爬虫系列----Python解析Json网页并保存到本地csv
Python解析JSON
1 知识小课堂
1.1 爬虫

- Python爬虫(Python Spider)是一种使用Python编程语言编写的程序,用于自动从互联网上抓取数据。这些数据可以是网页内容、图片、视频或其他资源。爬虫程序通常用于数据挖掘、信息收集、竞争情报分析等领域。
- Python爬虫通常使用第三方库来实现,如BeautifulSoup、Scrapy等。这些库提供了方便的API和工具,使得开发者可以轻松地编写爬虫程序。
1.2 JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它基于ECMAScript(欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
JSON具有以下特点:
- 易于人阅读和编写,可以在多种语言之间进行数据交换。
- 简洁和清晰的层次结构使得JSON成为理想的数据交换语言。
- 易于机器解析和生成,并有效地提升网络传输效率。
- JSON的语法规则包括:
JSON对象:对象是一个无序的"名称/值"对集合。一个对象以"{(“开始,”}(“结束。每个"名称"后跟一个”:“(冒号);“名称/值"对之间使用”,”(逗号)分隔。
JSON数组:数组是一个有序的"值"集合,一个数组以"[(“开始,”](“结束,值之间使用”,"(逗号)分隔。JSON对象、JSON数组可以嵌套。
JSON的应用非常广泛,包括但不限于数据交换、配置文件、API请求等场景。由于其易于读写、解析和生成的特点,使得JSON成为了一种理想的数据交换格式。
1.3 Python
当然可以,Python是一种广泛使用的编程语言,可以用于各种不同的任务,包括数据分析和处理。Python有许多库和工具可以用于处理JSON数据,其中最常用的是json模块。
1.4 前言技术
1.4.1 range
在Python中,range()是一个内置函数,用于生成一个整数序列。它通常用于循环结构(如for循环)中,以控制循环的迭代次数。
range()函数可以接受1到3个参数:
- 只有一个参数(例如 range(5)),则表示从0开始,到该参数的整数(但不包括该参数的整数),即 [0, 1, 2, 3, 4]。
- 有两个参数(例如 range(1, 5)),则表示从第一个参数的整数开始,到第二个参数的整数(但不包括该参数的整数),即 [1, 2, 3, 4]。
- 有三个参数(例如 range(1, 5, 2)),则表示从第一个参数的整数开始,到第二个参数的整数(但不包括该参数的整数),步长为第三个参数的整数。例如,range(1, 5, 2)会生成 [1, 3, 5]。
此外,还可以使用range()函数与切片操作结合使用,以生成指定范围的序列。例如:
# 从1到5(包含5)
numbers = list(range(1, 6)) # 结果:[1, 2, 3, 4, 5]
# 从0开始,每次加2,直到10(包含10)
even_numbers = list(range(0, 11, 2)) # 结果:[0, 2, 4, 6, 8, 10]
1.4.2 random
Python的random模块提供了一系列的函数用于生成随机数。下面是一些最常用的random模块方法:
- random():返回[0.0, 1.0)范围内的下一个随机浮点数。
import random
print(random.random()) # 输出类似于0.123456789的随机数
- randint(a, b):返回指定范围内的随机整数,包含端点a和b。
import random
print(random.randint(1, 10)) # 输出1到10之间的随机整数,包括1和10
- randrange(start, stop[, step]):返回指定范围内的随机整数,类似于内建函数range()。可以指定步长。
import random
print(random.randrange(1, 10, 2)) # 输出1到9之间的随机奇数
- choice(seq):从非空序列seq中返回一个随机元素。如果seq为空,则引发IndexError。
import random
my_list = [1, 2, 3, 4, 5]
print(random.choice(my_list)) # 从my_list中随机选择一个元素并输出
- shuffle(seq[, random]):将序列seq的所有元素随机排序。可选参数random是一个0到1之间的浮点数,用于指定随机算法的种子值。
import random
my_list = [1, 2, 3, 4, 5]
random.shuffle(my_list)
print(my_list) # 输出类似于[2, 1, 5, 3, 4]的随机排序列表
- uniform(a, b):返回指定范围内的随机浮点数,范围在a和b之间(包含a和b)。
import random
print(random.uniform(1.0, 2.0)) # 输出1.0到2.0之间的随机浮点数,包括1.0和2.0
- seed(a[, version]):使用种子值a初始化随机数生成器。如果不提供种子值,则使用系统时间作为默认种子。可选参数version用于指定随机数生成器的版本,默认为2。
import random
random.seed(1) # 设置种子值为1,确保每次运行程序时生成的随机数序列相同
print(random.random()) # 输出相同的随机数,因为种子值固定了随机数生成器的起始状态
1.4.3 time.sleep
time.sleep() 是 Python 标准库中 time 模块的一个方法,用于使程序暂停执行指定的秒数。
示例:
import time
print("开始")
time.sleep(2) # 暂停2秒
print("结束")
输出:
开始
(程序会暂停2秒)
结束
1.4.4 with open() as f:
with open(文件地址,‘a’ ,newline = '',encoding='utf-8-sig') as f:
2 解析过程
2.1 简介
- 将网站中的json文件爬取下来存到本地表格中。爱购云-商机发现
2.2 打开调试工具
本文尝试使用的是【google】
选择【Fetch/XHR】点击做上交的 按钮,清空管理台。
按钮,清空管理台。

