奇异值分解(SVD)【详细推导证明】
机器学习笔记
机器学习系列笔记,主要参考李航的《机器学习方法》,见参考资料。
第一章 机器学习简介
第二章 感知机
第三章 支持向量机
第四章 朴素贝叶斯分类器
第五章 Logistic回归
第六章 线性回归和岭回归
第七章 多层感知机与反向传播【Python实例】
第八章 主成分分析【PCA降维】
第九章 隐马尔可夫模型
第十章 奇异值分解
奇异值分解(Singular Value Decomposition)是线性代数中一种重要的矩阵分解,奇异值分解则是特征分解在任意矩阵上的推广。在信号处理、统计学等领域有重要应用。奇异值分解在统计中的主要应用为主成分分析(PCA),PCA算法的作用是把数据集映射到低维空间中去。 数据集的特征值(在SVD中用奇异值表征)按照重要性排列,降维的过程就是舍弃不重要的特征向量的过程,而剩下的特征向量组成的空间即为降维后的空间。
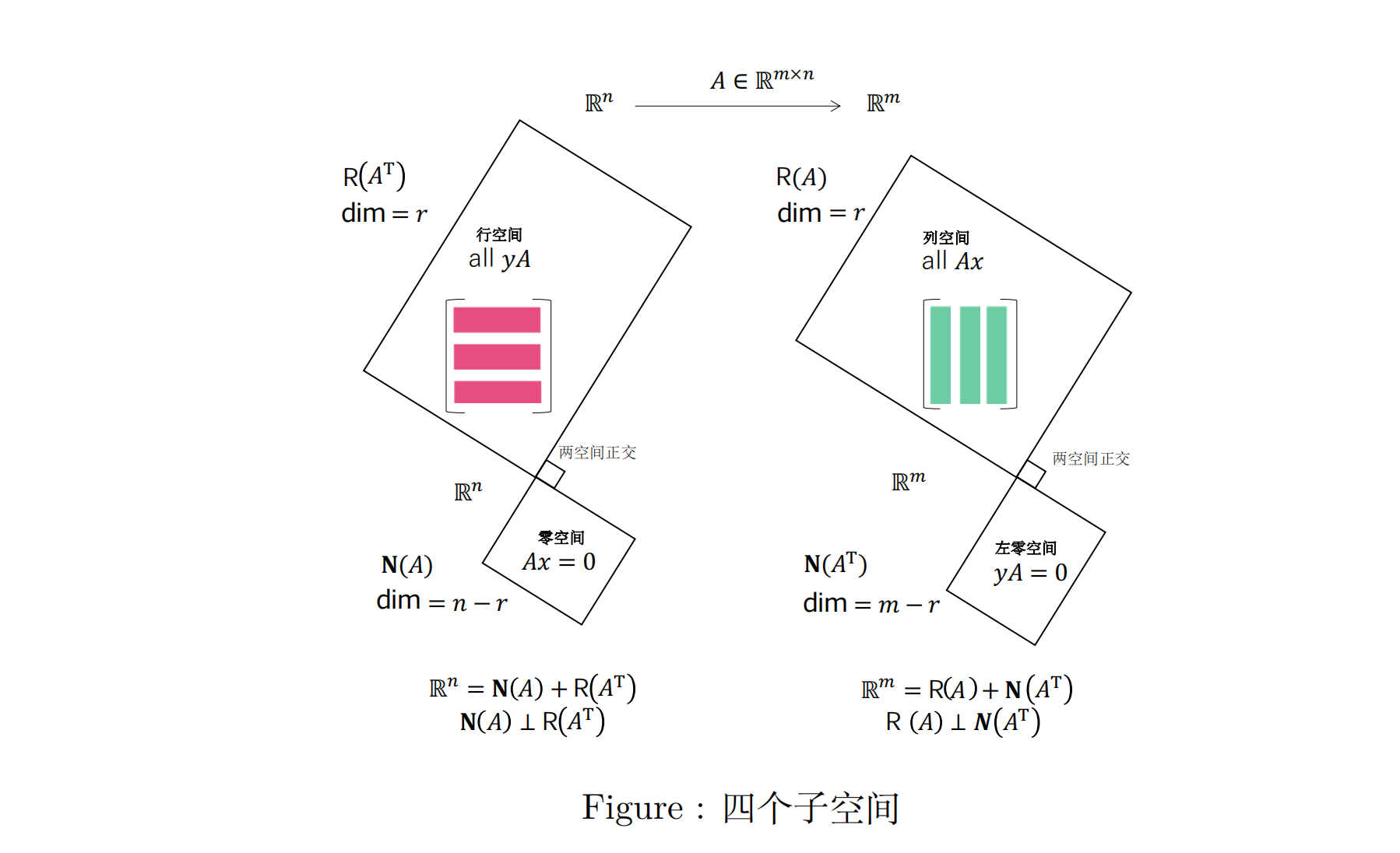
一、矩阵的基本子空间
对非零矩阵 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n,其秩 rank ( A ) = r (A)=r (A)=r , r ≤ min ? { m , n } . r\leq\min\{m,n\}. r≤min{m,n}. A A A的四个基本子空间:
-
A
A
A的列空间(
A
A
A的值域):
R ( A ) = { z ∈ R m ∣ ? x ∈ R n , z = A x } R(A)=\{z\in\mathbb{R}^m|\exists x\in\mathbb{R}^n,z=Ax\} R(A)={z∈Rm∣?x∈Rn,z=Ax} -
A
A
A的零空间:
N ( A ) = { x ∈ R n ∣ A x = 0 } . N(A)=\{x\in\mathbb{R}^n|Ax=0\}. N(A)={x∈Rn∣Ax=0}. -
