51-6 Vision Transformer ,ViT 论文精读
李沐(沐神)、朱毅讲得真的好,干货蛮多,值得认真读很多遍,甚至可以当成多模态大模型基础课程学习。
论文原文: An image is worth 16x16 words: transformers for image recognition at scale。
ViT取代了CNN,打通了CV和NLP之间的鸿沟,而且挖了一个更大的多模态的坑。ViT未来有可能真就是一个简洁、高效、通用的视觉骨干网络,而且可以完全不用任何标注信息。当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
如果说过去一年中在计算机视觉领域哪个工作的影响力最大,那应该非vision transformer莫属了,因为他挑战了自从2012年Alex提出以来,CNN卷积神经网络在计算机视觉领域里绝对统治的地位。它的结论就是说,如果在足够多的数据上去做预训练,那我们也可以不需要卷积神经网络,直接用一个从自然预言处理那边搬过来的标准的transformer也能把视觉问题解决的很好。而且,vision transformer不光是在视觉领域挖了一个大坑,因为它打破了CV、NLP在模型上的这个壁垒,所以在多模态领域也挖了一个大坑。于是,在短短的一年之内,各种基于vision transformer的工作层出不穷,公众的论文应该已经有上百篇了,有把它扩展到别的任务的,有对模型本身进行改进的,有对它进行分析的。还有对目标函数或者训练方式进行改进的,基本上是可以说开启了CV的一个新时代。那vision transformer到底效果有多好?我们可以先来看一下Paper with code这个网站,这个网站就是说如果你想知道现在某个领域或者某个数据集表现最好的那些方法有哪些,你就可以来查一下。
https://paperswithcode.com/sota
我们先来看图像分类在ImageNet这个数据集上。排名靠前的全都是基于vision transformer的。那如果我们换到目标检测这个任务,在COCO这个数据集上,可以看到排名前几的都是基于Swin transformer。Swin transformer是ICCV 21最佳论文,你可以把它想象成是一个多尺度的ViT。当然还有很多领域,语义分割、实例分割、视频医疗、遥感等,基本上可以说ViT把整个视觉领域里所有的任务都刷了个遍,但我们今天要读ViT这篇论文,也不光是因为它效果这么炸裂。还是因为它有很多跟CNN很不一样的特性。
咱们来看有篇题目叫做Intriguing Properties of vision transformers的论文,看看它的图一。

图一说了在卷积神经网络CNN上工作的不太好,但是用vision transformer都能处理很好的例子。
比如说第一个就是遮挡,那在这么严重的遮挡情况下,不光是卷积神经网络,其实就是人也很难看得出其中有一只鸟。第二个例子,就是数据分布上有所偏移,在这里就是对图片做了一次纹理去除的操作,所以说导致图片看起来非常魔幻,我也很难看出来其中到底是什么物体。第三个,就是说在鸟头的位置加了一个对抗性的patch。第四个,就是说把图片打散了以后做排列组合,卷积神经网络也是很难去判断这到底是一个什么物体的。
所有这些例子,vision transformer都能处理的很好,所以说鉴于ViT的效果这么好,而且它有这么多有趣的特性,跟卷积神经网络如此不一样,那所以我们今天就来精读一下这篇论文。我们先来看一下题目,An image is worth 16x16 words: transformers for image recognition at scale,ViT。题目是说一张图片等价于很多16*16大小的单词。那为什么是16*16,而且为什么是单词?其实它是说把这个图片看作是很多很多的patch,就假如说我们把这个图片,然后打成这种方格的形式,每一个方格的大小都是16*16,那这个图片其实就相当于是很多16*16大小的这个patch组成的一个整体,接下来第二句是transformer去做大规模的图像识别。作者团队来自Google Research,Brain Team,接下来我们看一下摘要。
Abstract摘要
transformer现在已经是NLP自然语言处理领域里的一个标准,我们知道BERT,GPT3,然后或者是T5模型,但是用transformer来做CV还是很有限。在视觉里,这个自注意力要么是跟卷积神经网络一起用, 要么把某些卷积神经网络类的卷积替换成自注意力,还是保持整体的这个结构不变。我们说的这个整体结构是说譬如有一个残差网络ResNet50,它有四个stage ,res2,res3,res4,res5,那他就说这其实这个stage是不变,只是去取代每一个stage,每一个block里的这个操作。这篇文章证明了这种对于卷积神经网络的依赖,是完全不必要的。一个纯的transformer直接作用于一系列图像块的时候,它也是可以在图像分类这个任务上表现的非常好的,尤其是当在你在大规模的数据集去做预训练,然后又迁移到中小型数据集时候,这个vision transformer能获得跟最好的卷积神经网络相媲美的结果。作者这里把ImageNet,CIFAR-100,VTAB当做中小型数据集,但其实ImageNet对于很多人来说都已经是很大的数据集了。摘要的最后一句话,还指出了另外一个好处,他说transformer需要更少的这个训练资源。你乍样一听,觉得这真的很好,正筹手上两块卡或者四块卡训练不动大模型呢,这就来了一个需要特别少的训练资源就能训练的模型,而且表现还这么好。但其实你想多了,作者这里指的少的训练资源,是指2500天TPUv3的天数。他说的少,只是跟更耗卡的那些模型去做对比的,这个怎么说,还是比较讽刺,就跟某人说,我先定一个小目标,先赚一个亿。
Introduction引言
自注意力机制的这个网络,尤其是transformer,已经是自然语言处理里的必选模型。现在比较主流的方式,先去一个大规模的数据集上去做预训练,然后再在一些特定领域的小数据集上去做微调。那其实这个就是BERT这篇paper里提出来的。接下来说,多亏了transformer的计算高效性和这个可扩展性,现在已经可以训练超过1000亿参数的模型了,比如说像GPT3。然后最后一句话,他是说随着你的这个模型和数据集的增长,我们还没有看到任何性能饱和的现象。这个就很有意思了,因为我们知道,呃,很多时候不是你一味的扩大数据集,或者说扩大你的模型就能获得更好的效果的,尤其是当扩大模型的时候,很容易碰到就是过拟合的问题,那对于transformer来说,好像目前还没有观测到这个瓶颈。
在继续往下读引言之前,我想先说一下把transformer用到视觉问题上的一些难处,我们先来回顾一下transformer。
