pod控制器
1、pod控制器:工作负载(wordload):用于管理pod的中间层,确保pod的资源符合预期的状态
(1)预期状态:副本数、容器的重启策略、镜像拉取策略、pod出现故障时的重启等等
2、pod控制器的类型
| replicaSet | 指定pod副本的数量 |
| 三个组件 | (1)pod的副本数 |
| (2)标签选择器,判断哪个pod归自己管理 | |
| (3)扩缩容 | |
| Deployment |
|
| statefulSet | 控制器的一种,有状态的应用
|
| Daemonset | (1)可以在所有节点部署一个的pod,没有副本数,没有扩缩容 (2)可以限制部署的节点,也是无状态的应用,服务必须是守护进程 |
| job | 工作pod控制器,执行完成即可退出,不需要重启,也不需要重建 |
| cronjod | 周期性的定时任务控制器,不需要在后台持续运行 |
3、pod与控制器之间的关系
(1)controller manager:管理控制器
(2)pod通过label——selector进行关联
4、deployment控制器
(1)strategy字段,可以不加
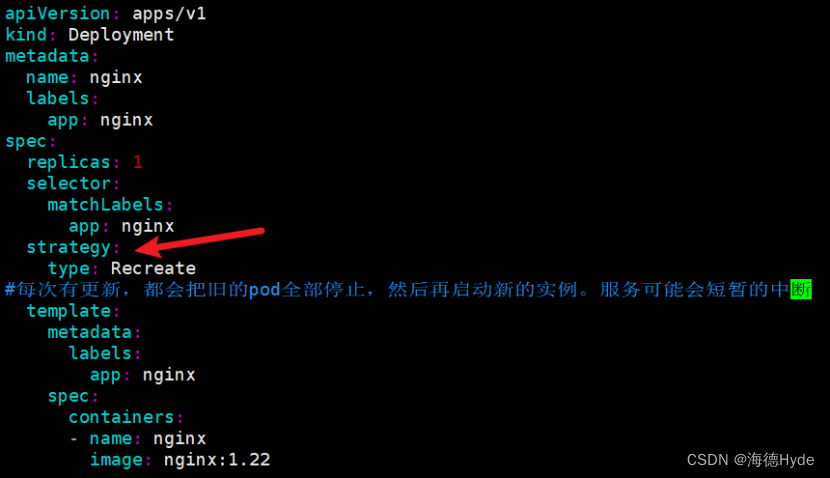

(2)strategy的默认更新策略
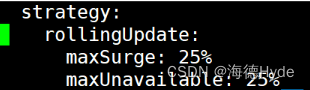
| rollingUpdate | 滚动更新 |
| maxSurge: 25% | 升级过程中,新启动的pod数量不能超过期望pod数的?25% |
| maxUnavailable: 25% | 升级过程中,新的pod启动好之后,销毁的旧的pod数量不能超过期望pod的25% |
5、statefulset控制器(有状态应用)
(1)pod的有状态和无状态
| 无状态应用: |
| pod的名称是无序的,认为所有pod都是一体的,共享存储NFS,所有deployment下的pod共享一个存储
|
| 有状态应用: |
| * pod的名称是有序的,所有的pod都是独立的,存储卷也是独立的 * 范围:0-n,删除也不会改变pod的序号,扩缩容也是有序的 |
(2)statefulset控制器
| headless service:无头服务,没有cluster IP |
| ①headless service是k8s集群中一种特殊的服务类型,不分配cluster IP给service,也不会负载均衡到后端的pod ②通过DNS提供服务的发现和访问 ③由于clusterIP是空的,k8s集群会给每个headless service当中的pod创建一个DNS记录 ④为什么要用headless service:有序、独立个体 * deployment的pod是没有名称的,随机的字符串,无序的,需要一个集中的clusterip来集中统一为pod提供网络 * statefulset是有序的,pod的名称是固定的,重建之后pod的标识符也不会变,pod的名称是唯一的标识符,系统直接通过pod名称解析ip地址,ip地址可能会变 |
| DNS记录:通过dns直接解析访问pod的ip地址 DNS记录的格式: pod-name.headless-service-name.namespace.svc.cluster.local web-0 ???????nginx-web ?????????defaults ?????本地地址(pod的ip地址) |
| 必须要有动态的PVC |
| ①有状态的副本集群都会涉及持久化存储,每个pod是独立个体,每个pod都有一个自己专用的存储点 ②statefulset在定义的时候就规定了每个pod是不能同一个存储卷,所有才需要动态PV |
| statefulset的应用场景: ①不是固定节点的应用,不是固定ip的应用 ②更新发布比较频繁 ③支持自动伸缩,当节点的资源不够,可以自动扩容 |
(3)statefulset的实例



