Spark一:Spark介绍、技术栈与运行模式
发布时间:2024年01月02日
一、Spark简介
Spark官网 https://spark.apache.org/
1.1 Spark是什么
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。
是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎。
1.2 Spark作用
- 中间结果输出
Spark的Job中间输出结果可以保存在内存中,从而不再需要读写HDFS - MapReduce的替代方案
Spark比MapReduce平均快10倍以上的计算速度;因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
1.3 Spark特点
- 速度快
跟MapReduce对比速度更快 - 易用性
支持多种开发语言 - 通用性
- 一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
- 多种运行模式
- YARN、 Mesos、 EC2、 Kubernetes、 Standalone(独立模式)、 Local(本地模式)
二、Spark技术栈
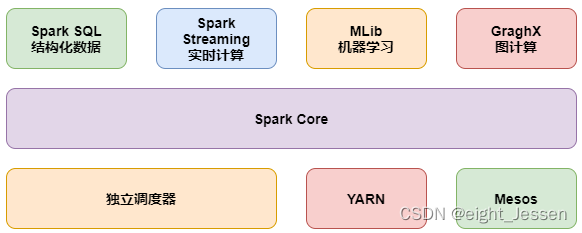
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
三、Spark运行模式
3.1 Local本地模式(单机模式)–学习测试使用
分为 local 单线程和 local-cluster 多线程
3.2 standalone 独立集群模式–学习测试使用
典型的 Mater/slave 模式。
3.3 standalone-HA 高可用模式–生产环境使用
基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有单点故障的。
3.4 on-yarn 集群模式–生产环境使用
运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
3.5 on mesos 集群模式–国内使用较少
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算.
3.6 on cloud 集群模式–中小公司未来会更多的使用云服务
文章来源:https://blog.csdn.net/eight_Jessen/article/details/135337172
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【每日一题】回旋镖的数量
- JS逆向实战案例2——某房地产token RSA加密
- C++学习笔记——C++ 新标准(C++11、C++14、C++17)引入的重要特性
- 数据库-期末考前复习-第7章-数据库设计
- RPA数据统计与展示
- 基于Java SSM框架实现咖啡馆管理系统项目【项目源码+论文说明】计算机毕业设计
- Java——黑马Java学习作业——day03运算符
- Android事件冲突原理及解决方法
- AI绘图软件,科技之旅绘画
- minio 分布式对象存储