假如说我们有一个transformer,我们输入是有一些元素。假如说是在自然语言处理,这些就是一个句子里的一个一个的单词。输出也是一些元素,这里最主要的操作就是自注意力操作。自注意力操作就是说每一个元素都要跟每个元素去做互动,而且是两两互相的,然后算得一个attention。就是算得一个自助力的图,用这个自助力图去作加权平均,然后最后得到这个输出。因为在做自注意力的时候,我们是两两相互的,就是说这个计算复杂度,是跟这个序列的长度成翻倍的。目前一般在自然语言处理,就是说现在硬件能支持的这个序列长度,一般也就是几百或者上千,比如说在BERT,也就是512的这个序列长度。我们现在换到视觉领域,我们就是想用上transformer的话,首先第一个要解决的问题就是如何把一个2D的图片变成一个1D的序列,或者说变成一个集合。最直观的方式就是说我们把每个像素点当成元素,直接把2D的图片拉直,把这个扔到transformer里,然后自己跟自己学就好了。但是,想法很美好,实现起来复杂度太高。一般来说,在视觉里面,我们训练分类任务的时候,这个图片的输入大小,大概是224*224这么大,那如果把图片里的每一个像素点都直接当成这里的元素来看待,那其实它的序列长度,就不是512了。那它的序列长度就是224*224=50176,这序列的长度变成5万。其实也就意味着相当于是BERT序列长度512像100倍,所以这个复杂度是相当可怕,然后,这还只是分类任务,它的图片大小就224*24这么大,那对于检测或者分割这些任务,现在很多模型的输入,都已经是变成600*600,或者800*800或者更大了,那这个计算复杂度就更是高不可攀。所以说我们现在回到引言第二段,说在视觉里,现在卷积神经网络还是占主导地位的,像这AlexNet或ResNet,但是transformer在NLP领域又这么火,自注意力又这么香,那我计算机视觉,就是想用一下自注意力怎么办?所以说,很多工作就是想怎么能把自注意力用到视觉里来,一些工作,就是说去把这个卷积神经网络和自制力混到一起用。另外一些工作,就是说整个把卷积神经都换掉了,就全用自注意力。这些方法,其实都在干一个事儿,就是说你不是说序列长度太长,所以导致没办法把transformer用到视觉里来嘛,那我就想办法去降低这个序列长度。我们可以不用图片当transformer的直接输入,我们把网络中间的这个特征图当做传的输入,那大家都知道,假如说我们有ResNet50,那其实在它最后一个stage res4的时候,它的feature map size,其实就只有14*14那么大。那14*14的话,你把它拉平,其实也就只有196个元素,意思就是说这个序列长度,就只有196,这个就是可以接受的范围之内了。所以他用这种方式,用特征图当做transformer输入的方式去降低这个序列长度。第二个方向,有两个例子,一个叫做stand alone attention,另外一个是Axial attention,就是一个是孤立自注意力,一个是轴注意力。对于这个孤立自注意力,它做的什么事?既然这个复杂度高是来源于用整张图,那如果我现在不用整张图,我就用一个local的一个window,就我就用一个局部的小窗口,那这个复杂度就是你可以控制,你可以通过控制这个窗口的大小来让这个计算复杂度在你可接受的范围之内。这个就有点相当于回到卷积那一套操作,因为卷积也是在一个局部的窗口里做的。对于这个轴自注意力工作,它的意思是说图片的复杂度高是因为它的序列长度,是N=H*W,它是一个2D的矩阵,那我们能不能把图片这个2D矩阵拆分成两个1D的向量?所以先在高度上做一次自注意力,然后在宽度上再去做一次自助意力,相当于把一个在2D矩阵上进行自注意力操作,变成了两个1D的顺序的操作,那这样这个计算复杂度就大幅降低了。
他们虽然理论上是非常高效的,但事实上,因为他们的这个自注意力操作都是一些比较特殊的自注意力操作,没有现在的这个硬件去加速,很难把它训练成一个大模型。截止到目前为止,像这种stand attention,或者这个Axial attention,它的模型都还没有太大,就是跟这种百亿千亿级别的大模型比,还是差的很远,因此,最后一句话就是说在大规模的图像识别上这个传统的残差网络,还是效果最好的。那介绍完之前的工作,接下来就来讲vision transformer这篇paper到底做了什么事了,所以我们可以看到,自注意力早已经在计算机视觉里有所应用,而且甚至已经有完全用自注意力去取代卷积操作的工作,所以这篇论文,他就换了个角度去讲故事。他说,他们是被transformer在NLP领域里这个可扩展性所启发。他们想做的,就是直接应用一个标准的transform直接作用于图片,尽量做少的修改。就是不做任何针对视觉任务的特定改变,看看这样的transformer能不能在视觉领域里扩展的很大很好。如果直接用transformer,那老问题又回来了,这个这么长的序列长度该怎么办?这个vision transformer 是怎么处理的?vision transformer像我们刚才讲的一样,我把一个图片打成了很多patch,每一个Patch,就是16*16。我们来看,假如说这个图片的大小是2224*2224,那刚开始我们算sequence length,是224*224=50176,那现在如果我们换成patch,就是这一个patch,相当于是一个元素,那有效的长宽又会是多少?那比如说现在这个宽度变成了224/16=14了,同样的高度也就是14,所以说这样的话,最后的这个序列长度,就变成了14*14=196。意思就是说现在这张图片,就只有196个元素.那196对于普通的transformer来说,还是可以接受的这个序列程度。然后,我们把这里的每一个patch当做一个元素,然后通过一个这个FC系列就会得到一个linear embedding,这些就会当做输入传给transformer,这个时候,你其实可以很容易的看出来,一个图片,就已经变成一个一个的这样的图片块了,然后你可以把这些的图片块,当成是像NLP里的那些单词。就一个句子有多少词,那就相当于是一个图片,现在有多少个patch,这就是他题目的意义,一个图片等价于很多16*16的单词。最后一句话,他说我们训练这个vision transformer是用的有监督的训练,为什么要突出有监督?因为对于NLP那边来说的话,transformer基本上都是用无监督的方式去训练的,要么是用language model,要么是用mask language model,总之都是无监督的训练方式。
但是对于视觉来说,大部分的基线网络还都是用这个有监督的训练方式去训练。读到这儿,我们可以看出来,这个vision transformer这篇paper,真的是把视觉当成自然语言处理的任务去做,尤其是中间的这个模型,它就是用了一个transformer encoder,跟BERT是完全一样。那如果你已经听过BERT的讲解,那其实vision transformer这篇论文对你而言没有任何技术难点。这篇论文其实就是想告诉你,用这么简洁的一套框架,transformer也能在视觉里起到很好的效果,那其实大家就会很好奇,这么简单的做法,之前难道就没有人想过这么做吗?那其实肯定是有人这么做了,那其实vision transformer这篇论文之前,相关工作里已经介绍过。
他说跟他们这篇工作最像的,其实是一篇ICLR 2020的paper。那篇论文,是从这个输入图片里去抽这个2*2的图片Patch为什么是2*2?因为那篇论文的作者,只在CIFAR-0这个数据集上去做了实验。所以说你只需要抽2*2的patch就够了,如果你抽16*16,那就太大,一旦抽好这个patch以后,然后他们就在上面做self attention。所以说你你一听,那其实这个不就是vision transform,那确实是从技术上而言,它就是vision transformer,但是,vision transform的作者告诉你说,那我们的区别在哪?就我们的工作就是证明了。如果你在大规模的数据集上去做这个预训练的话,就跟NLP那边一样,在大规模的语料库上去做预训练,那么我们就能让一个标准的transformer,就是不用在视觉上做任何的更改或者特殊的改动,就能取得比现在最好的卷积神经网络还好或者差不多的结果。同时他们还指出说之前的这篇论文,他们用的是很小的patch,是2*2的,所以他们的模型只能处理那些小的图片,而微vision transformer,是可以handle medium-resolution,也就是224*224这种的图片了。所以这篇文章的主要目的,就是来告诉你transform在vision这边能够扩展的有多好。这是在超级大数据集和超级大模型的两方加持下,Transform到底能不能取代卷积神经网络的地位?