清空管理台

2.3 分析网址
2.3.1 网址的规律
打开网址,滑倒下面分页,选择【2】点击,发现左侧出现一个文件。


点开找个文件,发现是JSon数据。
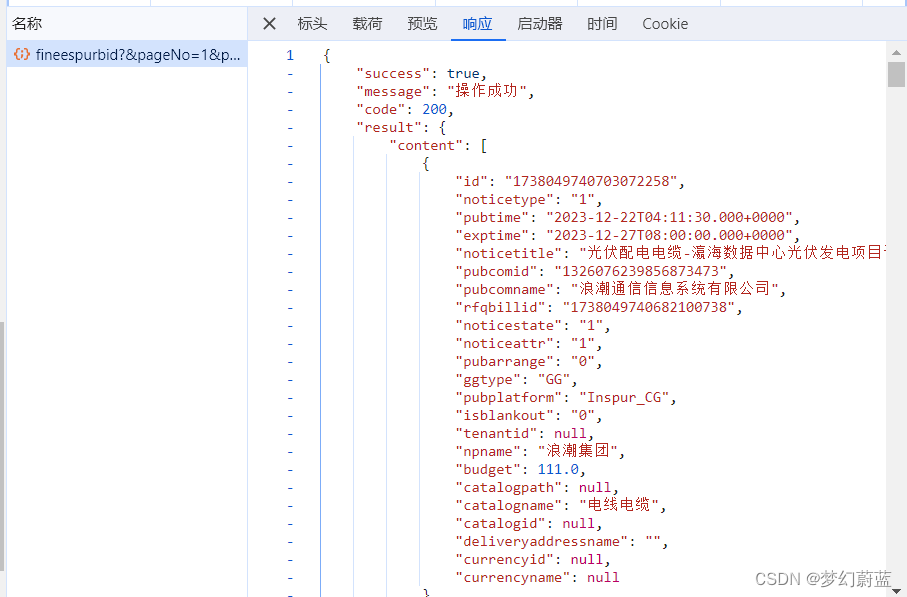
将它在新标签页中打开。

在新页面中打开。复制一下网址。
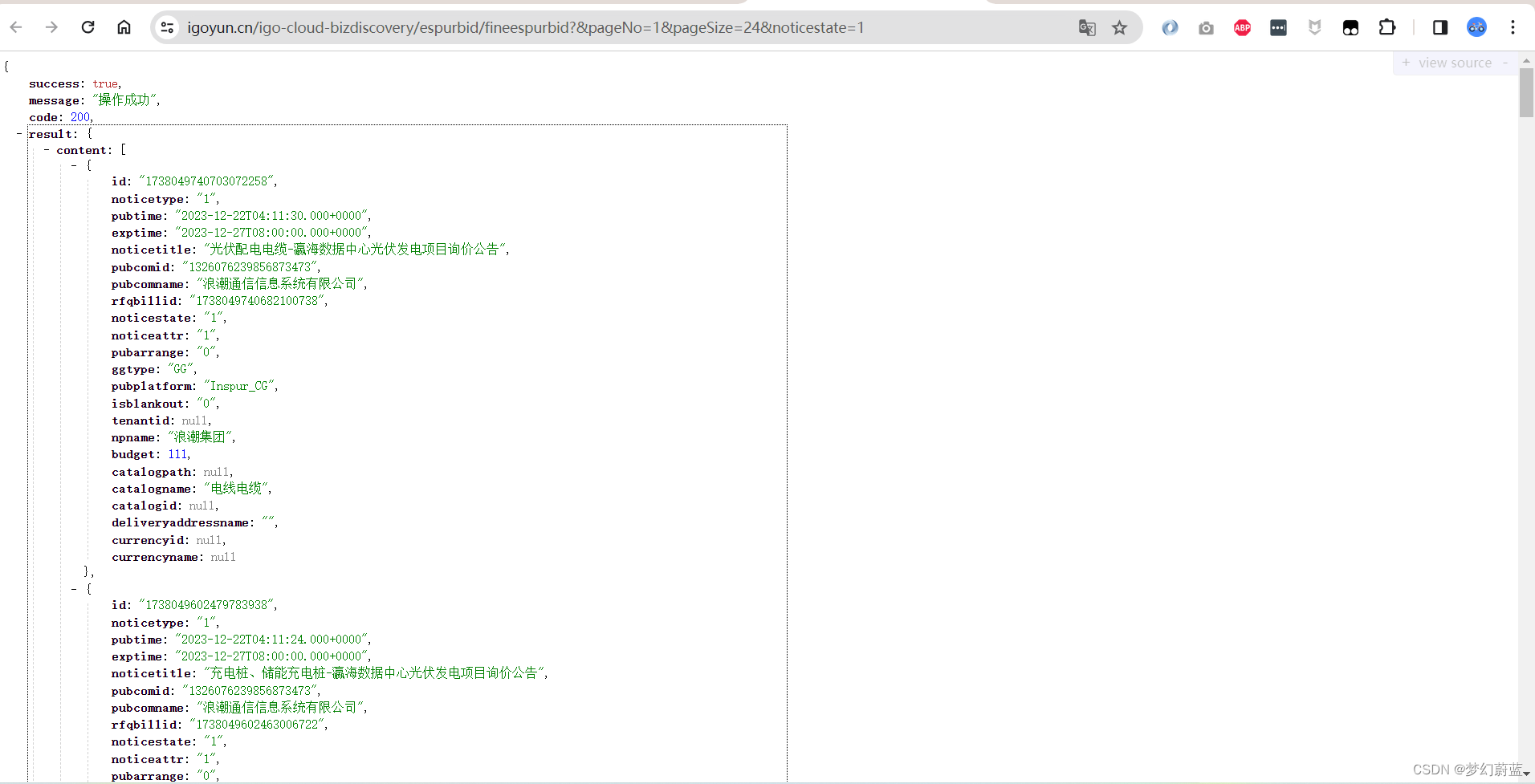
返回到分页处,点【3】,发现右侧又出现一个文件。

同理,在新标签页中打开,并复制网址。

同样的方法复制页码【1】的网址。
页码【1】https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=1
页码【2】https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=1&pageSize=24¬icestate=1
页码【3】https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=2&pageSize=24¬icestate=1
由以上分析可知,只有pageNo不同,并据此可推断出,第N页的网址应该是pageNo=N-1,到此为止,我们已经推断出来网址的规律。另外两个参数是什么?
2.3.2 网址的参数
由上小结的页码一为例:页码【1】https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=1
网址包括
- 域名:https://www.igoyun.cn
- 文件路径:/igo-cloud-bizdiscovery/espurbid/fineespurbid?
- 参数:【pageNo=0】表示当前页码
- 参数:【pageSize=24】表示每页的数量
- 参数:【noticestate=1】还未知,我们来猜测一下。
进入网页:https://www.igoyun.cn/#/portal/search/business

点击页码【2】,查看右侧的json文件网址:
https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=1&pageSize=24¬icestate=1