A
A
A的行空间(
A
T
A^T
AT的值域):
R ( A T ) = { y ∈ R n ∣ ? x ∈ R m , y = A T x } R(A^T)=\{y\in\mathbb{R}^n|\exists x\in\mathbb{R}^m,y=A^Tx\} R(AT)={y∈Rn∣?x∈Rm,y=ATx} - A A A的左零空间( A T A^T AT的零空间):
N ( A T ) = { x ∈ R m ∣ A T x = 0 } . N(A^T)=\{x\in\mathbb{R}^m|A^Tx=0\}. N(AT)={x∈Rm∣ATx=0}.
四个子空间的关系如下图所示,我们证明其中两条:
- R ( A ) ⊥ N ( A T ) R(A)\perp N(A^{\mathrm{T}}) R(A)⊥N(AT)
证明:
? z ∈ R ( A ) , y ∈ N ( A T ) \forall z\in R(A),y\in N(A^T) ?z∈R(A),y∈N(AT),有
< z , y > = z T y = ( A x ) T y = x T A T y = 0 <z,y>=z^Ty=(Ax)^Ty=x^TA^Ty=0 <z,y>=zTy=(Ax)Ty=xTATy=0
所以 z ⊥ y z\perp y z⊥y,证毕.
- dim ? ( R ( A ) ) + dim ? ( N ( A ) ) = n \operatorname{dim}(R(A))+\operatorname{dim}(N(A))=n dim(R(A))+dim(N(A))=n(秩零定理)
证明:
矩阵A的零空间就Ax=0的解的集合,则零空间的维数为n-r。因为秩为r,则自由变量的个数为n-r,有几个自由变量,零空间就可以表示成几个特解的线性组合,也即是零空间的维数为自由变量的个数。
二、舒尔分解
在介绍奇异值分解之前,我们首先介绍一下Schur分解,利用Schur分解,可以导出奇异值分解.
