论文悦读(7)——NVM文件系统之Trio(SOSP‘23)文件系统
TRIO(SOSP'23)
导读:
- TRIO是一个新型用户态PM文件系统框架,其核心是将文件系统状态分离:Core State用于保存文件系统固有状态,由KernFS控制;Auxiliary State从Core State构建用户态LibFS。TRIO将LibFS可信域缩小至单个APP从而避免对其他LibFS产生影响:每个APP对应一个LibFS,LibFS不可被应用共享。不同LibFS对同一个文件的操作需要先通过Core State验证,才能移交给请求的LibFS。
- TRIO的观察比较简单,现有的用户态PM文件系统最大挑战在于对元数据的安全性保证。然而现有的方法要么性能不足(通过一个可信对象进行请求中转,需要进程间通信),要么不够安全(允许直接操作元数据,但缺乏元数据完整性验证机制)。TRIO采用缩小可信域范围+运行前验证的方式来解决这一问题:每个LibFS需要先通过Core State的验证,然后才能获得该文件的数据+元数据访问权。如果出现Corruption,那么后续的LibFS就无法通过验证,此时通过回滚操作恢复元数据完整的Core State,从而保证元数据安全。
- TRIO这篇文章的核心insight可以从很多角度考虑,个人认为比较有意思(虽然作者只从文件系统状态分离角度阐述,让人不明觉厉)。个人的理解该架构的本质是:缩小可信域范围(对比ZoFS的LibFS可信域范围为Coffer,TRIO为APP,避免LibFS共享)及运行前验证(已有的方法采用元数据运行时验证,即请求中转,或不验证直接访问)。
1. 背景(Background)
1.1 NVM Technologis
TRIO很鸡贼,因为Optane DCPMM退出市场了,所以他们首先介绍了通用NVM技术的关键特性:
- NVM可以被CPU直接Load/Store
- 可以通过MMU等强制对NVM区域的访问权限 (理解为映射为r/w/rw等)
- NVM访问延迟低
- NVM是可字节级寻址的
为了避免与傲腾产生强关联性,TRIO列了一大堆现在的和未来的NVM,包括:battery-backed DRAM,CXL,battery-backed DRAM and flash memory。
1.2 File System Customization
Customization可以设计针对特殊负载的最优文件系统。主要优势来自于两个方面:
- Customization不需要特权 (个人理解是不需要和可信任实体耦合,简单来说,编写APP不用修改OS)。
- Customization之间不会相互影响 (通用系统在某负载表现优异,但另外的负载可能就不行,Customization可以解决这种问题)
1.3 Userspace NVM File Systems
**Thread Model:**硬件、内核、可信任用户态进程是可信的,LibFS与应用是不可信的
Goal:用户态NVM文件系统需要避免LibFS与应用对元数据的攻击
已有方法:
- 请求中转 (Mediation): 通过一个可信任进程来处理LibFS的请求,这一方面带来高额进程间通信 (IPC) 开销,一方面阻碍了Customization,因为元数据修改需要植入到可信进程内部,LibFS的设计需要可信权限。
- 直接修改 (DAX): 一些已有工作默认运行在可信环境中,于是不对元数据做检查;另一些工作通过缩小可信域来缓解元数据损坏的影响,如ZoFS,多个APP通过共享LibFS对Coffer进行访问,错误不会跨Coffer传递。由于ZoFS不做元数据检查并且APP能够共享LibFS,所以仍然会受到多种攻击,包括: Memory-based exploitation (如,通过修改LibFS的指针,在Copy时泄露敏感数据);语义攻击(移除目录项等)。
2. 观察与动机(Observation & Motivation)
现有的方法要么开销大,要么无法保证元数据安全,如何设计一个既高效又安全的用户态文件系统呢?
