c++学习笔记(8)-内存对齐
1、概念
C++中的内存对齐是指,编译器在将变量分配到内存中时按照一定规则进行调整,使得变量在内存中的地址满足一定的要求。具体来说,内存对齐是将变量的起始地址调整为其自身大小或者某个值的倍数,这个值称为“对齐系数”。在介绍内存对齐前补充几个概念——对齐系数,为便于理解,个人把它分为2类:
绝对对齐系数:每种类型数据在内存中的首地址必须是绝对对齐系数内存系数的整数倍。在默认情况下,绝对对齐系数等于该类型数据的默认对齐系数。
相对对齐系数:结构体内的数据相对于结构体起始地址的偏移量,单位为字节,结构体成员在结构体中的偏移量必须是该成员相对对齐系数的整数倍。在默认情况下,相对对齐系数等于该类型数据的默认对齐系数。
2、默认内存对齐
默认情况下,绝对对齐系数和相对对齐系数等于默认对齐系数。默认对齐系数:是数据的固有属性。对于基本数据类型,它的默认对齐系数,等于该数据类型占用字节大小;对于结构体类型,它的默认对齐系数等于,结构体成员中占用空间最大的基本数据类型占用字节大小。
2.1、基本类型
对于基本数据类型,一个变量在内存中的地址必须是其自身大小(以字节为单位)的整数倍。比如int 类型的变量大小为4,也就是说它的绝对对齐系数为4,因此它的地址必须是 4 的倍数。
另外,在64位系统中,long和 指针类型都是8
2.2、结构体类型
对于结构体类型,第一,结构体的起始地址必须是结构体成员中占用空间最大的基本数据类型的整数倍,且结构体大小也必须是其整数倍;第二,结构体内的成员,在结构体中的偏移量必须是该成员相对对齐系数的整数倍。举个例子:
struct MyStruct {
char c;
int i;
short s;
};
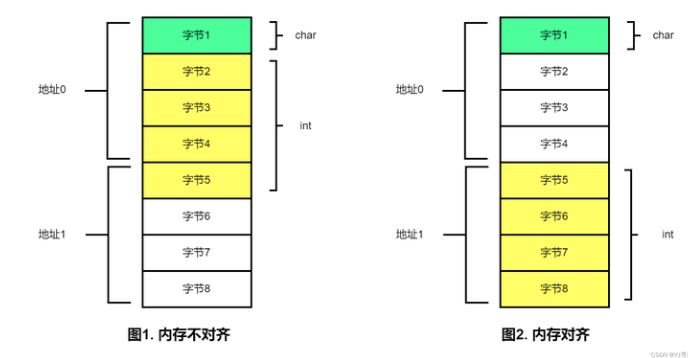
对于该结构体,char类型占 1 个字节,int类型占 4 个字节,short类型占 2 个字节,由于int类型的大小最大,因此该结构体的默认对齐系数是 4,推导出绝对对齐系数为4,该结构体起始地址必须为 4 的倍数;c在相对对齐系数为1,因此偏移为0,i的相对对齐系数为4,因此偏移为4,s相对对齐系数为2,因此偏移为8;该结构体的总大小为绝对对齐系数4的整数倍,因此12个字节。
3、显式内存对齐
在 C++ 中,也可以使用关键字来显式地指定对齐系数。C++11以前关于显式指定内存对齐没有标准规定,为了满足对“显式指定内存对齐”的需求,编译器厂家引入了各自的关键字,包括__attribute__((aligned)) 、#pragma pack等;C++11以后,显式指定内存对齐的语法被纳入标准,新增了alignas、alignof等关键字用于内存对齐。接下来对这些关键字进行介绍。
3.1、pragma pack
#pragma pack虽然不是官方标准,但现代编译器基本都对该关键字予以了支持。#pragma pack(N) ,N必须为2的正数幂,有两个作用:
- 当N大于该结构体的默认对齐系数时候,结构体绝对对齐系数被设置为N,当N小于该结构体的默认对齐系数时候,结构体绝对对齐系数维持为默认对齐系数。
- 当N小于该结构体的默认对齐系数时候,结构体内所有成员的相对对齐系数被设置为N,当N大于该结构体的默认对齐系数时候,结构体内成员的相对对齐系数维持为默认对齐系数。
例如,当N小于结构体默认对齐系数的时候:
#pragma pack(1)
//首地址为4的倍数
struct MyStruct {
char c;//相对偏移:0
int i;//相对偏移:1
short s;//相对偏移:5
};
#pragma pack()
再例如,当N大于结构体默认对齐系数的时候:
#pragma pack(8)
//首地址为8的倍数
struct MyStruct {
char c;//相对偏移:0
int i;//相对偏移:4
short s;//相对偏移:8
};
#pragma pack()
3.2、alignas
用于设置指定对齐系数。alignas(N) 表示把绝对对齐系数设置为N字节,N必须是2的正数幂。注意和#pragma pack不同的是,该关键字不能指定结构体的相对对齐系数。
- 当N大于该结构体的默认对齐系数时候,结构体绝对对齐系数被设置为N,当N小于该结构体的默认对齐系数时候,结构体绝对对齐系数维持为默认对齐系数。
例如当N小于结构体默认对齐系数的时候:
//首地址为4的倍数
struct alignas(1) MyStruct {
char c;//相对偏移:0
int i;//相对偏移:4
short s;//相对偏移:8
};
再例如,当N大于结构体默认对齐系数的时候:
//首地址为8的倍数
struct alignas(8) MyStruct {
char c;//相对偏移:0
int i;//相对偏移:4
short s;//相对偏移:8
};
3.3、alignof
alignof 操作符:用于获取指定类型的对齐系数,返回一个 size_t 类型的值。它的使用方式如下:
#include <iostream>
#include <type_traits>
int main() {
std::cout << alignof(int) << '\n'; //输出:4
std::cout << alignof(double) << '\n'; //输出:8
std::cout << alignof(char[7]) << '\n'; //输出:1
return 0;
}
3.4、std::aligned_storage