Schur decomposition
For each KaTeX parse error: Undefined control sequence: \C at position 5: A\in\?C?^{n\times{n}} with eigenvalue λ 1 , λ 2 , ? ? , λ n \lambda_1,\lambda_2,\cdots,\lambda_n λ1?,λ2?,?,λn? in any prescribed order,there exist unitary matrix U ∈ C n × n s.t ? . T = U ? A U U\in C^{n\times n} \operatorname{s.t}. T=U^*AU U∈Cn×ns.t.T=U?AU is an upper triangle matrix with diagonal entries t i i = λ i t_{ii}=\lambda_i tii?=λi?:
T = [ λ 1 t 12 ? t 1 n 0 λ 2 ? ? 0 ? λ n ? 1 t n ? n 0 ? ? λ n ] . T = \left.\left[\begin{matrix} \lambda_{1}&t_{12}&\cdots&t_{1n}\\ 0 &\lambda_{2}&\cdots&\vdots\\ 0 &\cdots &\lambda_{n-1}&t_{n-n}\\ 0 &\cdots &\cdots &\lambda_{n}\end{matrix}\right.\right]. T= ?λ1?000?t12?λ2??????λn?1???t1n??tn?n?λn?? ?.

- 也就是说Hermitian矩阵的Schur分解其实就是特征值分解.
- Hermitian矩阵一定可以进行对角化.(实对称矩阵也一定可以对角化)

三、奇异值分解
(1)定义

(2)证明
因为
A
∈
R
m
×
n
A\in\mathbb{R}^{m\times n}
A∈Rm×n(不妨设
m
>
n
m>n
m>n,且
rank
?
(
A
)
=
r
\operatorname{rank}( A) = r
rank(A)=r),所以
A
T
A
A^TA
ATA和
A
A
T
AA^T
AAT都是对称的实矩阵,我们以
A
T
A
A^TA
ATA为例,由Schur分解知,一定存在正交矩阵
V
∈
R
n
×
n
V\in\mathbb{R}^{n\times n}
V∈Rn×n,使得:
V
T
A
T
A
V
=
Λ
=
diag
?
(
λ
1
,
λ
2
,
?
?
,
λ
n
)
=
Σ
T
Σ
V^TA^TAV=\Lambda=\operatorname{diag}(\lambda_1,\lambda_2,\cdots,\lambda_n)=\Sigma^T\Sigma
VTATAV=Λ=diag(λ1?,λ2?,?,λn?)=ΣTΣ其中
λ
1
≥
λ
2
≥
?
λ
n
≥
0
\lambda_1\geq\lambda_2\geq\cdots\lambda_n\geq 0
λ1?≥λ2?≥?λn?≥0,此时矩阵
V
V
V我们已经有了,就是
A
T
A
A^TA
ATA的特征向量矩阵,那么如何构造
U
U
U呢?我们首先给出一个引理:
rank ? ( A T A ) = rank ? ( A ) = r . \operatorname{rank}( A^TA) = \operatorname{rank}( A) = r. rank(ATA)=rank(A)=r.
证明:设 x ∈ R n x\in\mathbb{R}^n x∈Rn,则
A x = 0 ? A T A x = 0 ; Ax=0\Rightarrow A^TAx=0; Ax=0?ATAx=0;
反之,
A T A x = 0 ? x T A T A x = 0 ? ∥ A x ∥ 2 2 = 0 ? A x = 0. A^TAx=0\quad\Rightarrow\quad x^TA^TAx=0\quad\Rightarrow\parallel Ax\parallel_2^2=0\quad\Rightarrow Ax=0. ATAx=0?xTATAx=0?∥Ax∥22?=0?Ax=0.
A T A A^TA ATA和 A A A的零空间相同,因此 rank ? ( A T A ) = rank ? ( A ) = r . \operatorname{rank}( A^TA) = \operatorname{rank}( A) = r. rank(ATA)=rank(A)=r.
由
rank
?
(
A
T
A
)
=
rank
?
(
A
)
=
r
\operatorname{rank}( A^TA) = \operatorname{rank}( A) = r
rank(ATA)=rank(A)=r,则
λ
1
≥
λ
2
≥
?
≥
λ
r
>
0
,
λ
r
+
1
=
?
=
λ
n
=
0.