- 避免请求中转: 这会带来严重的IPC开销,并且阻碍Customization
- 强制可信第三方进行元数据验证: 不进行元数据验证会带来安全问题,虽然LibFS可以自行验证,不过这带来更高复杂度,且LibFS没有特权,无法进行错误恢复,因此需要一个可信第三方进行验证
- 避免LibFS状态共享 (最小化可信域): 在应用间共享LibFS会带来安全问题,因此,每个LibFS只能由一个应用使用。此外,APP间必须互斥写文件,但可以并发读文件。
3. 设计与实现(Design & Implementation)
3.1 TRIO Arhitecture
TRIO将文件系统状态分为两种:
- Core State:文件系统的本质状态,丢失后不可生成(如:文件数据、文件名、访问权限、目录结构等)
- Auxiliary State:辅助状态,可以根据Core State再生成(如:文件描述符、锁、Cache等)
TRIO由三部分组成:Per-APP LibFS、Kernel Controller以及可信Integrity Verifier。其中,Kernel Controller用于共享资源访问控制(例如:Inode、NVM页面等),Integrity Verifier用于在文件共享时验证Core State的有效性。
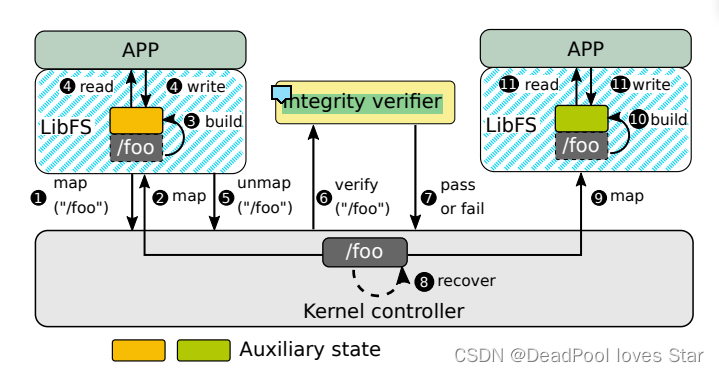
共享流程:① LibFS-A请求访问文件/foo,② Kernel Controller允许LibFS-A访问/foo的Core State,将对应页面映射到LibFS空间,③ LibFS根据/foo的Core State,构建Auxiliary State,④ 直接I/O,⑤ 在文件共享过程中,LibFS-A unmap文件,⑥ Kernel Controller向Integrity Verifier发送验证请求,⑧ 如果验证失败,Kernel Controller恢复/foo的Core State状态,⑨ 验证通过,Kernel Controller允许LibFS-B访问/foo的Core State,⑩ LibFS-B构建Auxiliary State并直接I/O
如何应对无意的BUG或者错误?
可以通过设计相应的Core State来避免这一问题,True。
3.2 ArckFS
