如何使用可用性管理计算基础设施的可用性?

「 全 链 路 监 控 」
服务水平目标(SLO)指定了服务可靠性的目标水平。由于SLO是做出以数据为依据的可靠性决策的关键,因此它们是SRE实践的核心。
SLO是可靠性决策的关键因素,它的存在价值是:及时报警,发现影响SLI指标的异常。并且,产生的SLO告警是SRE和研发共同关注的告警信息。它的根本目标是持续性提高产品质量,缩短故障处理时长,保证平台的可靠性。
因此,实践SRE工程的第一步是计算出正确的可用性是多少,以此定量出实际的服务可靠性水平离SLO到底有多远。
我们期望能看到每个业务线,包括基础设施的周可用性、月可用性和年可用性,并且和年度目标的差距有多少。比如:

不过,在优维监控系统中,可用性管理是以服务为单位作为可用性衡量的目标的。它会将某个特定的拨测任务作为可用性考核的基准,去计算该拨测任务下所有资源对象的可用性(最常用就是向某个接口发送HTTP请求,或者向某个端口发送ping请求),汇聚后作为服务的可用性。
这对于业务级别的可用性管理而言非常容易理解。毕竟服务是业务系统的构成单位。而对于基础设施级别的可用性衡量则可能不是那么直接,要将基础设施纳入到可用性考核当中,必须建立起基础设施和服务的关系。
「 实 践 」
我们在以下的实践中展示了如何将基础设施构成以"服务"的形式记录在CMDB,并以服务为视角去管理和监控基础设施,以达到将基础设施服务纳入到可用性管理当中。
「?服 务 分 类?」
我们将基础设施按照服务场景的不同,划分为如下几种类型:

表格中的服务,是根据基础设施类型抽象出来的服务名,我们可认为该服务代表着某一类基础设施的服务能力。
而后,我们就可以添加CMDB数据,我们以主机服务为例:

注意:此处的服务都是集群服务,因为这个服务是抽象出来的统一体,它代表着主机的总体服务能力。而主机的实际服务能力则是由各个子服务,也就是具体的主机构成的。
因此,我们需要建立集群服务和子服务的关系:

其中IP和端口非常关键,我们通常选定一组合适的套接字作为衡量主机服务是否可用的标识。在实际配置当中,我们会针对该套接字发送ping请求。
值得注意的是,可用性管理是以应用系统为统计对象,因此需要建立服务和应用系统的关系。我们需要手动建立如下关系:
应用系统 -- 应用 -- 服务
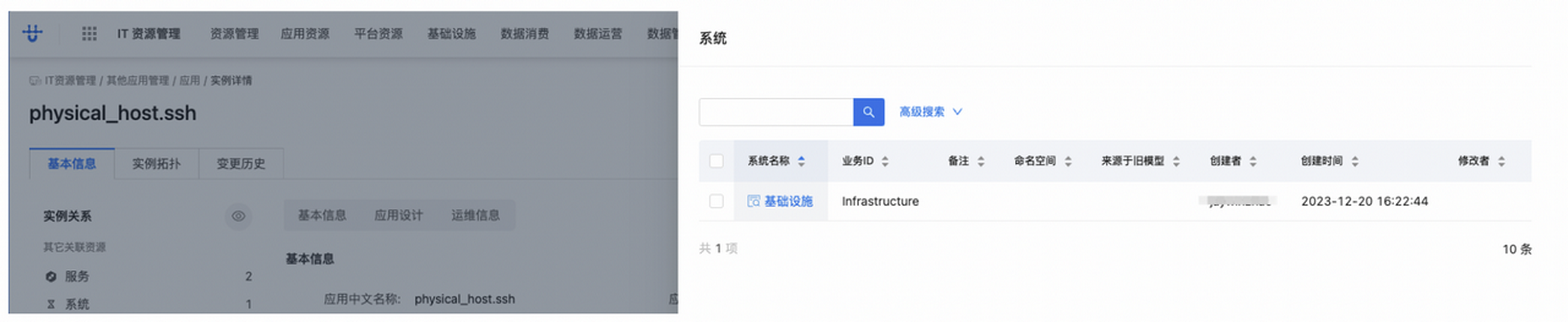
「 拨 测 任 务 配 置?」
接下来就可以建立拨测任务,我们选中建立好的集群服务,并设定拨测任务的参数,如下所示:

保存即可。
「?纳 入 可 用 性 管 理?」
最后,我们如同将纳入普通服务一样,将基础设施应用系统加入到可用性计算当中,并选择考核的服务,设置考核的目标:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FRP内网映射家用服务器至公网访问
- 安装vcpkg管理opencv的安装+MFC缺失的解决
- 删除重复字符
- CSS新手入门笔记整理:CSS3动画
- 【SpringBoot实战】基于MybatisPlus实现基本增删改查
- 最大努力通知型分布式事务
- 68、python - 第一版手写代码性能评估
- Linux基础命令[1]-ls
- 为什么要用云渲染?3d Max云渲染怎么使用?
- 【毕设选题指导】人工智能专业毕业设计选题推荐 2024