那我们回到引言,一般引言的最后,就是把你最想说的结论或者最想表示的结果放出来,这样大家不用看完整篇论文就能知道你这篇论文的贡献到底有多大。他说,当在中型大小的数据集上,比如说ImageNet去训练的时候,如果不加比较强的约束,ViT的模型其实跟同等大小的残差网络相比,其实是要弱的,就是要弱几个点,那作者就得解释,那他为什么弱?所以论文紧接着说,这个看起来不太好的结果,其实是可以预期的。
为什么?因为transformer跟卷积神经网络相比,它缺少一些卷积神经网络有的归纳偏置。
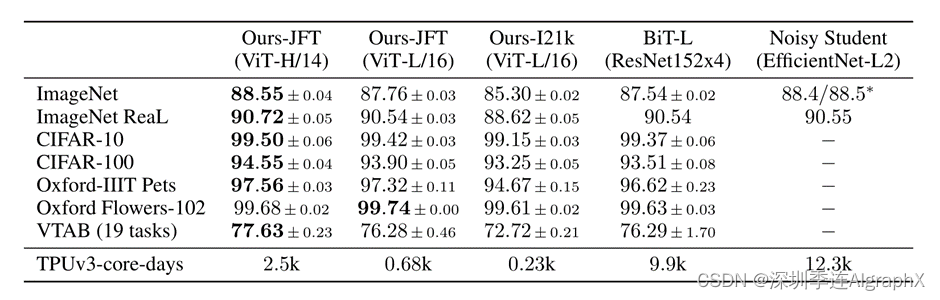
这个归纳偏置这个概念很有意思,它其实说的,就是指一种先验知识,或者一种我们提前做好的假设。比如说,对于卷积神经网络来说,我们常说的就有两个inductive bias,两个归纳偏置,一个叫做locality,因为卷积神经网络是以滑动窗口这种形式是一点一点在图片上进行卷积的,所以它假设图片上相邻的区域会有相邻的特征,那这个假设当然是非常合理的,比如说桌子和椅子,就大概率它经常就会在一起,靠的越近的东西,它的相关性就会越强。另外一个归纳偏置,叫做平移等边性。也就是我们常说的translation equivariance,它的意思,就是如果你把它写成公式的话,其实是这样的f(g(x))=g(f(x)),就是不论你先做G这个函数,还是先做F这个函数,最后的结果是不变的,这里你可以把F理解成是卷积,然后G可以理解成是平移这个操作。意思就是说无论你先做平移还是先做卷积,最后的结果是一样的,因为卷积神经网络里这个卷积核就相当于是一个模板一样,像一个template一样,那不论你这个图片同样的物体移到哪里,那只要是同样的输入进来,然后遇到了同样的卷积盒,那它的输出永远是一样的。一旦卷积神经网络有了这两个归纳偏置以后,它其实就有了很多先验信息,所以它就需要相对少的数据去学一个比较好的模型,但是对于ViT来说,他没有这些先验信息,所以说他所有的这些能力,对视觉世界的感知,全都需要从这些数据里自己学,为了验证这个假设,作者就在更大的数据集上去做了预训练。这里的这个14m,1400万图片,就是ImageNet 22k数据集,这里的300m数据集,就是Google他们自己的JFT-300m数据集。上了大数据以后,果然这效果拔群,他们立马就发现,那这个大规模的预训练,就比这个归纳偏置要好。transformer只要在有这个足够的数据去预训练的情况下,就能在下游任务上获得很好的迁移学习效果。具体来说,就是当在ImageNet 21K上去训练,或者说在这个JFT-300m命令上去训练的时候,ViT就能获得跟现在最好的残差网络相近或者说更好的结果。最后他还罗列了一些结果,比如说ImageNet 88.5,那确实相当高。以及其他一些数据集的结果,另外VTAB数据集,其实也是这个作者团队他们提出来的一个数据集,是融合了19个数据集,主要是用来检测一个模型这个稳健性好不好的,所以从侧面也可以反映出,ViT的稳健性也是相当不错。
所以读到这儿,引言算是读完了,那引言还是写的非常简洁明了的。第一段先上来说,因为transformer在NLP那边扩展的很好,越大的数据或者越大的模型,最后的performance就会一直上升,没有饱和的现象,那自然而然就会有一个问题,那如果把transformer用到视觉里来,那是不是视觉的问题也能获得大幅度的提升了。第二段就开始讲前人的工作,因为这么好的方向不可能没人做过,所以一定要讲清楚自己的工作和前人的工作的区别在哪里。他说,之前的工作,要么就是把卷积神经网络和自注意力合起来,要么就是用自注意去取代卷机神经网络,但是,从来都没有工作直接把transformer用到视觉领域里来,而且也都没有获得很好的扩展效果。所以第三段他就讲vision transformer就是用了一个标准的transformer,只需要对图片做一下预处理,就是把图片打成块,然后送到transformer就可以了,别的什么改动都不需要,这样彻底可以把一个视觉问题理解成是一个NLP问题,这样就CV和NLP这两个领域就打通了。最后两段当然是卖一下结果了,就只要在有足够多数据去训练的情况下,ViT能在很多数据集上取得很好的效果。那接下来我们先来看一下结论。
在结论里,他上来没有任何花里胡哨,直接一句话就点明了这篇paper,他到底在干什么,直接拿NLP领域里标准的transformer来做计算机视觉问题。然后他说,跟之前的那些工作,就是用自注意力的那些工作不一样的。除了在刚开始的抽图像块的时候,还有这个位置编码,用了一些图像特有的这个归纳偏置,除此之外,就再也没有引入任何图像特有的归纳偏置了。这样的好处,就是我们不需要对vision领域有什么了解,或者有什么domain knowledge。我们可以直接把这个图片理解成为是一个序列的图像框就跟一个句子里有很多单词一样。然后就可以直接拿NLP里面一个标准的transformer来做图像分类。这个简单,扩展性很好的这个策略,当你跟大规模预训练结合起来的时候工作的出奇的好。怎么个好法?就是说vision transformer在很多这个图像分类的这个benchmark上,超过了之前最好的方法,而且还相对便宜,就训练起来还相对便宜。然后接下来第二段,他又写了一些目前还没有解决的问题,或者是对未来的一个展望吧,为什么要写这一段?其实是因为vision transformer这篇论文,属于是一个挖坑的论文。挖坑,你可以是挖一个新问题的坑,或者是挖一个新数据级的坑,那这篇论文,其实是挖一个新模型的坑。就是说如何能用transformer来做CV?那所以很自然的第一个问题就是说,vision transformer不能只做分类,肯定还得去做这个分割和检测,对吧?另外两个最主流的视觉任务,就是之前另外一篇很popular的工作DETR。DETR是去年目标检测的一个力作,相当是改变了整个目标检测之前的框架,就是出框的这种方式。鉴于ViT和DETR而良好的表现,所以说他那vision transformer做视觉的其他问题,应该是没有问题的。而事实上,也正是如此,就在ViT出来短短的一个半月之后,就在2020年12月,检测这块,就出来了一个工作叫做ViT-FRCNN,就已经把ViT用到detection上了。同年12月,也有一篇SETR把transformer用到了分割里。
这里我想说的是大家的手速真的是太快了, CV圈这个卷的程度,已经不能用月来计算,已经要用天来计算了。紧接着三个月之后,Swin transformer横空出世,它把多尺度的这个设计融合到了transformer里面,所以说更加适合做视觉的问题,真正证明了transformer是能够当成一个视觉领域一个通用的骨干网络的。
另外一个未来工作方向,它就是说要去探索一下这个自监督的预训练方式。
因为在NLP领域,所有的这些大的transformer全都是用自监督的方式训练的。一会我们再看实验的时候,也可以一起讨论一下,之前NLP包括vision这边是怎么做自监督与训练的。vision transformer这篇论文,它也做了一些初始实验,他们证明了,就是说用这种自监督的训练方式,也是OK的。但是,跟这个有监督的训练比起来,还是有不小的差距的。最后,作者还说,就是说继续把这个vision transformer变得更大,有可能会带来更好的结果。那这个坑?作者团队没有等别人去填,他想着反正别人可能也没有这种计算资源,那我就来把这个坑填一填吧。所以说过了半年,同样的作者团队又出了一篇论文,叫Scaleing vision transformer。他把transformer变得很大,提出了一个ViT-G,最后把ImageNet分类的准确率刷到90以上了。
所以说这篇论文真的是一个很好的挖坑之作,它不光是给视觉挖了一个坑,就是从此以后你可以用transformer来做所有视觉的任务。它同时还挖了一个更大的坑,就是在CV和NLP能够大一统之后,那是不是多模态的任务就可以用一个transformer去解决了?而事实上,多模态那边的工作,最近一年也是井喷式的增长,由此可以看来,vision transformer这篇论文的影响力还是非常巨大的。
Related work相关工作
