爬虫案例—根据四大名著书名抓取并存储为文本文件
发布时间:2024年01月18日
爬虫案例—根据四大名著书名抓取并存储为文本文件
诗词名句网:https://www.shicimingju.com
目标:输入四大名著的书名,抓取名著的全部内容,包括书名,作者,年代及各章节内容
诗词名句网主页如下图:

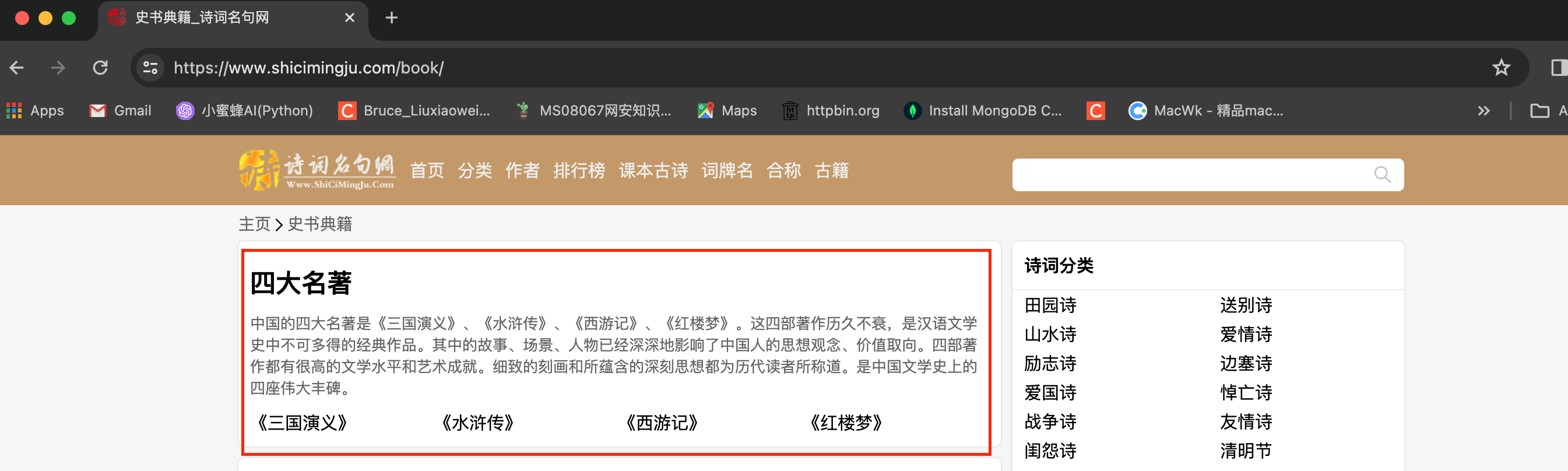
今天的案例是抓取古籍板块下的四大名著,如下图:
 案例源码如下:
案例源码如下:
import time
import requests
from bs4 import BeautifulSoup
import random
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', }
# 获取响应页面,并返回实例化soup
def get_soup(html_url):
res = requests.get(html_url, headers=headers)
res.encoding = res.apparent_encoding
html = res.content.decode()
soup = BeautifulSoup(html, 'lxml')
return soup
# 返回名著的书名及对应的网址字典
def get_book_url(page_url):
book_url_dic = {}
soup = get_soup(page_url)
div_tag = soup.find(class_="card booknark_card")
title_lst = div_tag.ul.find_all(name='li')
for title in title_lst:
book_url_dic[title.a.text.strip('《》')] = 'https://www.shicimingju.com' + title.a['href']
return book_url_dic
# 输出每一章节内容
def get_chapter_content(chapter_url):
chapter_content_lst = []
chapter_soup = get_soup(chapter_url)
div_chapter = chapter_soup.find(class_='card bookmark-list')
chapter_content = div_chapter.find_all('p')
for p_content in chapter_content:
chapter_content_lst.append(p_content.text)
time.sleep(random.randint(1, 3))