为了显示TRIO架构的优越性,本文构建了ArckFS。整体架构如下图所示。这里值得说明的是,KVFS和FPFS是两个基于TRIO的Customization文件系统。这里可以看出,整个TRIO架构仍然类似SplitFS是一个堆叠式文件系统,LibFS通过mmap向上层提供POSIX-like I/O接口。
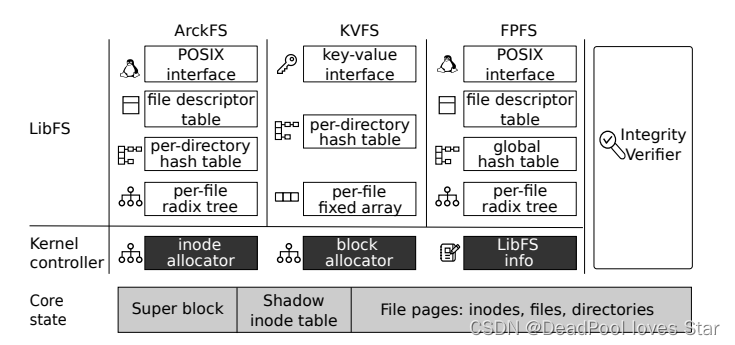
3.2.1 Core State
Core State提供了最基本的文件系统语义,提供数据索引,但不提供数据组织
- Layout:如上图所示,包括Super Block,Shadow Inode Table (用于提供元数据完整性),以及各种文件数据页。LibFS对SB有读权限,对Shadow Inode Table无权限,LibFS对文件数据页的访问权限受制于文件的权限。
- Core State of Regular File:如下图所示,文件的Core State包括Index Page + Data Page
- Core State of Directory:如下图所示,目录的Core State同样包括Index Page + Data Page,但Data Page里面装的是目录项
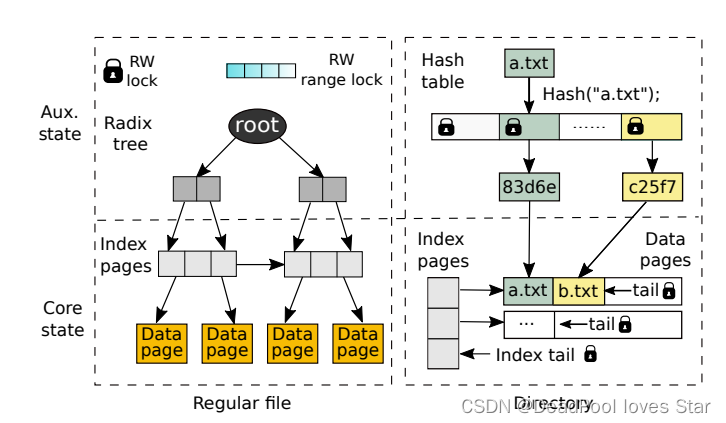
3.2.2 Auxiliary State
- Regular File:如上图所示,ArckFS (LibFS) 构建Radix Tree索引数据;通过读写锁及Range Lock来保证文件的多线程操作的Scalability。ArckFS (LibFS) 通过扫描Index Pages插入构建Radix Tree
- Directory:如上图所示,ArckFS (LibFS) 构建Hash Table索引目录,通过为Non-full Data Page维护Tail来保证高并发。ArckFS (LibFS) 扫描Index Pages + Data Pages中的目录项来构建Hash Table索引
当进行文件共享时,ArckFS LibFS的Auxiliary State会被释放。
3.2.3 Verifier
Integrity Verifier参考e2fsck进行元数据完整性检测,主要进行如下四点验证:
- Inode和目录项的字段都是有效的:① 文件类型是有效的;② 目录下没有重名文件;③ 文件名中没有/
- 文件的Inode号、索引页和数据页都是有效的:Kernel Controller会维护这些资源的分配信息,并在map/unmap文件时更新这些信息,Integrity Verifier根据这些信息进行检测。