那我们现在回到相关工作,他先说了一下NLP领域的应用,自从2017年这个transformer提出来去做这个机器翻译以后,基本上transformer就是很多NLP任务里表现最好的方法。现在大规模的这个transformer模型,一般都是先在一个大规模语料库上去做预训练,然后再在这个目标任务上,去做一些细小的微调。这里面有两系列比较出名的工作,一个就是BERT一个就是GPT。BERT用了一个denoising的自监督的方式,其实就是完形填空,就是有一个句子,你把其中某些词划掉,你先要把这些词再predict出来。GPT用的是language modeling去做自监督,Language modeling是你已经有一个句子,然后我要去预测下一个词是什么,也就是next word prediction,预测下一个词。因为这两个任务,其实都是我们人为定的,就是说语料都在哪,句子就在哪,是完整的,我们只是人为的去划掉其中某些部分,或者把最后的词拿掉,然后去做这种完形填空,或者预测下一个词,所以这叫自监督的训练方式。接下来就开始讲自注意力在视觉里的应用,视觉里,就是说如果你想简单的使用一个自注意力用到这个图片上,那最简单的方式就是说你把每一个像素点当成是一个元素,你就去让他们两两去做自注意力就好了。但是,我们在引言里也说过,这个是平方复杂度,所以说是很难应用到真实的这个图片输入尺寸上的,那像现在分类任务的224*224图,transformer都很难处理。那更别提,就我们人眼看的比较清晰的图,一般都是1K或者4K这种画质,那序列长度都是上百万,直接在像素层面使用transformer肯定是不现实的。所以说,如果你想用transformer,那就一定得做一些这个近似。那这里他就罗列一些例子,比如说这些工作,他们是说你的复杂度高,是因为你用了整张图,所以你的序列长度长,那我现在不用整张图,我就用这个local neighborhood,我就用一个小窗口做这个自注意力,那序列长度不就大大降低了吗?那最后的这个计算复杂度不也就降低了吗?那另外一条,就是用Sparse transformer,这个顾名思义,就是我去只对一些稀疏的点做自注意力,所以只是全局注意力的一个近似。还有一系列方法,就是说把这个自注意力,用到不同大小的这种block上,或者说在极端的情况下,就是直接走轴了,也就是我们刚才讲的轴注意力,就先在横轴上去做自注意力,然后再在纵轴上走出自注意力,那这个序列长度也是大大减小的。然后他说,这些特制的自注意力结构,其实在计算机视觉上的结果都不错,就是表现是没问题,但是它需要很复杂的工程去加速,这个算子就然能在CPU或者GPU上跑的很快,或者说,训练一个大模型成为可能。然后,作者又说还有一个工作跟他们的工作很相近,就叫Image GPT。我们知道GPT是用在NLP里,是一个生成模型。Image GPT,同样也是一个生成模型,也是用无监督的方式去训练的。它跟vision transformer有什么相近的地方?是因为它也用了transformer,最后这个Image GPT能达到一个什么效果?,如果我们拿训练好模型去做一个微调,或者说就把它当成一个特征提取器,我们会发现它在ImageNet上最高这个分类准确率,也只能到72,那像这篇ViT最后的结果已经88.5了,所以说是远高于这个72的结果。但这个结果也是最近一篇论文MAE爆火的原因,因为在BEiT或者MAE这类工作之前,生成式网络在视觉领域很多任务上是没法跟判别式网络比的。判别式网络往往要比生成式网络的结果要高很多,但是MAE就做到了,就在ImageNet1K这个数据集上去做训练,就用一个生成式的模型,比之前判别式模型的效果要好。而且不光是在分类任务上,最近他们还研究e了一下迁移学习的效果,就是在目标检测上效果也非常好。最后,作者又说vision transformer其实还跟另外一系列工作是有关系的,就是用比ImageNet还大的数据集,去做这个预训练,这种使用额外数据的方式,一般能够帮助你达到特别好的效果。比如说之前2017的这篇论文,其实也就是介绍JFT-300m的这个数据集的论文,他研究了卷积神经网络的效果是怎么随着数据集的增大而提高的。还有一些论文,是研究了当你在更大的数据集上,比如说ImageNet 21K和JFT-300m去做预训练的时候,这个迁移学习的效果会怎么样?最后作者说我们也是聚焦于最后两个数据集,就是这个ImageNet 21K和JFT-300m。但是,我们并不是训练一个残差网络,我们是去训transformer。
其实这个相关工作写的非常彻底的,而且他列举了很多跟他们工作最相近的,其实写相关工作这个章节,就是要让读者知道在你的工作之前,别人做了哪些工作,你跟他们的区别在哪里,这个只要写清楚了,其实是对你非常有利的,并不会因此降低论文的这个创新性,反而会让整个文章变得更加简单易懂。
Method方法
那接下来我们就一起来读一下这个文章的第三节这个主体部分,他们说,在模型的设计上是尽可能的按照这个最原始的这个transformer里来做的,这样一个好处就是说,我们可以直接把NLP那边已经成功的transformer的架构直接拿过来用,我们就不用自己再去模改模型了,而且,因为transformer已经在NLP领域火了这么多年了,还有一些写的非常高效的一些实现,同样ViT可以直接把它拿过来用,那接下来看3.1,他说模型的一个总览图。
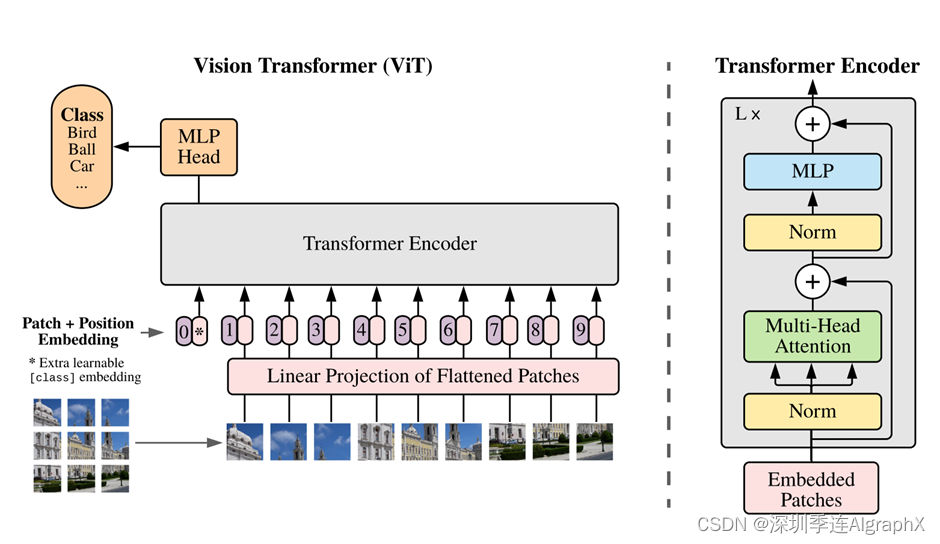
vision transformer这张图,其实画的就很好,因为我们也可以看到,当别人在讲解vision transformer这篇论文或者跟他对比的时候,都是直接把这个图一直接就复制粘贴过去了,而不是说自己为了讲解的需要,还要再费尽心思再从头再画一个图。
接下来我们先大概过一下这个整体的流程,然后我们再具体的过一遍整个网络的这个前项操作。
首先,给定一张图,先把这张图打成了这种patch,也就是说这里是把这个图打成了九宫格,然后他把这些patch变成了一个序列,每个patch会通过一个叫线性投射层的操作得到一个特征,也就是这篇论文里说的patch embedding。但我们大家都知道,这个自注意力,是所有的元素之间两两去做这个交互,所以说它本身并不存在一个顺序问题。但是对于图片来说,它是一个整体,这个九宫格是有自己的顺序的,比如说这图片就是123,一直到第九张图片,它是有顺序的,如果这个顺序颠倒了,其实就不是原来这张图片了。同样类似NLP那边,我们给这个加上了一个position,就加上一个位置编码,一旦加上这个位置编码信息以后,这个整体的token就既包含了这个图片块原本有的图像信息,又包含了这个图像块的所在位置信息。一旦我们得到这些一个一个的token,那其实接下来这个就和NLP那边是完全一样,我们直接把它给transformer encoder,那这个transformer encoder就会同样的返回给我们很多输出。那这里问题又来了,那这么多输出,我们该拿哪个输出去做最后的分类?所以说再次借鉴BERT,BERT那边,有这个叫extra learnable embedding,也就是一个特殊字符,叫CLS,就分类字符。同样的,我们在这里也加了这么一个特殊的字符,这里用星号代替,而且它也是有position embedding,它有位置信息的,它永远是零。因为所有的token都在跟所有的token做交互信息,所以他们相信,这个class embedding能够从别的这些embedding里头去学到有用的信息,从而我们只需要根据它的输出做一个最后的判断就可以。那最后这个MLP Head其实就是一个通用的分类头了,最后用交叉商函数去进行模型的训练。至于这个transformer encoder,也是一个标准的transformer encoder,这篇论文也把具体的结构列在右边了。
就是说当你有这些patches的时候,你先进来做一次layer norm,然后再做Multi-head self-attention,然后再layer norm,然后再做一个MLP,这就是一个transform block,你可以把它叠加Lx次,就得到了你的transformer encoder。所以说整体上来看,vision transformer的架构还是相当简洁,它的特殊之处就在于如何把一个图片变成这里的一系列的token。
我们接下来,可以具体按照论文中的文字,再把整个模型的前项过程走一遍。
假如说,我们有个图片,X,然后它的dimension是224*224*3,如果我们这里使用16*16的这个patch size大小,那我们就会得到多少token?n等于224*224/16*16=196,也就是14的平方,就我们一共会得到196个图像块。那每一个图像块的维度如何?其实就是16*16*3,也就是768,这3就是RGB channel。所以,我们就把原来这个图224*224*3变成了一个有196个patch,每个patch的维度是768。那接下来这个线性投射层是什么?其实这个线性投射层,就是一个全连接层。文章后面,是用大E这个符号去代表这个全连接层的。这个全链接层的维度是多少?其实这个全连接层的维度是768*768,这个768,也就是文章中一直说的那个D。当然这个D是可以变的,就是如果你的transformer变得更大了,那这个D也可以变得相应的更大。前面这个768是从图像patch算来的,是16*16*3算来的,所以这个是不变的。那经过了这个线性投射,我们就得到我们的这个patch embedding,那具体来说,就是如果X*E,那在维度上,其实就可以理解成是196*768 乘768*768的矩阵,然后这两个维度抵消掉,所以最后你得到的还是196*768。意思就是我现在有196个token,每个token向量的维度是768。
那到现在,就其实已经成功的把一个vision的问题变成了一个NLP的问题。