return chapter_content_lst
# 主程序
if __name__ == '__main__':
# 古籍板块链接
gj_url = 'https://www.shicimingju.com/book'
url_dic = get_book_url(gj_url)
mz_name = input('请输入四大名著名称: ')
mz_url = url_dic[mz_name]
soup = get_soup(mz_url)
abbr_tag = soup.find(class_="card bookmark-list")
book_name = abbr_tag.h1.text
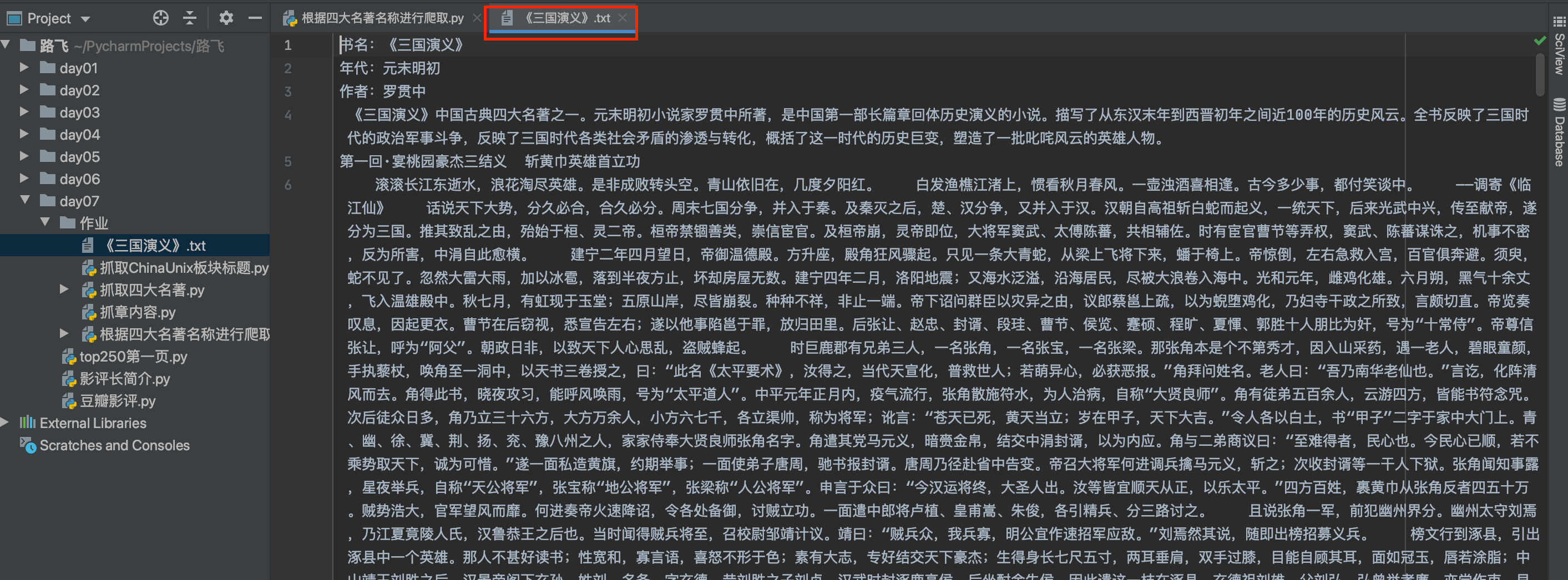
f = open(f'{book_name}.txt', 'a', encoding='utf-8')
f.write('书名:'+book_name+'\n')
print('名著名称:', book_name, end='\n')
p_lst = abbr_tag.find_all('p')
for p in p_lst:
f.write(p.text+'\n')
mulu_lst = soup.find_all(class_="book-mulu")
book_ul = mulu_lst[0].ul
book_li = book_ul.find_all(name='li')
for bl in book_li:
print('\t\t', bl.text)
chapter_url = 'https://www.shicimingju.com' + bl.a['href']
f.write(bl.text+'\n')
f.write(''.join(get_chapter_content(chapter_url))+'\n')
f.close()

文章来源:https://blog.csdn.net/weixin_41905135/article/details/135669652
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 高光谱变化检测论文解读分享之基时相差异引导网络的高光谱影像变化检测
- 3D gaussian splatting从零开始实验记录
- nb!程序员都在用的免费好用api
- 溢出以及判断溢出的两种方法(单符号位和双符号位)
- ElasticSearch应用场景以及技术选型[ES系列] - 第496篇
- 内网离线搭建之----nginx配置ssl高可用
- 华为OD机试真题-数组去重和排序-2023年OD统一考试(C卷)
- CHS_01.1.4+操作系统体系结构 一
- C语言整型详解
- 文件包含漏洞讲解