\lambda_1\geq\lambda_2\geq\cdots\geq\lambda_r>0,\\ \lambda_{r+1}=\cdots=\lambda_n=0.
λ1?≥λ2?≥?≥λr?>0,λr+1?=?=λn?=0.
我们将
V
V
V分成两部分
V
=
[
V
1
,
V
2
]
V=[V_1,V_2]
V=[V1?,V2?],其中
V
1
=
[
v
1
,
?
?
,
v
r
]
V_1=[v_1,\cdots,v_r]
V1?=[v1?,?,vr?],
V
2
=
[
v
r
+
1
,
?
?
,
v
n
]
.
V_2=[v_{r+1},\cdots,v_n].
V2?=[vr+1?,?,vn?].
- v r + 1 , ? ? , v n v_{r+1},\cdots,v_n vr+1?,?,vn?正好构成 A T A A^TA ATA的零空间 N ( A T A ) ( N(A^TA)( N(ATA)(也是 N ( A ) ) {N}(A)) N(A))的一组标准正交基.
- A V 2 = 0. AV_{2}=0. AV2?=0.
- I = V V T = V 1 V 1 T + V 2 V 2 T . I=VV^T=V_1V_1^T+V_2V_2^T. I=VVT=V1?V1T?+V2?V2T?.
- A = A I = A ( V 1 V 1 T + V 2 V 2 T ) = A V 1 V 1 T . A=AI=A(V_1V_1^T+V_2V_2^T)=AV_1V_1^T. A=AI=A(V1?V1T?+V2?V2T?)=AV1?V1T?.
同样的我们将
U
U
U分为两部分
U
=
[
U
1
,
U
2
]
U=[U_1,U_2]
U=[U1?,U2?],考察
A
V
=
U
Σ
AV=U \Sigma
AV=UΣ:
A
[
v
1
…
v
r
…
v
n
]
=
[
u
1
?
u
m
]
[
σ
1
0
?
σ
r
0
0
]
A
v
1
=
σ
1
u
1
?
u
1
=
A
v
1
σ
1
(
σ
1
≠
0
)
.
\begin{aligned} & A\left[\begin{array}{lll} v_1 & \ldots & v_r &\ldots v_n \end{array}\right]=\left[\begin{array}{lll} u_1 & \cdots & u_m \end{array}\right]\left[\begin{array}{ccc} \sigma_1 & 0 \\ \cdots & \sigma_r \\ 0 & & 0 \end{array}\right] \\ & Av_1=\sigma_1u_1\Rightarrow u_1=\frac{A v_1}{\sigma_1} \quad\left(\sigma_1 \neq 0\right) . \\ \end{aligned}
?A[v1??…?vr??…vn??]=[u1????um??]
?σ1??0?0σr??0?
?Av1?=σ1?u1??u1?=σ1?Av1??(σ1?=0).?
若
σ
1
…
σ
r
≠
0
\sigma_1 \ldots \sigma_r \neq 0
σ1?…σr?=0,则有:
u
i
=
A
v
i
σ
i
,
i
=
1
,
2
?
?
,
r
.
u_i=\frac{A v_i}{\sigma_i} \quad ,i=1,2\cdots,r.
ui?=σi?Avi??,i=1,2?,r.于是我们从
V
1
=
[
v
1
,
v
2
,
?
?
,
v
r
]
V_1=[v_1,v_2,\cdots,v_r]
V1?=[v1?,v2?,?,vr?]出发,构造
U
1
=
[
u
1
,
?
?
,
u
r
]
U_1=[u_1,\cdots,u_r]
U1?=[u1?,?,ur?]如下:
u
i
=
1
λ
i
A
v
i
,
i
=
1
,
?
?
,
r
.
u_i=\frac1{\sqrt{\lambda_i}}Av_i,i=1,\cdots,r.
ui?=λi??1?Avi?,i=1,?,r.