我的输入,就是一系列1D的token,而不再是一张2D的图了。那除了图像本身带来的这些token以外,我们之前也说过,这里面,要加一个额外的CLS token,就是一个特殊的字符。那这个特殊字符,它只有一个token嘛,它的维度也是768,这样方便你可以和后面图像的信息直接拼接起来。所以最后序列的长度就是整体进入传的这个序列长度,其实是196+1,就是197*768了。那这197,就是有196个图片对应的token和一个那个特殊字符cls token。最后,我们还要加上这些位置编码信息,那位置编码,刚才我们说,123,一直到9,其实这只是一个序号,而并不是我们真正使用的位置编码,因为我们不可能把这个123456这些数字,然后传给一个transformer去学。具体做法,是我们有一个表,这个表的每一行,其实就代表了这里面的1234这个序号,然后每一行,就是一个向量。这个向量的维度是多少?跟这边是一样的,跟这边的D是一样的,是768。这个向量也是可以学的,然后我们把这个位置信息,加到这所有的这个token里面。注意这里面是加,而不是拼接,是直接sum。所以加完位置编码信息以后,这个序列还是197*768。那到此,我们就做完了整个对图片的这个预处理。包括加上特殊的字符CLS和加上这个位置编码信息,也就是说我们对于transformer的输入这块的embedded patches,就是197*768的一个tensor。这个tensor,先过一个layer norm出来,还是197*768。
然后我们就要做这个多头自注意力了。
多头自注意力,这里就变成了三份,K,Q,V。每一个都是197*768,197*768, 197*768这样的。那这里,因为我们做的是多头自注意力,所以其实最后的这个维度,并不是768。假设说我们现在用的是vision transformer的base版本,也就是说它用了12个头,那这个维度,就变成了768/12,也就等于64的维度。
也就是说这里的K,Q,V,变成了197*64,197*64,197*64这样。
但是有12个头,12个对应的K,Q,V去做这个自注意力操作。最后,再把这些12个头的输出直接拼接起来,这样64拼接出来以后,又变成了768。所以多头自注意力出来的结果,经过拼接,到这块还是197*768。然后再过一层layer norm是197*798,然后再过一层MLP。MLP这里,会把维度相对应的放大,一般是放大4倍,所以说就是197*3072。然后再把它缩小投射回去,然后再变成197*768,就输出了这个。这就是一个transformer block的前向传播的过程,所以说进去是197*768,出来还是197*798,这个序列的长度和每个token对应的维度大小都是一样的,所以说你就可以在一个transformer block上,不停的往上叠block,想加多少加多少,那最后,有L层这个block的模型,也就是这里面这个transform encoder,其实到这里,就已经把vision transformer这整个的模型讲完。
我们再回到正文,再快速的把3.1过一遍,看有没有什么遗漏的.他说标准的transformer是需要一系列这个1D的token当做输入,但是对于2D的图片怎么办?那我们就把这个图片,打成这么多的小patch,具体有多少个patch?就是N=H*W/P^2。
这个D向量的长度,也就是我们刚才说的那个768,从头到尾这个维度是不变的。那为了和transformer这个维度匹配上,所以说我们的这个图像的patch的维度,也得是这个D,也就是768,那具体怎么做?就是用一个可以训练的linear projection,也就是一个全连层,从全连接层出来的这个东西,叫做patch embedding。然后接着说,为了最后的分类,我们借鉴了里的这个class token,一个特殊的cls token,这个token是什么?是一个可以学习的特征,它跟图像的特征有同样的维度,就都是768。那它只有一个头片,经过很多层的这个transformer block以后,我们把它这个输出当成是整transformer的模型的输出,也当做整个图片的这个特征。那一旦有了这个图像特征了,后面就好做了,因为你卷积神经网络到这块也是有一个图像的整体的特征,那我们就在后面加一个这个MLP的这个分类头就可以了。然后对于位置编码信息,,这篇文章就用的是标准的这个可以学习的1D position,也就是里用的位置编码,那当然作者也尝试了别的编码形式了,就比如说因为你是做图片嘛,所以你对空间上的位置可能更敏感,你可能需要一个2D aware,就是能处理2D信息的一个这个位置编码,那最后发现了这个结果其实都差不多,没什么区别。
其实针对这个特殊的class token,还有这个位置编码,作者们还做了详细的消融实验。
对于vision transformer来说,怎么对图片进行预处理,还有怎么对图片最后的输出进行后处理是很关键的,因为毕竟中间的这个模型就是一个标准的transformer,没什么好讲的。
所以我们现在就来看一下这些消融实验,首先我们说一下这个class token。因为在这篇论文中,我们想跟原始的这个transformer保持尽可能的一致,所以说也用了这个class token,因为这个class token,在NLP那边的分类任务也是用的。在那边,也是当做一个全局的对句子理解的一个特征。那在这里,我们就是把它当做一个图像的整体特征。那拿到这个token的输出以后,我们就在后面接一个这个MLP里面,最后用一个非线性的激活函数,去做这个分类的预测。
但是这个class token的设计,是完全从NLP那边借鉴过来的。之前在视觉领域,我们其实不是这么做的。那比如说我们现在有一个残差网络ResNet50,我们现在有这个前面那几个block,Res,2 3 4 5,对吧,那在最后这个stage出来的,是一个feature map,这个feature map,是14*14。然后在这个feature map之上,我们其实是做了一部这个GAP的操作,也就是他这里说的global average-pooling,这是一个全局的平均特征。
我们为什么不能直接在这n个输出上去做这个global average-pooling,然后得到一个最后的特征?我们为什么非得在这个前面,加一个class token,然后最后用token去做输出,然后去做分类?那其实通过实验,作者最后的结论是说,其实这两种方式都可以,就你也可以去做这个global average-pooling,然后得到一个全局的特征,然后去做分类,或者你用什么一个class token去做,那vision这篇论文所有的实验都是用class token去做的,他主要的目的,就是跟原始的这个transformer保持尽可能的一致。是想说不想让你觉得它这个效果好,有可能是因为某些trick带来的,或者是某些针对CV的改动而带来的,他就是想告诉你一个标准的transformer照样能做视觉。
那我们往下拉看这张图

其实这个绿线,就代表这个全局平均池化,就是原来vision领域里怎么做的。然后这个class token,就代表是NLP那边怎么做,就这条蓝线。那我们可以看到,其实最后,这个绿线和蓝线的效果是一样的。但是作者指出,这个绿线和蓝线用的这个学习率是不一样的,就是你得好好调参,如果你不好好调参,比如说直接把这个class token用的这个learning rate直接拿过来去做这个全局平均池化,那它效果是非常差的。只有这么多,可能大概低了五六个点吧,所以说,有的时候也不是你的idea不work,可能主要还是参没调好,炼丹技术还是要过硬。
我们再来看一下位置编码。
他这里也做了很多这个消融实验,主要的,其实就这三种,1D,2D,或者是这个relative positional embeddings的。1D其实也就是NLP那边常用的一个位置编码,也就是这篇文章从头到尾都在使用的位置编码。2D的这个位置编码,它是这个意思,就是原来你1D那边,比如说你把一个图片打成九宫格,我们之前有的是123,9,那我们现在与其用这种方式去表示那些图像块,我们用这种方式,就是
111213
212223
313233
去表示这么一个九宫格的图片,那这样是不是跟视觉问题就更贴近?因为它有了这个整体的这个structure信息,那具体是怎么做?就是说假如说原来的这种1D的这种位置编码,它的这个维度是D,那现在因为横坐标纵坐标你都得需要去表示,那对于横坐标来说,你有一个d/2的维度,那对于纵坐标来说一样,你也有d/2的维度,就是你分别有这么一个d/2的这个向量,最后你把这两个d/2的向量拼接在一起,,在一起就又得到了一个长度为D的这个向量,我们把这个向量叫做2D的位置编码。那第三种这个相对位置编码是什么意思?就是说假如我们讲还是1D的情况,那这个patch和这个的距离既可以用绝对距离来表示,又可以用它俩之间的这个相对距离来表示,那比如说它们现在之间差了七个单位距离,也就是他这里说的这个offet。这样,也可以认为是一种方式去表示各个这个图像块之间的这个位置信息,但是,这个消融实验最后的结果也是,无所谓, 就是没有任何区别。
最后这个1D的position,也可以用2D的或者相对的这种位置编码去替换,但是为了尽可能的对这个标准的transformer不做太多改动,这时候本文中vision还用了这个class token,而且还是用了这个1D的位置编码。