返回网页:切换到以下选项
同样选择【2】,点开右侧json文件,查看网址。
https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=1&pageSize=24¬icestate=2
将以上两个网址放在一起比较:
进行中:https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=1&pageSize=24¬icestate=1
全部:https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=1&pageSize=24¬icestate=2
有分析可知:二者变量为:【全部/进行中】,网址区别为【noticestate=1/2】在此可以猜测,【noticestate】参数控制【全部/进行中】。为进一步确认推测是否正确,可以根据json文件数据和原网页进行对比。对比结果可知,二者是一致的。
回顾三个参数
由上小结的页码一为例:页码【1】https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=1
网址包括
- 域名:https://www.igoyun.cn
- 文件路径:/igo-cloud-bizdiscovery/espurbid/fineespurbid?
- 参数:【pageNo=0】表示当前页码
- 参数:【pageSize=24】表示每页的数量
- 参数:【noticestate=1】全部/进行中
根据需要进行爬取,这里选择noticestate= 2.
2.4 爬取第一页内容
url:https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=2
import requests
import random
import json
import time
now_time = int(time.time())
timeStamp = now_time*1000
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo={}&pageSize=24¬icestate=2'.format(a)
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
print(response.content.decode('utf-8'),type(response.content.decode('utf-8')))
代码解释:
- url 是网址
- headers 伪装成浏览器访问,
- response :用response 进行访问网址,对返回的数据进行UTF-8处理,显示能看懂的数据
运行文件,显示如下,表示已经获取json数据,接下来就是对这些数据进行处理。

2.5 存入字典并获取
1、存入数据字典
#爬取腾讯招聘网站
import requests
import json
import time
now_time = int(time.time())
timeStamp = now_time*1000
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=2'
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
# print(response.content.decode('utf-8'),type(response.content.decode('utf-8')))
content = response.content.decode('utf-8')
#需要将content(json.str)--->python对象的(json-dict)
content_dict = json.loads(content)
print(type(content_dict))

由打印可知,content_dict 的类型为【dict】字典类型
2、获取数据
主体数据保存在【content】中,那么怎么获取到这里的数据呢?
很简单,目前为止,已经获取到全部的数据,并将数据存到字典中【content_dict】
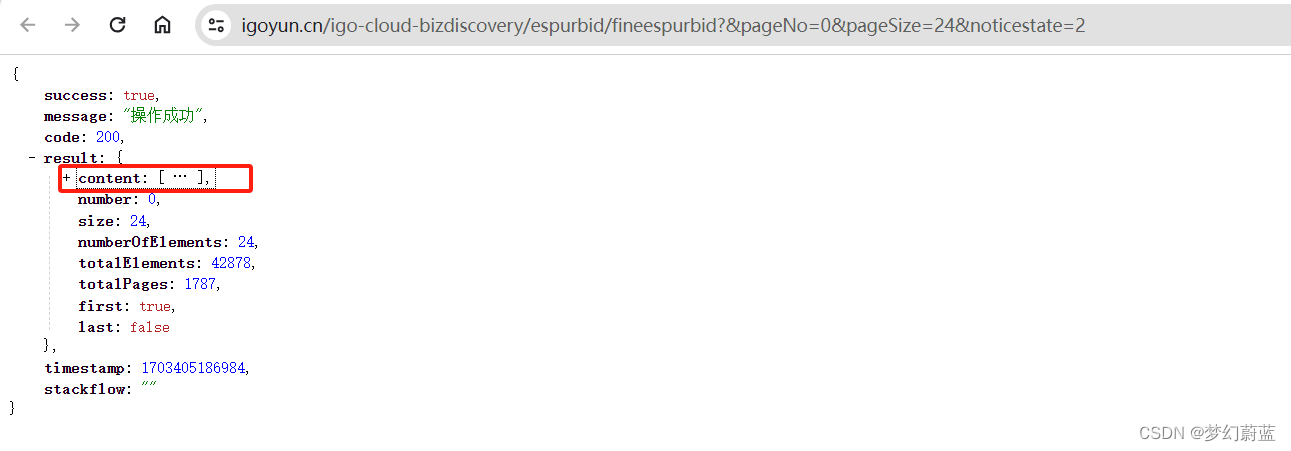
post_list = content_dict['result']['content']
- post_list 即为content的数据。
#爬取腾讯招聘网站
import requests
import json
import time
now_time = int(time.time())
timeStamp = now_time*1000
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=2'
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
# print(response.content.decode('utf-8'),type(response.content.decode('utf-8')))
content = response.content.decode('utf-8')
#需要将content(json.str)--->python对象的(json-dict)
content_dict = json.loads(content)
# print(type(content_dict))
post_list = content_dict['result']['content']
print(post_list)