- 目录树是完整的:Integrity Verifier会将当前的目录树与Checkpoint的目录树做对比来判断已经被删除的目录,接着Integrity Verifier需要检查该目录没有被任何LibFS引用
- 访问权限:应用可以直接修改Inode的权限从而进行攻击,Kernel Controller在Shadow Inode Table中记录文件的固有权限,并以Shadow Inode Table为参照进行文件的权限检查。对于必须修改文件权限的操作,例如,chmod和chown,LibFS请求Kernel Controller在Shadow Inode Table中进行修改。
错误修复:通过回滚到上一个Checkpoint来进行修复。
-
Checkpoint:Checkpoint发生在LibFS以写权限拿到文件映射之前,ArckFS会将文件的元数据(文件和目录的Index Pages、目录的Data Pages)都存下来。在文件共享过程中,如果检测失败,ArckFS会Notify LibFS来解决错误,如果无法解决,那么被映射的文件会变成只读。
-
Fix:出错的文件会被拷贝一份,然后回滚到上一个Checkpoint状态。
3.2.4 Crash Consistency
- Overview:ArckFS的Core State不做Crash Consistency保证,LibFS必须自行进行Recover。由于ArckFS不信任其他LibFS,因此会在完成Recovery后进行Verify。
- Consistency mode:ArckFS的LibFS保证Metadata的一致性不保证Data一致性。
3.2.5 Implmentation
- Multicore Scalability:ArckFS除了使用细粒度锁机制,还大量使用per-CPU设计
- 适配Optane DCPMM:使用和OdinFS一样的方法把I/O卸载均摊到其他NUMA节点上
3.3 KVFS & FPFS
为了说明Customization的好处,本文设计了除ArckFS外两个文件系统,分别适应不同的负载。
- KVFS:适于小文件存储,包括Email客户端等。KVFS提供了get和set两个特殊的接口,分别读取/写入特定的文件,从而避免了open/close开销,此外,将索引换成线性表,避免了树遍历开销。
