快的获得结果。
- 提高吞吐量:应尽量减少获取所有必要数据所需访问的资源数量。
3. 常见的SQL 查询优化技巧
3.1 使用SELECT 字段名,而不是使用 SELECT *
仅从表中获取必要的数据,而不是获取所有数据。
比如:
SELECT * FROM Business
更高效的查询写法是:
SELECT name , age , gender FROM Business
这个查询要简单得多,只从表中提取所需的详细信息。
3.2 尽量避免在 SELECT 中使用 DISTINCT
SELECT DISTINCT 是从数据库中删除重复项的简单方法,也可以通过和 GROUP BY 子句来生成不同的结果,该子句对查询中的所有字段进行分组。然而,要做到这一点需要消耗大量的处理能力。因此,在 SELECT 查询中避免DISTINCT。
3.3 正确的使用索引
正确的使用索引可以减少常用语句的执行时间。
比如:
CREATE INDEX index_optimizer ON Business(id);
3.4 要检查记录是否存在,使用 EXISTS而不是 COUNT
EXISTS() 和 COUNT() 方法都可以用来检查表中记录条目的存在。
EXISTS() 方法更有效,因为一旦找到表中记录的第一个条目,它就会退出处理。
COUNT() 方法将扫描整个表以返回表中与所提供的约束匹配的记录数。
比如:
SELECT count(id) FROM Business
更有效的写法是:
EXISTS (SELECT (id) FROM Business)
3.5 使用limit限制结果集大小
检索的数据越少,查询运行的速度就越快。
3.6 尽量使用 WHERE 而不是 HAVING
HAVING 子句在选择所有行后过滤行。
HAVING 语句在 SQL 操作中确定顺序在 WHERE 语句之后。因此,执行 WHERE 查询会更快。
比如:
SELECT c.ID, c.CompanyName, b.CreatedDate FROM Business b
JOIN Company c ON b.CompanyID = c.ID
GROUP BY c.ID, c.CompanyName, b.CreatedDate
HAVING b.CreatedDate BETWEEN ‘2020-01-01’ AND ‘2020-12-31’
更有效的写法:
SELECT c.ID, c.CompanyName, b.CreatedDate FROM Business b
JOIN Company c ON b.CompanyID = c.ID
WHERE b.CreatedDate BETWEEN ‘2020-01-01’ AND ‘2020-12-31’
GROUP BY c.ID, c.CompanyName, b.CreatedDate
3.7 忽略链接子查询
链接子查询取决于来自父级或外部源的查询。它是逐行运行的,因此平均循环速度受到很大影响。
比如:
SELECT b.Name, b.Phone, b.Address, b.Zip, (SELECT CompanyName FROM Company WHERE ID = b.CompanyID) AS CompanyName FROM Business b
对于外部查询返回的每一行,每次都会运行内部查询。或者,可以使用 JOIN 来解决 SQL 数据库优化的这些问题。
SELECT b.Name, b.Phone, b.Address, b.Zip, c. CompanyName FROM Business b
Join Company c ON b.CompanyID = c.ID
4. 总结
在本文中,我们介绍了优化 SQL 查询的一些技巧。通常,对查询速度产生最大影响的因素是正确使用索引。希望本文中的内容能帮助到你。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 搅拌站智能上料系统,无人值守,均匀布撒!
- 【无标题】
- 企业电脑主机管控软件—企业电脑管理软件评测
- 基于C/C++的Chinese中文编码dll封装使用
- 量化择时——动量策略
- Redis专题(持续更新)
- 基于SSM酒店后台管理系统【源码】【最详细运行文档】
- 渐进增强与优雅降级:提升用户体验的双重策略
- 代码随想录27期|Python|Day21|二叉树| 530.二叉搜索树的最小绝对差| 501.二叉搜索树中的众数| 236. 二叉树的最近公共祖先
- C语言中关于函数和数组的理解