然后接下来就开始说这个transformer,在现在来看,transformer已经是一个非常标准的操作了,那他这里对transformer或者说这个多头自制力的解释,都没有放在正文里,直接就放在这个附录里了,就跟你看现在卷积神经网络论文也不会有人把卷积写在正文里。然后作者,用公式把整体的这个过程总结了一下。

刚开始你这个X1P,X2P,XNP,其实就是这些图像块Patch,然后一共有N个patch,所以是1231直到N。每个patch,先去跟这个linear projection,也就是那个全连接层作转换,从而得到这个patch embedding,得到这些patch embedding之后,我们在它前面拼接一个这个class,因为我们需要用它去做最后的输出。一旦得到所有的这个tokens,我们需要对这些token进行位置编码,所以说我们把这个位置编码信息加进去。这个就是对于整个传送的输入了,Z0就是这个输入。
接下来,这块就是一个循环,对于每一个传block来说,它里面都有两个操作,一个是多头自注意力,一个是MLP。然后在做这两个操作之前,我们都要先过layer norm,然后每一层出来的结果,都要再去有一个残差连接。说这个ZL’,就是每一个多头自制力出来的结果。这个ZL,就是每一个transformer block整体做完以后出来的结果。然后我们这个L层循环完了之后,我们把zl就是最后一层的那个输出的第一个位置上zl0,也就是这个class token所对应的输出,当做整体图像的一个特征,从而去做最后的这个分类任务。
那所以到这儿,对vision transformer的文字描述也结束了,所以他就补了一些分析,比如说这个归纳偏置,然后又提出了一个模型的变体,叫做这个混合模型,最后在3.2里又讲了讲,当你遇到更大尺寸的图片的时候,你该怎么去做微调。
那么先来看归纳偏置,他说vision transform比CNN而言,要少很多这种图像特有的归纳偏置。比如说在CNN里,这个locality,还有这个translation aquivariance,这是这个局部性,还有这个平移等变性,这在模型的每一层都有所体现的,这个先验知识,相当于贯穿整个模型始终。但是对于ViT来说,这个MLP这个类,是局部而且平移等变性的,但是自注意力层,绝对是全局的。这种图片2D的信息,基本ViT没怎么用,其实也就是刚开始把图片切成patch的时候,还有就加这个位置编码的时候用了,而除此之外就再也没有用任何针对视觉问题,就针对图像的这个归纳偏置。而且这个位置编码,说白了其实也是刚开始随机初始化的,并没有携带任何2D的信息,所有的关于这个图像块之间的这个距离信息,这个场景信息,都得从头学。在它这里,也就是先给后面的结果做了个铺垫,就是说我ViT没有用太多的这个归纳偏置,所以说在中小数据集上进行预训练的时候,效果不如卷积神经网络是可以理解。那讲完这个,那很自然,大家就会既然transformer这个全局建模的能力比较强,然后卷积神经网络,又比较data efficient就不用那么多的训练数据,那我们是不是可以搞一个这个混合的网络?比如说前面是卷积神经网络,后面是transformer。在它这里,也做了对应的实验,具体来说,就是原来你有一个图片,你把它打成patch,比如说打成16*16的patch,然后你得到了196个元素。然后这196个元素,去和这个全连接层去做一次操作,最后得到这个patch。那现在,我们不把图片打成块,我们就按照卷积神经网络那样去处理图片,就是一整张图进来,然后我们把它给一个CNN,比如说这个残差网络ResNet50,那它最后的那个特征图出来,是一个14*14的特征图。这个特征图,刚好你把它拉直了以后,它也是196个元素,然后你用这新得到的这196个元素,去跟这个全连接层去做操作,得到新的这种patch embedding。那其实,这里就是两种不同的对图片进行预处理的方式,一种就是直接把它打成patch,很简单,直接过全连接层。另外一种,还要再过一个CNN,得到这么196个序列长度。但是,这得到的这个序列长度,都是196,所以说后续的操作全都是一样的了,都是直接扔给一个transformer,然后最后做分类。
然后我们再来看3.2,为什么要把这个微调放在这个Section 3?
这因为之前有工作说,如果你在微调的时候,能用比较大的这个图像尺寸,就是说不是用224*224了,而是用256*256甚至更大,320*320,那你就会得到更好的结果?那vision transformer肯定也不会放弃这个刷点的机会,他也想在更大的这个尺寸上去做微调。但是,用一个预训练好的vision transform其实是不太好去调整这个输入尺寸的。他这里说,当你用更大尺寸的图片的时候,如果我们把patch size保持一样,就还用16*16,但是你图片扩大了,那很显然你这个序列长度就增长了,对吧?原来的这个序列长度,是n=224*224/16*16,假如现在换成了320的图片,就是320*320/16*16,对吧,序列长度肯定是增加。所以说transformer从理论上来说,它是可以处理任意长度的,就只要硬件允许,任意长度都可以。但是,提前预训练好的这些位置编码,有可能就没用了。因为你原来的位置编码,比如说九宫格的话,是1到9,它是有明确的这个位置信息的意义在里面。现在图片变大了,如果保持patch size不变的话,有可能得到16宫格,25宫格,patch增多了,现在位置信息,就 从1到25,而不是从1到9。这个时候位置编码该如何使用?那他这里发现,其实简单的做一个2D的插值就可以了。那在这里,他们这个操作其实就是torch官方自带的这个interpolate函数就能够完成。但是,这里的差值也不是说可以想插多长就插多长,当你从一个很短的序列想要变到一个很长的序列的时候,比如说你从256~512,甚至变到768更长的时候,直接这样一个简单的差值操作,是会让最后的效果掉点的,所以说这里的插值,其实只能说是一种临时的解决方案,它算是vision transformer在微调的时候的一个局限性。最后他说,因为用了这个图片的位置信息去做这个插值,所以说这块的这个尺寸改变,还有这个抽图像块,是vision transformer里唯一的地方,用了2D信息的这个归纳偏置。
Experiments实验
接下来我们一起来读实验部分,在这个章节主要是对比的残差网络ResNet、VIT,他们这个混合模型,这个表征学习能力。为了了解到底训练好每个模型需要多少数据,他们在不同大小的数据集上去做预训练,然后在很多的数据集上去做测试。当要考虑到预训练的这个计算代价的时候,就是预训练的时间长短的时候,ViT表现的非常好,在大多数数据值上取得最好的结果,同时需要更少的时间去训练。最后作者还做了一个小小的实验,一个自监督的实验。他说,自监督是实验的结果,还可以,虽然没有最好,但是他说这个还是比较有潜力的。事实上确实如此,时隔一年之后,最近大火的MAE就证明了自建督的方式去训练ViT,确实效果很好。
数据集使用方面,主要就是说用了这个ImageNet的数据集。那他把这个有1000个类,就是大家最普遍使用的这个1000类的ImageNet数据集,叫做ImageNet,或者在很多别的论文里,叫做ImageNet 1k。然后更大的那个集合ImageNet 21K,就是有21000个类别,而且有1400万图片的那个数据集,叫做ImageNet21K。JFT数据集,就是Google自己的数据集,这是有那个3亿的图片的数据集。下游任务,全都做的是分类,也用的都是比较popular数据集,比如说CIFAR,Oxford-IIIT这些数据集。接下来我们看一下模型的变体,它一共是3种模型,其实就是跟transformer那边对应了,就是有base,large和huge。对应的这些参数,全都逐渐的变大,比如说用了更多的block,或者用了更长的这个向量维度,或者MLP的size变大,或者说多自注意力的时候用了更多的头。接着正文里又补充了一些内容,因为它的模型,不光跟这个transformer本身有关系,它还跟你这个输入有关系,当然这个patch size大小变化的时候,比如说从16*16变大变成32*32或者变小变成8*8的时候,那这个模型的位置编码就不一样。所以patch size,也要考虑到这个模型命名里面来。于是他们模型命名的方式就是比如ViT-L/16,意思就是说,他用的是一个ViT large的模型,然后它的输入size,是16*16。接着他又说,说这个transformer的这个序列长度,其实是跟你patch size这个成反比的。因为你patch size越小,那你切成的块就越多,你patch size越大,切成的块就越小。所以当模型用了更小的patch size时候,计算起来就会更贵。也就意味着比如说你这个VIT-L/16,你要换成ViT-L/8的话,那ViT-L/8的模型就要比这个16要贵很多,因为它的序列长度增加了。各个数据集测试情况,直接看结果。
vision transformer到底需要多少数据才能训练的比较好?