下面验证
U
1
U_1
U1?中的列向量是否正交:
u i T u j = 1 λ i λ j v i T A T A v j = 1 λ i λ j v i T λ j v j = δ i j = { 1 , i = j 0 , i ≠ j . u_i^Tu_j=\frac1{\sqrt{\lambda_i\lambda_j}}v_i^TA^TAv_j=\frac1{\sqrt{\lambda_i\lambda_j}}v_i^T\lambda_jv_j=\delta_{ij}= \begin{cases} 1,i=j\\ 0,i\neq j. \end{cases} uiT?uj?=λi?λj??1?viT?ATAvj?=λi?λj??1?viT?λj?vj?=δij?={1,i=j0,i=j.?
这说明
[
u
1
,
?
?
,
u
r
]
[u_1,\cdots,u_r]
[u1?,?,ur?]
是
A
A
A的列空间
R
(
A
)
R(A)
R(A)的一组标准正交基.接着我们构造
U
2
U_2
U2?,补全
U
=
[
U
1
,
U
2
]
U=[U_1,U_2]
U=[U1?,U2?].我们知道
R
(
A
)
R(A)
R(A)的正交补空间为
N
(
A
T
)
N(A^T)
N(AT),设
u
r
+
1
,
?
?
,
u
m
u_{r+1},\cdots,u_m
ur+1?,?,um?为
N
(
A
T
)
N(A^T)
N(AT)的一组标准正交基.令
U
2
=
[
u
r
+
1
,
?
?
,
u
m
]
U_2=[u_{r+1},\cdots,u_m]
U2?=[ur+1?,?,um?]那么此时
U
=
[
U
1
,
U
2
]
U=[U_1,U_2]
U=[U1?,U2?]为正交矩阵,整个
U
U
U我们就都得到了!
(3)与四大子空间的关系
再来观察:
A
[
V
1
,
V
2
]
=
[
U
1
,
U
2
]
Σ
A[V_1,V_2]=[U_1,U2]\Sigma
A[V1?,V2?]=[U1?,U2]Σ
由上面的证明过程我们知道:
- V 1 V_1 V1?是 R ( A T ) R(A^T) R(AT)的一组基, V 2 V_2 V2?是 N ( A ) N(A) N(A)的一组基.
- U 1 U_1 U1?是 R ( A ) R(A) R(A)的一组基, U 2 U2 U2是 N ( A T ) N(A^T) N(AT)的一组基.
矩阵A的奇异值分解的左右奇异向量刚好是 A A A的四大基本子空间的基!
(4)推论
由 A = U Σ V T A=U\Sigma V^T A=UΣVT可推出
- A T A = V ( Σ T Σ ) V T A^TA=V(\Sigma^T\Sigma)V^T ATA=V(ΣTΣ)VT,右奇异向量为 A T A A^TA ATA的特征向量.
- A A T = U ( Σ Σ T ) U T AA^T=U(\Sigma\Sigma^T)U^T AAT=U(ΣΣT)UT,左奇异向量为 A A T AA^T AAT的特征向量.
- A A A的奇异值 σ 1 , ? ? , σ n \sigma_1,\cdots,\sigma_n σ1?,?,σn?是唯一的,但 U U U和 V V V不唯一.
- 矩阵的奇异值分解可以看作将其对应的线性变换分解为旋转变换 ( V T ) (V^T) (VT)、伸缩变换 ( Σ ) (\Sigma) (Σ)及旋转变换 ( U ) (U) (U)的组合.

四、矩阵近似
奇异值分解的一个应用是低秩矩阵估计,在F范数最小意义下,可以用秩为k(k<r)的低秩矩阵对A进行近似.
(1)低秩矩阵估计
下面首先给出紧奇异值分解和截断奇异值分解的概念:


这里我们采用 F F F范数来刻画两个矩阵 A A A和 X X X的差异: ∥ A ? X ∥ F \|A-X\|_F ∥A?X∥F?,下面我们通过定理2会知道,在 F F F范数的意义下,截断奇异值分解就是秩不超过 k k k的矩阵中对 A A A的最好的近似.