2.6 循环主体数据
目前已经获取到【post_list】,可以对数据进行循环获取每一个数据的值。
需要获取的数据有:
- 公司名:-pubcomname
- 公告类型-noticetype
- 项目类型-catalogname
- 项目名称-noticetitle
- 发布时间-pubtime
- 截止时间-exptime
#爬取腾讯招聘网站
import requests
import json
import time
now_time = int(time.time())
timeStamp = now_time*1000
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=2'
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
content = response.content.decode('utf-8')
#需要将content(json.str)--->python对象的(json-dict)
content_dict = json.loads(content)
# print(type(content_dict))
post_list = content_dict['result']['content']
print(post_list)
# #将字典中的每一个dict都迭代出来
for value_dict in post_list:
# # # #公司名:-pubcomname
pubcomname = value_dict['pubcomname']
# # # #公告类型-noticetype
noticetype = value_dict['noticetype']
# # # #项目类型-catalogname
catalogname = value_dict['catalogname']
# # 项目名称-noticetitle
noticetitle = value_dict['noticetitle']
# # 发布时间-pubtime
pubtime = value_dict['pubtime']
# # 截止时间-exptime
exptime = value_dict['exptime']
# # # #print看看是否有打印出来
print(pubcomname,noticetype,catalogname,noticetitle,pubtime,exptime)
运行可知,打印了第一页所需要的内容
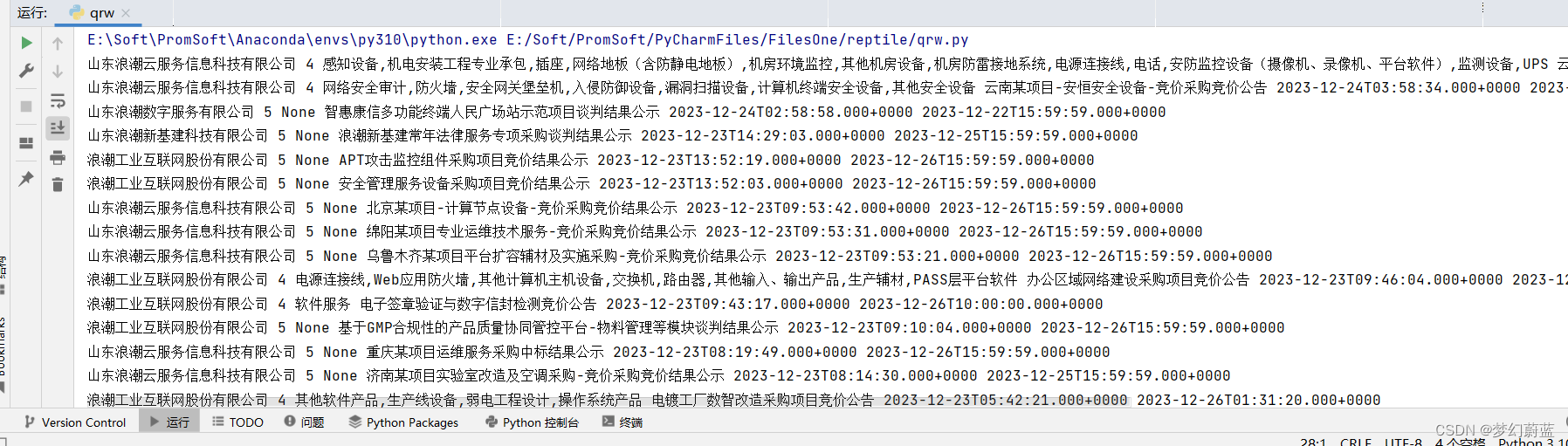
2.7 公告和日期改进
1、公告改进
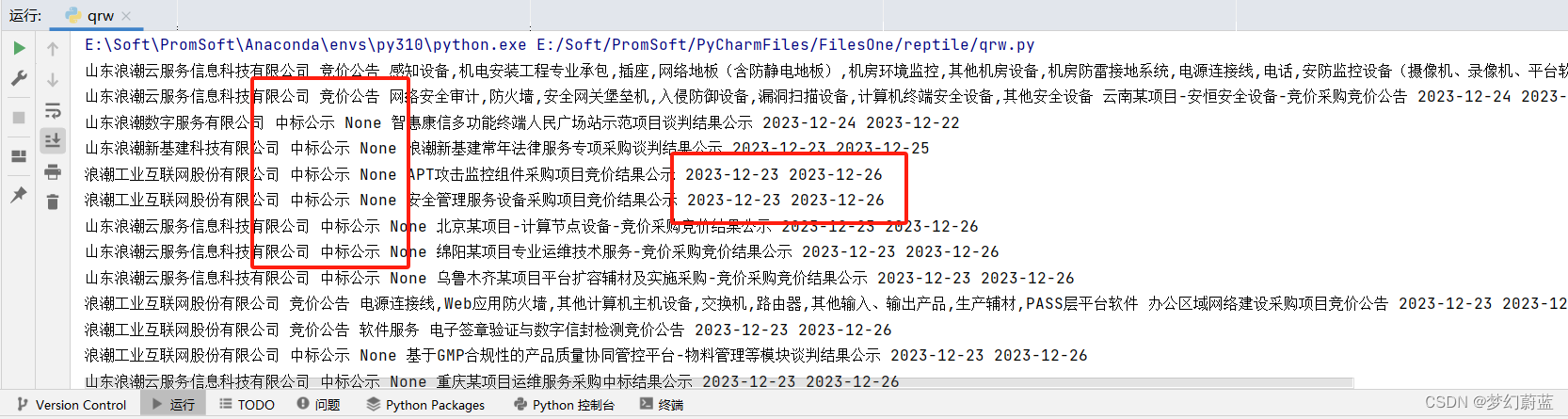
由输出结果可知,公告类型不是页面中的文字,而是数字代替。经过分析可知
- newNoticetype=1 为:‘询价公告’
- newNoticetype=2 为:‘采购/招标公告’
- newNoticetype=4 为:‘竞价公告’
- newNoticetype=5 为:‘中标公示’
- newNoticetype=6 为:‘竞争性谈判’
改进代码:
noticetype = value_dict['noticetype']
if noticetype=='1' :
newNoticetype='询价公告'
elif noticetype=='2' :
newNoticetype='采购/招标公告'
elif noticetype=='4' :
newNoticetype='竞价公告'
elif noticetype=='5' :
newNoticetype='中标公示'
elif noticetype=='6' :
newNoticetype='竞争性谈判'
else :
newNoticetype=noticetype
2、日期改进
日期显示的格式 2023-12-23T14:29:03.000+0000,我们可以只取年月日,这样就需要对数据进行截取。
# # 发布时间-pubtime
pubtime = value_dict['pubtime'][0:10]
# # 截止时间-exptime
exptime = value_dict['exptime'][0:10]