std::aligned_storage 是 C++11 标准库中的一个模板类,用于创建固定大小和对齐要求的未初始化内存,缓冲区适合存储任何类型。它有两个参数:
template <std::size_t Len, std::size_t Align = alignof(std::max_align_t)>
struct aligned_storage {/**/};
第一个参数表示内存块的大小,以字节为单位;第二个参数表示对齐系数,大小要求必须是2的正数幂。例如,以下代码创建了一块大小为16字节、对齐系数为8字节的内存:
#include <type_traits>
// 创建一个指定大小和对齐要求的 std::aligned_storage 类型
using my_storage_type = std::aligned_storage<16, 8>::type;
int main()
{
// 使用 my_storage_type 类型创建一个未初始化的原始内存缓冲区
my_storage_type buffer;
// 可以使用placement new将任何类型放入这个缓冲区,需要满足对齐要求
int* p_int = new (&buffer) int(42);
// 记得在程序结束前手动释放资源
p_int->~int();
return 0;
}
3.5、std::aligned_union
std::aligned_union 用于创建一个可以存储给定类型中最大的那个类型对象的内存,并且满足对齐要求。它有两个参数:
template <std::size_t Len, class... Types>
struct aligned_union {/**/};
其中,第一个参数Len表示要创建的内存块的大小(以字节为单位),第二个参数Types是一系列可以被存储在这块内存块的类型,当创建内存块时,std::aligned_union会找到这些类型中最大的那个类型,并把该类型的默认对齐系数设置为这块内存的绝对对齐系数。例如:
std::aligned_union<sizeof(double), int, double>::type data;
在这个例子中,我们指定了内存块的大小为sizeof(double)字节,可存储的类型为int和double,对齐系数为8(即double的大小)。需要注意的是,如果指定的Len小于所选的类型中最大的那个类型的大小,则内存块大小为最大的那个类型的大小。例如,在以下代码中:
std::aligned_union<4, int, double>::type data;
由于4字节无法容纳double类型,所以std::aligned_union会将内存块的大小调整为8(即double的大小),并确保对齐要求为8。
4、内存对齐的应用
内存对齐在计算机领域的应用非常广泛。以下是一些常见的应用场景:
4.1、提高程序性能
内存对齐的主要目的是优化 CPU 对内存的读写操作。现代计算机通常使用 “ 字(word)”作为内部数据交换的基本单位,字是 CPU 在一次内存读写操作中能处理的最大数据块。变量占据内存大小等于字长,如果其首地址在字长的整数倍处,CPU只需要读内存一次;如果其首地址不在字长整数倍处,CPU则需要读地址两次,影响程序性能。
4.2、平台移植
不同平台对内存对齐的要求也有所不同,比如说:在 C 语言标准中,并没有明确规定 short 数据类型的长度应该是多少。通常情况下,short 被定义为一个整数类型,其长度通常为 2 个字节(16 位),用于表示相对较小的整数值。然而,在某些平台上,short 的长度可能会不同。例如,在一些嵌入式系统中,由于存储空间有限,可能会将 short 定义为 1 个字节或者其他长度,以节省空间和提高性能。
如果没有考虑到这一点,在移植过程中可能会出现问题,例如结构体大小不一致等。使用内存对齐可以保证数据在内存中按照一定的规则存储,提高代码的可移植性。
4.3、SIMD 与内存对齐
SIMD (Single Instruction Multiple Data)即单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单来说就是一个指令能够同时处理多个数据。
在 SIMD 中,内存对齐需要被特别注意和优化,因为 SIMD 操作通常会同时处理多个数据元素。如果数据在内存中没有按照合适的方式进行对齐,那么这些数据很可能无法被同时加载到 SIMD 寄存器中,从而导致额外的内存访问、数据拷贝或者其他操作,进而降低程序的性能。
下面以 x86 平台下的 SSE (Streaming SIMD Extensions)指令为例来说明内存对齐在 SIMD 中的应用。该架构使用128位的向量寄存器,数据总线长度位128位,每次能读取16字节。假设有以下的代码:
alignas(16) float A[4];
alignas(16) float B[4];
alignas(16) float C[4];
for (int i = 0; i < 4; i++) {
C[i] = A[i] + B[i];
}
在这段代码中,由于浮点数默认是按照 4 字节对齐的,数组的首地址是4的倍数,因此如果数组没有进行显式对齐,那么每次计算4个浮点数可能就需要进行两次内存读写。然而,由于数组已经按照16字节对齐,每次计算4个浮点数就只需要进行一次内存读写。
5、总结
C++11中的内存对齐特性可以帮助开发人员更好地控制内存对齐规则,从而提高程序的性能和节省内存空间。在实际开发中,需要根据具体应用场景选择适当的内存对齐方式。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!