- FPFS:设计full-path indexing来加速路径查询。
TRIO中Customization同样具有局限性:Core State的Customization需要特权,例如,目前ArckFS的Core State并不支持Log-structured文件系统。
4. 评估(Evaluation)
这里比较有意思的是TRIO架构带来的性能提升主要来源于直接数据/元数据访问以及OdinFS的多核拓展能力,因此,在大多数情况下ArckFS的性能应该都是最优的。TRIO的劣势在于File Sharing会带来较大的开销,包括map/unmap,verify以及rebuild auxiliary state。
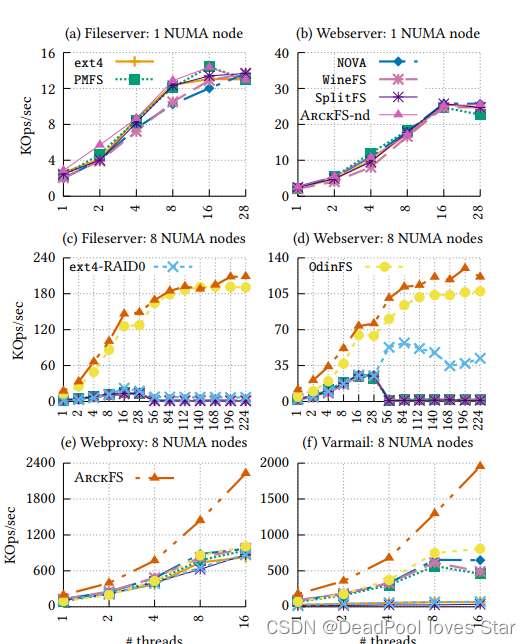
4.1 Single-Thread Performance
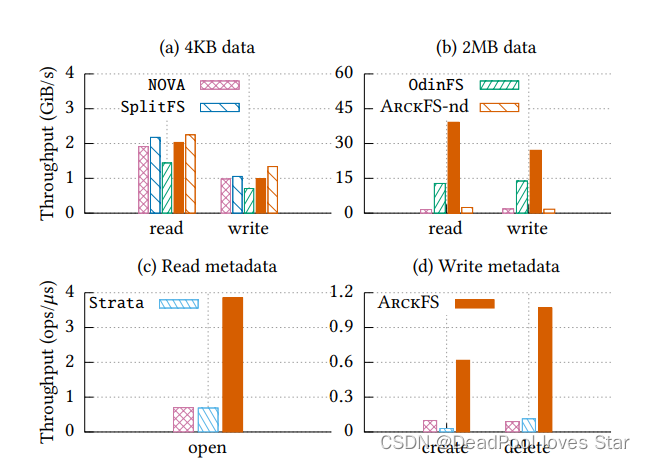
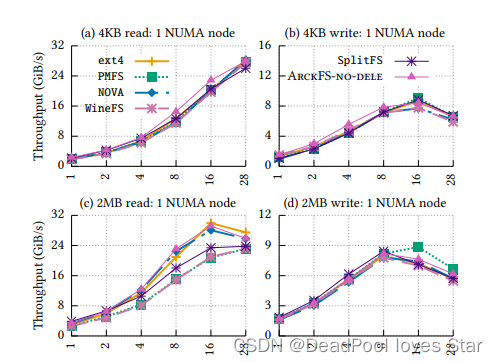
ArckFS-nd代表无delegation。
- 图(a)与(b),4K块时,ArckFS-nd更快是因为delegation需要进程间通信;2MB时,ArckFS更快是因为直接数据/元数据访问以及delegation带来的并行写入
- 图?与(d),ArckFS更快,得益于直接用户态元数据修改。
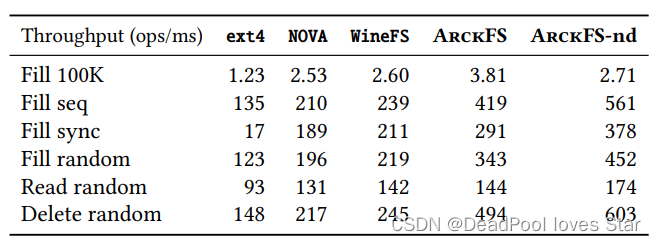
4.2 Data Operation Performance
| 
| 
|
| ------------------------------------------------------------ | ------------------------------------------------------------ |
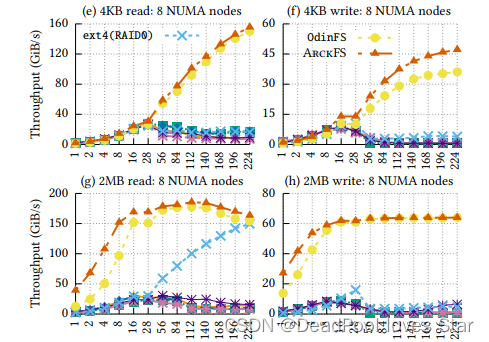
- 单个NUMA Node下,ArckFS提升比较小,主要性能提升来自于DAX。
- 多NUMA Node下,ArckFS和OdinFS远超其他的,是因为用了delegation,但是ArckFS比OdinFS更快,是因为DAX
4.3 Scalability
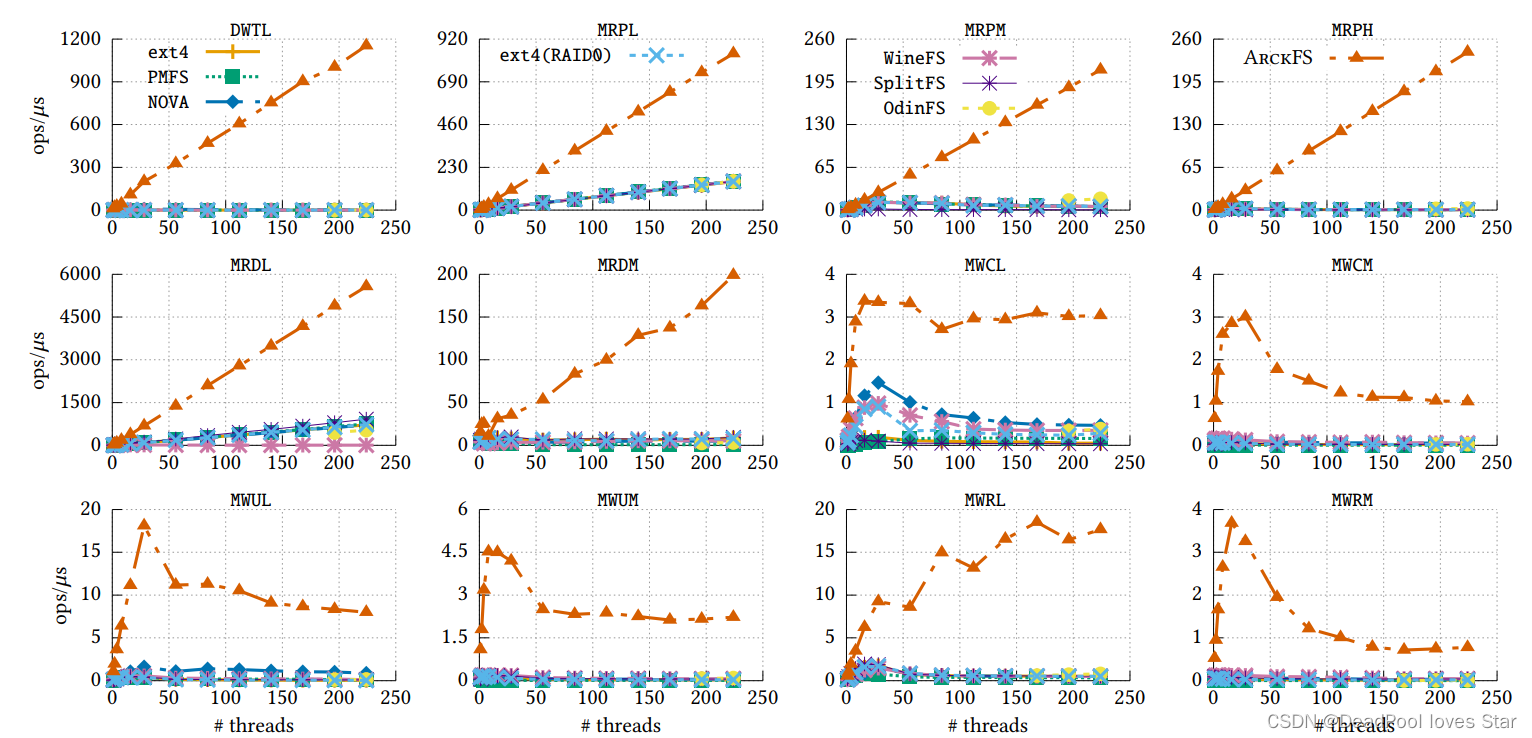
FxMark测试结果表明ArckFS的可拓展性很好,这得益于其用户态元数据直接访问和细粒度锁结构。