代码:
#爬取腾讯招聘网站
import requests
import json
import time
now_time = int(time.time())
timeStamp = now_time*1000
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo=0&pageSize=24¬icestate=2'
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
content = response.content.decode('utf-8')
#需要将content(json.str)--->python对象的(json-dict)
content_dict = json.loads(content)
post_list = content_dict['result']['content']
# #将字典中的每一个dict都迭代出来
for value_dict in post_list:
# # # #公司名:-pubcomname
pubcomname = value_dict['pubcomname']
# # # #公告类型-noticetype
noticetype = value_dict['noticetype']
if noticetype=='1' :
newNoticetype='询价公告'
elif noticetype=='2' :
newNoticetype='采购/招标公告'
elif noticetype=='4' :
newNoticetype='竞价公告'
elif noticetype=='5' :
newNoticetype='中标公示'
elif noticetype=='6' :
newNoticetype='竞争性谈判'
else :
newNoticetype=noticetype
# # # #项目类型-catalogname
catalogname = value_dict['catalogname']
# # 项目名称-noticetitle
noticetitle = value_dict['noticetitle']
# # 发布时间-pubtime
pubtime = value_dict['pubtime'][0:10]
# # 截止时间-exptime
exptime = value_dict['exptime'][0:10]
# # # #print看看是否有打印出来
print(pubcomname,newNoticetype,catalogname,noticetitle,pubtime,exptime)
2.8 循环获取前三页内容
1、循环
在最开始加上下面代码。
for a in range(3):
2、为了爬取的安全性,在获取一次请求之后,休眠1-3秒
引入:import random
在第二层循环中加上以下代码
time.sleep(random.randrange(1,3))
2.9 保存到CSV中
1、首先引入import csv
2、在第二层循环中加上
in_fo_list =[pubcomname,newNoticetype,catalogname,noticetitle,pubtime,exptime]
with open('E:/langchao.csv','a',newline = '',encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(in_fo_list)
-in_fo_list 表示暂时的存储序列
-encoding 表示存储的编码类型
3 完整代码
#爬取爱购云网站
import requests
import random
import json
import csv
import time
now_time = int(time.time())
timeStamp = now_time*1000
for a in range(3):
url = 'https://www.igoyun.cn/igo-cloud-bizdiscovery/espurbid/fineespurbid?&pageNo={}&pageSize=24¬icestate=2'.format(a)