? ?

那我们来看图三,这应该是整个vision transformer论文最重要的take home message。就是他最想让你知道,一张图基本就把所有的实验都快概括了。这张图的意思,就是说当你使用不同大小的数据集的时候,比如说ImageNet是1.2m,这个21K是14m,一直到最后JFT是300m,就是当你的数据集不断增大的时候,那ResNet和ViT到底在ImageNet Fine-tune的时候效果如何?它这个图上点有点多,所以不太好看,但它的主要意思是说这个灰色,代表BiT,也就是各种大小的这个ResNet。比如说这个下面,应该就是个ResNet50,上面应该就是ResNet152,就是从最小的,然后到最大的所有这么一个范围。同样,中间这应该也是这是个50,这是个152,它这里想展示,就是说在中间的这个灰色的区域,就是ResNet能达到的这个效果范围,那剩下的这些圆圈点了,就是各种大小不一的vision transformer。我们首先来看,在最小的ImageNet上做预训,ResNet和vision transformer的比较如何?vision transformer是全面,不如ResNet。ViT在中小型数据集上去做预训练的时候,它的效果是远不如参差网络的。原因就因为ViT没有用那些先验知识,没有用那些归纳偏置,所以它需要更多的数据,需要网络学的更好。那接下来我们换到这个ImageNet 21K,用中间这一档的数据集去预训练,效果如何?我们会发现,ResNet和ViT就差不多了。他们的效果,都是在这个范围里面。只有当用特别大的数据集,用3亿的图片数据集去做预训练的时候,我们可以发现vision transformer基本是全面超过了。总之这个图有两个信息,一个信息,就是说如果你想用vision transformer,那你至少得准备差不多21K这么大的数据集,如果你只有很小的数据集,那还是用卷积神经网络比较好。第二个点,就是当你有规模比这个数据集更大的时候,用vision transformer应该能给你更好的结果,它的扩展性更好一些。其实整篇论文讲的,就是这个scaling。
接下来,作者又做了图四。原因是因为在图三的时候,他要用vision transformer去跟这个ResNet比,所以他还在训练的时候,用了一些强约束,比如说用了drop out,用了weight decay,还用了label smoothing,不太好分析vision transform这个模型本身的一些特性。所以说在图四里,它做的是这个linear few-shot evaluation,这就是一旦拿到这个预训练的模型,我是直接把它当一个特征提取器,我不去fine-tune,而是拿这些特征直接来做一个logits regression就行了。同时,他选的few shot,而且没有用别的数据集,它就用的是JFT。随着预训练数据集的增大,vision transformer的稳健性就上来了,但是因为这里的提升也不是很明显,所以说作者其实在这一段的最后也写了如何用vision transformer去做这种小样本的学习,是一个非常有前途的方向。
那么接下来看图五,因为vision transform这篇论文之前说了,他的预训练比用卷积神经网络要便宜,那他这里就得做更多的实验去支持他的这个论断,因为毕竟大家对transformer的印象都是说又大又贵,很难训练。
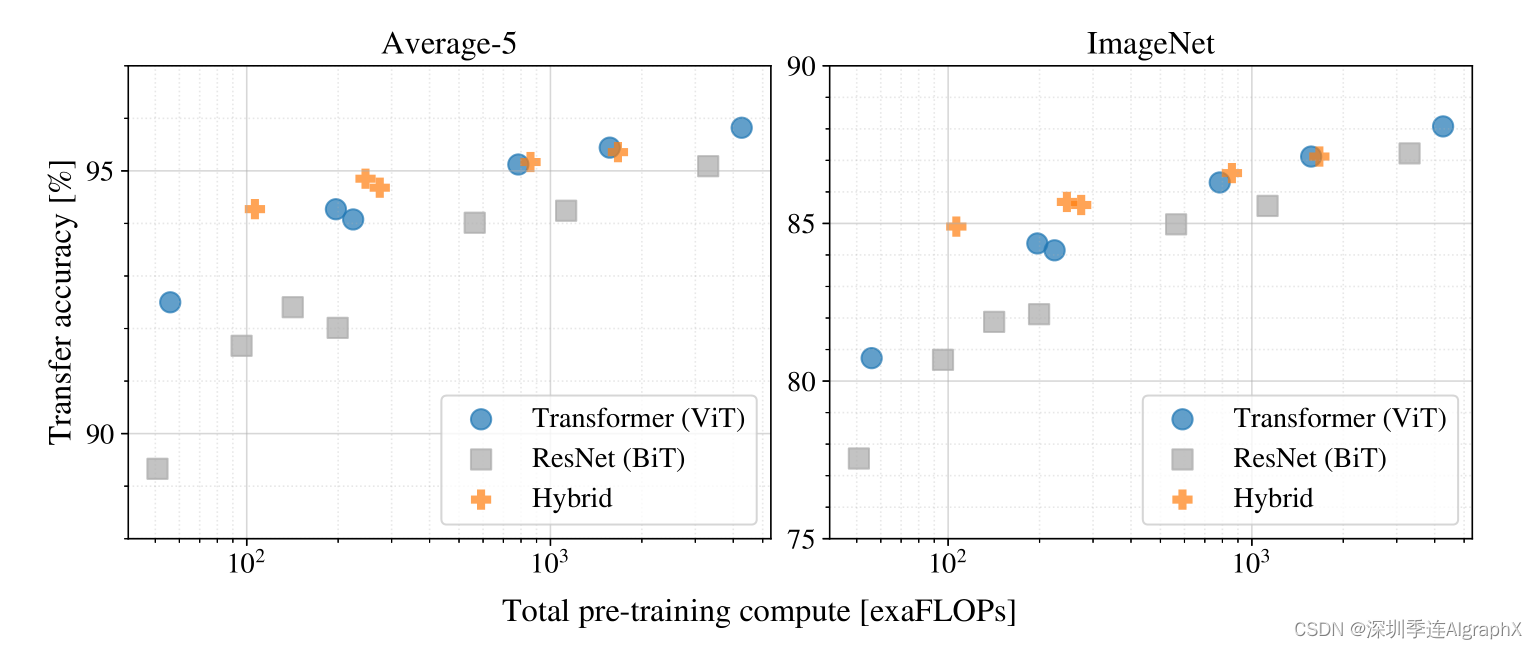
? ?我们可以看到有几个比较有意思的现象,首先第一个现象就是说,如果你拿蓝色这些圈,就ViT去跟灰色这些ResNet比,你会发现在同等的计算复杂度的情况下,ViT一般都是比较好的,这个就证明他们所说的训练一个vision transformer是要比训练一个卷积神经网络要便宜的。第二个比较有意思的点,我们可以发现,在比较小的模型上,这个混合模型的精度是非常高的,它比vision transformer和对应的ResNet都要高。这个倒也没什么惊讶的,按道理来说,这个混合模型,就应该吸收了双方的优点,就是说既不需要很多的数据去预训练,同时又能达到跟vision transformer一样的效果。但是比较好玩的就是,随着这个模型越来越大的时候,这个混合模型慢慢的就跟vision transformer差不多了,而且甚至还不如在同等计算条件下的vision transformer。这个还是比较有意思的,就为什么卷积神经网络抽出来的特征没有帮助vision transformer去更好的学习?当然这里作者也没有做过多的解释,其实怎么预处理一个图像,怎么做这个tokenization这个非常重要的点,最后有很多论文都去研究了这个问题。最后,如果我们看这个整体趋势的话,就是随着这个模型不断的增加,这个vision transformer的效果也在不停增加。它并没有一个饱和的现象,这个趋势,还是在不停的往上走的。当然如果只从这个图里来看,其实除了这个混合模型有点饱和之外,其实卷积神经网络的这个效果好像也没有饱和。
分析完这个训练成本以后,作者就继续做了一些可视化。
希望通过这个可视化,能够分析一下ViT内部的表征。类似卷积神经网络,第一个要看的就是第一层到底学到了什么样的特征,那vision transformer的第一层,就是那个linear projection layer,也就是我们说的大E,那么现在来看图七。

图七 展示了大E是如何embedding RGB value。它这里只是展示了头28个主成分,其实这个ViT的学到的跟卷积神经网络也很像,都是这种看起来像Gabor filter的这种,就是有一些颜色,然后还有一些纹理。作者说这些成分是可以当基函数的,也就是说可以去描述每一个图像块的这种底层结构。
看完了patch embedding,接下来就要看一下这个position embedding,这个位置编码是怎样工作的。再回到图七中间的这个图,这个图画的是位置编码的这个相似性。相似性越高,就是1,相似性越低就是-1,因为它做的是个cosine similarity。它的横纵坐标,就分别是对应的patch。那首先我们来看,如果是同一个patch,自己跟自己比,那这个相似性肯定是最高,就是说对于1 1这个position来说,那这个肯定黄色的点是在这儿的。那接下来,我们能观察到这个学到的位置编码,真的是可以表示一些这个距离的信息的。比如说假如说我们看这个点,那就是说离中心点越近的地方,它就会越黄,然后离中心点越远的地方,它就会越蓝,也就意味着它的相似度越低,所以它已经学到了这个距离的概念了。同时,我们还可以看到ViT学到一些行和列之间的这个规则,比如说你看这个每一个都是同行同列的,这个相似度更高,同行同列,对吧?同行同列也就意味着虽然它是一个1D的位置编码,但他已经学到了2D图像的这种距离的概念,这个作者在文中也说了,就是这也可以解释为什么他们换成2D的位置编码以后,并没有得到效果上的提升,这因为1D已经够用。