4.4 Sharing Cost
两个应用Sharing同一个File,下面是测试结果,可以发现ArckFS性能下降极为严重。为了解决这个问题,ArckFS使用Trust-group来避免两个应用Sharing时的元数据检查。
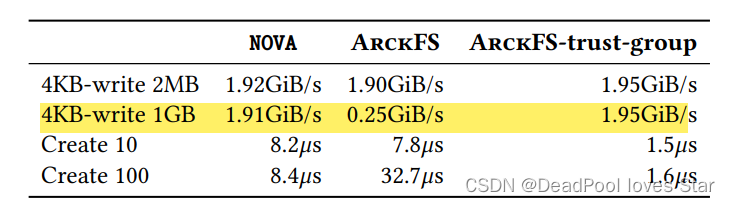
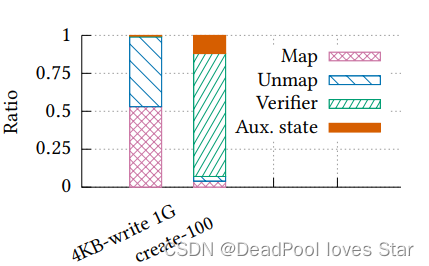
下图是性能开销分析,可以看到主要开销来源于map/unmap以及verification
4.5 Macrobenchmark and Real-world Applications
-
Filebench
Webproxy与Varmail本身就有scalability问题,因此这里只放到16线程。ArckFS性能很好。
-
LevelDB
-
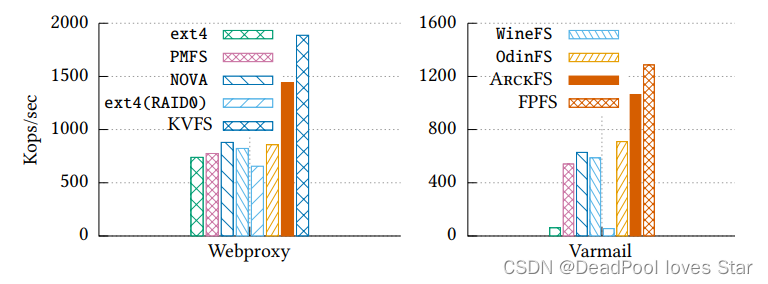
Customization
这里要研究KVFS(针对小文件优化)以及FPFS(针对目录深度查询优化)的性能优势。分别在Webproxy和Varmail负载下进行测试。这里Webproxy每个文件有512MB,严重与KVFS预设场景不符,怀疑可能是笔误。Varmail负载创建了深度为20的目录。
测试结果表明这两种Customization的LibFS都能够进一步超过ArckFS性能。
5. 总结
本文通过TRIO架构:缩小LibFS可信域至APP + 运行前验证,解决了用户态PM文件系统元数据性能与安全问题,但与之换来的是更高昂的APP间文件共享开销。
Anyway,TRIO工作看起来不是特别复杂,且其贡献仍然聚焦于NVM,不过其中蕴含的思想与哲理:对文件系统状态划分及对Customization的探讨是值得借鉴与推广的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot异步处理
- 网络基础——路由协议及ensp操作
- 基于SSM框架的餐馆点餐系统的设计论文
- 存储器管理
- 什么是javascript的同源策略
- 常见面试题之HTML
- 【Java】一文讲解Java类加载机制
- python算法问题,求两个字符串的最长公共子序列长度
- VMWARE ESXi存储多路径策略修改
- 基于springboot+redis+mybatis plus技术开发的智能导诊系统源码,可扩展至多端,自主版权,支持二次开发