headers = {
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url = url.format(timeStamp),headers = headers)
# response = requests.get(url = url,headers = headers)
# print(response.content.decode('utf-8'),type(response.content.decode('utf-8')))
content = response.content.decode('utf-8')
#需要将content(json.str)--->python对象的(json-dict)
content_dict = json.loads(content)
# print(content_dict,type(content_dict))
post_list = content_dict['result']['content']
# print(post_list)
#将字典中的每一个dict都迭代出来
time.sleep(random.randrange(1,3))
print(a)
for value_dict in post_list:
# # #公司名:-pubcomname
pubcomname = value_dict['pubcomname']
# # #公告类型-noticetype
noticetype = value_dict['noticetype']
if noticetype=='1' :
newNoticetype='询价公告'
elif noticetype=='2' :
newNoticetype='采购/招标公告'
elif noticetype=='4' :
newNoticetype='竞价公告'
elif noticetype=='5' :
newNoticetype='中标公示'
elif noticetype=='6' :
newNoticetype='竞争性谈判'
else :
newNoticetype=noticetype
# # #项目类型-catalogname
catalogname = value_dict['catalogname']
# 项目名称-noticetitle
noticetitle = value_dict['noticetitle']
# 发布时间-pubtime
pubtime = value_dict['pubtime'][0:10]
# 截止时间-exptime
exptime = value_dict['exptime'][0:10]
# # #print看看是否有打印出来
# print(pubcomname,newNoticetype,catalogname,noticetitle,pubtime,exptime)
# # #由于我们是要保存在CSV格式中,所以我们先把数据转化成列表模式.
in_fo_list =[pubcomname,newNoticetype,catalogname,noticetitle,pubtime,exptime]
with open('E:/langchao.csv','a',newline = '',encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(in_fo_list)
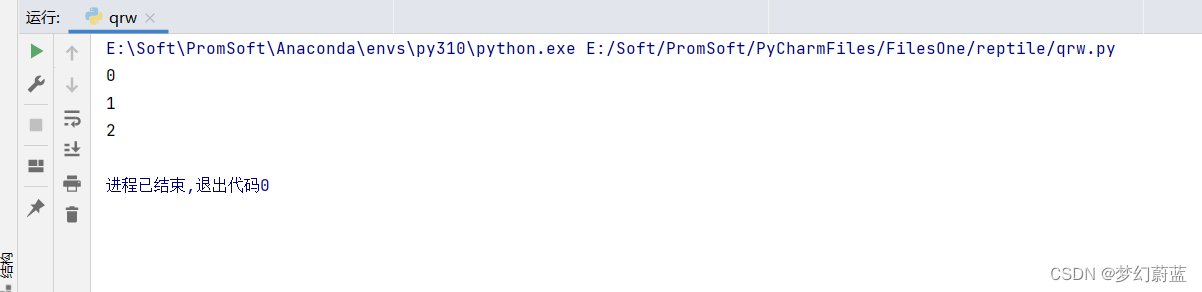
根据路径打开文件:

爬取成功!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 输电线路的“千里眼“?可视化图像在线监测装置技术解析!|深圳鼎信
- git学习
- Python学习之路——数据容器部分【列表(list)】
- vp与vs联合开发-通过FrameGrabber连接相机
- vue3.0 通用管理页面封装
- Mybatis-plus分页插件PageHelper的两种不同使用方式
- 牛客竞赛算法入门题单打卡 K Number
- 复杂字幕特效SDK,重塑视频字幕新体验
- 鸿蒙OS应用开发之多选按钮
- 计算机网络简述