最后,作者就想看一下这个自注意力,到底有没有起作用。
因为之所以大家想用transformer,就是因为自注意力这个操作能够模拟长距离的关系。在NLP那边,就是说一个很长的句子里,开头的一个词和结尾的一个词也能互相有关联。在图像里,就是很远的两个像素点之间也能做自注意力。在这里就想看一下自注意力到底是不是像期待的一样去工作。那我们回到图七,看最右边的这张图。这张图,画的是这个ViT-L/16的这个模型,那vit large有24层,所以说这个横坐标是这个网络深度,这就是从0到24。那这些五颜六色的点,就是每一层的transformer block里面的那个多头自注意力的头。对于vit large来说,我们一共有16个头,所以其实就是说每一列,我们其实是有16个点的。它这里纵轴,画的是一个叫mean distance的东西,就是平均注意力的距离,因为自注意力是全局在做嘛,所以说每一个像素点跟每一个像素点都会有一个这个自注意力权重,那这个Dab的大小,就能反映这个模型到底能不能注意到很远的两个pixel。那这个图里的规律,还是比较明显的。我们先看头几层,有的自注意力头注意的距离还是挺近的,就是可能20个pixel。但是有的头,能到120个pixel,所以这也就证明了自注意力真的能在网络最底层,就最刚开始的时候就已经能注意到全局上的信息了。而不是像卷积神经网络一样,刚开始第一层的receptive field非常小,就只能看到附近的这些pixel。那随着网络越来越深,网络学到的这个特征,也会变得越来越high level,就是越来越具有语义信息,所以说我们也看到,大概就是网络的后半部分,它的这个自注意力距离,都都非常远了,也就意味着他已经学到这个带有语义性的概念,而不是靠临近的这个像素点去进行判断。

为了验证这一点,作者又画了另外一个图,图六。他这里面,是用网络最后一层那个output token去做的这些图,发现如果用输出的token这个自注意力折射回原来的这个输入图片,我们其实可以看到它真的学到了这些概念。比如说第一个里面这个狗,他其实就已经注意到这个狗了。作者最后一句话写,对于全局来说,因为你这个输出token是融合了所有的信息,这个全局的特征,他们就发现模型已经可以关注到那些图像区域。哪些区域?就是跟最后分类有关的区域。
在文章的最后,作者还做了一个尝试,就是如何用自监督的方式去训练一个vision transformer。
这篇论文,其实如果算上附录的话,一共有22页。那在这么多结果中,作者把别的结果都放到了附录里,而把这个自监督放到了正文里,可见它的重要性。它之所以重要是因为在NLP领域,这个transformer模型确实起到了很大的推动作用。那另外一个真正的能火起来,另外一个成功的因素,其实是大规模的自监督训练,这两个是缺一不可的。那之前我们说过NLP那边的这个自监督,无非就是完形填空或者预测下一个词,因为这篇论文整体都仿照的是BERT,所以他就想说我能不能也借鉴BERT的这个目标函数去创建一个属于vision的目标函数。BERT用了其实就是完形填空,也就叫mask language model,就是一个句子给你,然后你把一些词mask掉,然后你通过一个模型,最后再去把它预测出来。同样的道理,这篇论文就搞了一个mask的patch prediction,意思就是说我有一张图片,然后已经画成patch了,这时候我把某些patch随机抹掉,通过这个模型以后,你再把这个patch给我重建出来。这其实真的是很激动人心的,因为它不论是从模型上还是从目标函数上,CV和NLP真的就做到大一统。但是最后这个模型,比如说ViT Base,一个patch 16的模型,在ImageNet只能达到大概80的准确率。虽然,相当于从头来训练这个vision transformer,它已经提高了2个点了,但是跟最好的这种就有监督的训练方式比,就差了4个点。然后作者说,他把跟对比学习的结合当做是future work了,因为对比学习其实去年CV最火的一个topic,是所有自监督学习方法里表现最好。所以紧接着ViT,MOCO v3就出来了,还有DINO也出来,这两篇论文都是用contrastive方式去训练了一个vision transformer。
Conclusion结论
最后,我们来回顾总结一下这篇vision transformer的论文,这篇论文写的还是相当简洁明了的。那在有这么多内容和结果的情况下,做到了有轻有重,最重要的结果都放在了正文里,图和表做的也都一目了然。从内容上来说,vision transformer真的是挖了一个很大的坑,你可以从各个角度去分析它,或者提高它,或者推广它。比如说如果从任务角度来说,vision transformer只做了分类,那接下来很自然的你就可以拿它去做检测、分割和甚至别的领域的任务。那如果从改变结构的角度来说,你可以去改刚开始的tokenization,你也可以改中间的这个transformer block,因为后来就已经有人把这个self attention换成MLP,而且还是可以工作的很好。然后就在几天前,甚至有一篇论文叫Metaformer,他觉得transformer真正work的原因,是因为transformer这个架构,而不是某些特殊的算子。所以他就把这个self attention,直接换成了一个池化操作,然后他发现,用一个甚至不能学习的池化操作,也就是他提出这个pool former的这个模型,也能在视觉领域取得很好的效果,所以说在模型的改进上,也大有可为。如果从目标函数来讲,那就更是了,你可以继续走有监督,然后也可以尝试很多不同的这个自监督的训练的方式。最后更重要的,是它打通了CV和NLP之间的鸿沟,挖了一个更大的多模态的坑。接下来大家还可以用它去做视频,去做音频,甚至还可以去做一些基于touch的这种信号,就各种modality的型号都可以拿来用。在我看来,卷积、自注意力或者MLP究竟鹿死谁手,犹未可知。我很期待下一个即将出现的一个改进版的vision transformer,还有可能真的就是一个简洁、高效、通用的视觉骨干网络,而且可以完全不用任何标注信息。
https://arxiv.org/abs/2010.11929
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 交换、路由和无线基础 (版本 7.00) - 冗余网络考试
- APP加固技术及其应用
- IC工程师级别与薪资是怎样的?资深工程师一文带你了解清楚
- 神经网络常用模型总结
- MySQL45道练习题
- Spring Boot 3 集成 Thymeleaf
- 【Kubernetes】Kubernetes ConfigMap 实战指南
- Kubernetes(K8S)简介
- 禅道的安装及使用流程
- 基于Python的线上兼职平台系统的设计与实现-计算机毕业设计源码83320