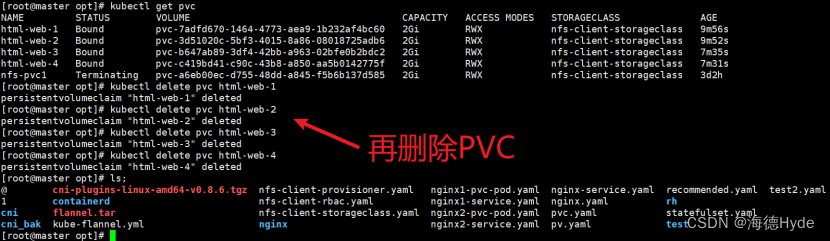
①扩缩容
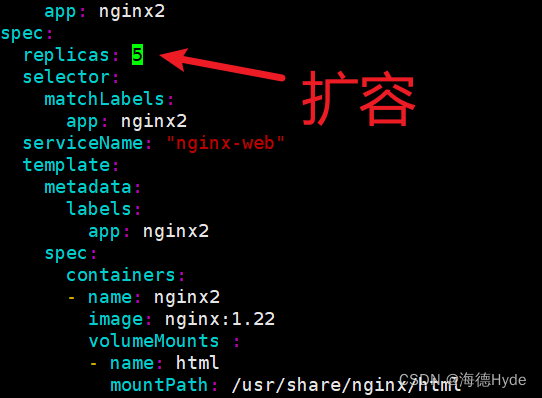
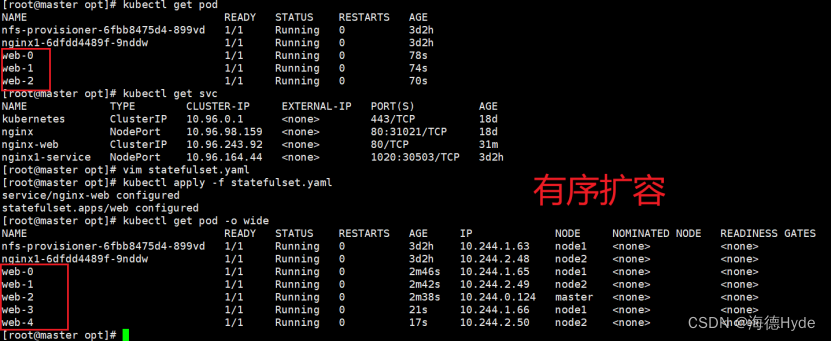
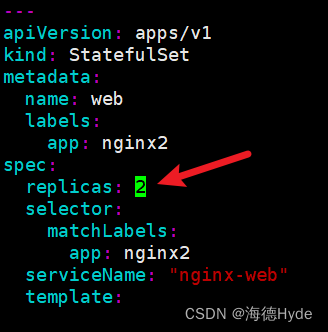
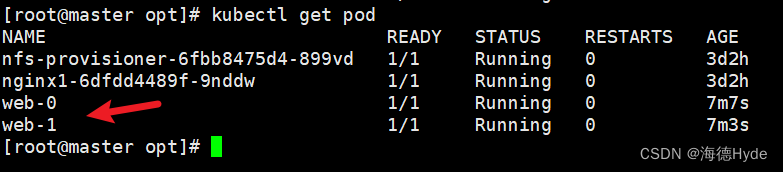
②缩容