引理1
设 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n的奇异值分解为 U Σ V T U\Sigma V^T UΣVT,其中 Σ = \Sigma= Σ=diag ( σ 1 , ? ? , σ n ) ( \sigma_1, \cdots , \sigma_n) (σ1?,?,σn?) ,则:
∥ A ∥ F = ∑ i = 1 n σ i 2 \parallel A\parallel_F=\sqrt{\sum_{i=1}^n\sigma_i^2} ∥A∥F?=i=1∑n?σi2??
证明: ∥ A ∥ F = ∥ U Σ V T ∥ F = ∥ Σ ∥ F = ∑ i = 1 n σ i 2 . \|A\|_F=\|U\Sigma V^T\|_F=\|\Sigma\|_F=\sqrt{\sum_{i=1}^n\sigma_i^2}. ∥A∥F?=∥UΣVT∥F?=∥Σ∥F?=∑i=1n?σi2??.
引理2
设 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n 且 rank ? ( A ) = r \operatorname{rank}(A)=r rank(A)=r,并设 M M M为 R m × n \mathbb{R}^{m\times n} Rm×n中所有秩不超过 k k k的矩阵集合, 0 < k < r 0<k<r 0<k<r,则存在一个秩为 k k k的矩阵 X X X,使得:
∥ A ? X ∥ F = min ? S ∈ M ∥ A ? S ∥ F . \|A-X\|_F=\min_{S\in\mathcal{M}}\|A-S\|_F. ∥A?X∥F?=S∈Mmin?∥A?S∥F?.
称矩阵 X X X为矩阵 A A A在Frobenius范数意义下的最优近似.

- 上述定理说明在秩不超过 k k k的 m × n m\times n m×n矩阵集合中,存在矩阵 A A A的最优近似矩阵 X X X;
- A ′ = U Σ ′ V T A^{\prime}=U\Sigma^{\prime}V^{T} A′=UΣ′VT就是这样的最优近似矩阵.
- A A A的紧奇异值分解是在Frobenius范数意义下 A A A的无损压缩.
- A A A的秩为 k k k的截断奇异值分解是A的有损压缩,通常 k k k远小于 r r r, 因此是由低秩矩阵实现了对 A A A的压缩。
(2)矩阵的外积展开
设 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n且 其奇异值分解为 U Σ V T U\Sigma V^T UΣVT,则
A
=
U
Σ
V
T
=
[
σ
1
u
1
,
?
?
,
σ
n
u
n
]
[
v
1
T
?
v
n
T
]
=
σ
1
u
1
v
1
T
+
?
+
σ
n
u
n
v
n
T
.
\begin{aligned} A&=U\Sigma V^T\\ &=[\sigma_1u_1,\cdots,\sigma_nu_n] \left[\begin{array}{l}v_1^T\\\vdots\\v_n^T\end{array}\right]\\ &=\sigma_1u_1v_1^T+\cdots+\sigma_nu_nv_n^T. \end{aligned}
A?=UΣVT=[σ1?u1?,?,σn?un?]
?v1T??vnT??
?=σ1?u1?v1T?+?+σn?un?vnT?.?
称
A
=
σ
1
u
1
v
1
T
+
?
+
σ
n
u
n
v
n
T
A=\sigma_1u_1v_1^T+\cdots+\sigma_nu_nv_n^T
A=σ1?u1?v1T?+?+σn?un?vnT?为
A
A
A的外积展开式. 令
A
k
=
∑
i
=
1
k
σ
i
u
i
v
i
T
A_k=\sum_{i=1}^k\sigma_iu_iv_i^T
Ak?=i=1∑k?σi?ui?viT?
则
A
k
A_k
Ak?的秩为
k
k
k, 是
A
A
A的截断奇异值分解,
A
k
A_k
Ak?是秩为
k
k
k的矩阵中在F范数意义下
A
A
A的最优近似矩阵.
参考资料
- 李航. 机器学习方法. 清华大学出版社, 2022.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!