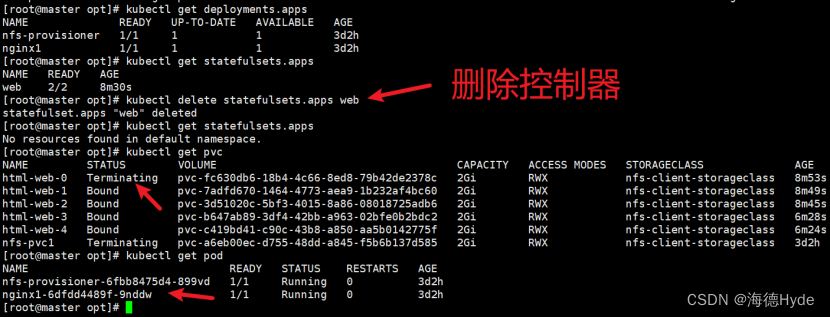
③删除控制器

6、daemonset(无状态应用)
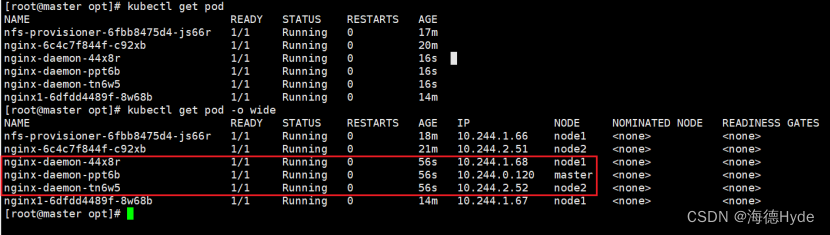
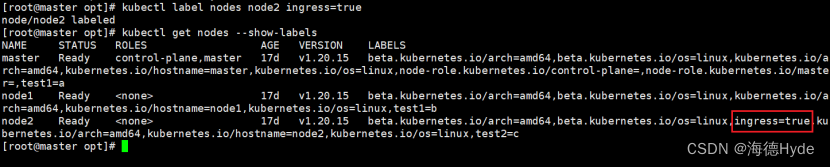
| ①默认每个节点上都运行一个pod副本,当node加入集群,也会为他新增一个pod,当node节点从集群当中移除时,pod也会被回收 ②daemonset不需要指定调度策略,默认会在每个节点部署一个pod(除非是污点) ③也可以通过指定的方式,只把daemonset部署在指定的节点上 ③没有副本数选择,不需要设置 |
(1)daemonset实例

(2)指定节点创建daemonset


(3)删除控制器daemonset
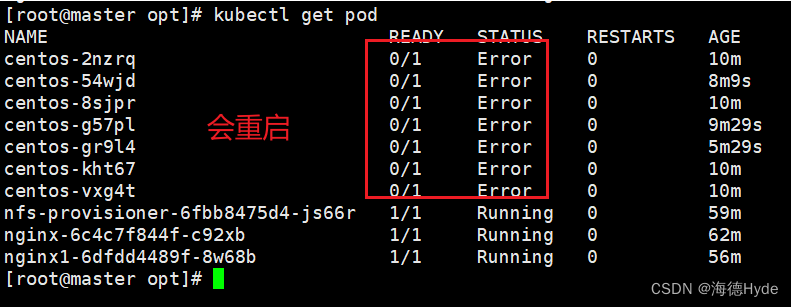
①控制器类型的资源创建方式:基于控制器创建的pod,delete只是相当于重启,要彻底删除pod,必须删除控制器

7、job控制器
| job | 普通任务 |
| cronjob | 定时任务 |
(1)job的作用:执行只需要一次性的任务(如执行脚本、数据库迁移、视频解码等业务)
(2)job的实例(普通任务)
①对k8s系统来说,既然定义了是job,只需要执行一次,或者指定次数即可,不能一直运行
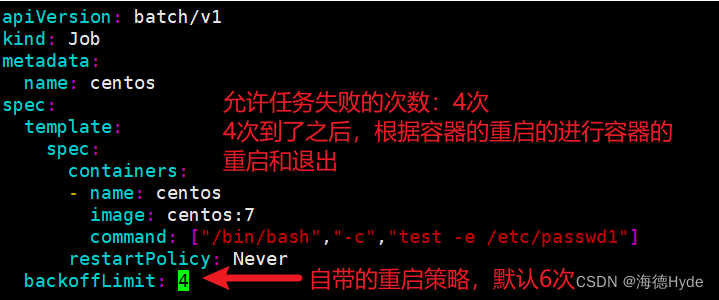
| 限制一 | 必须指定容器的重启策略:onfailure、never |
| 限制二 | 执行失败的次数也是受限的,默认是6次 (达到失败次数,才会指定指定的重启策略) |
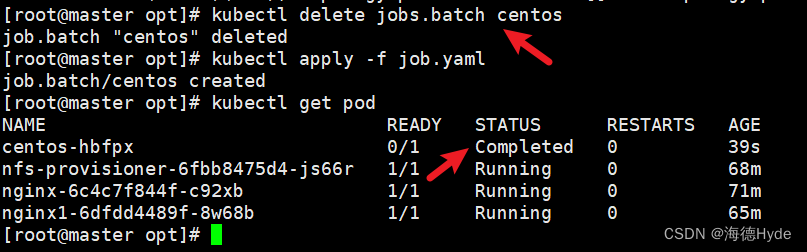
| 更新yaml文件,要先删除任务,再更新,不能动态更新: kubectl delete jobs.batch centos kubectl apply -f job.yaml | |
| 容器化部署,部署过数据库吗? ——最大的问题:不安全,数据库这样的核心资产不会容器化部署 前端会容器化部署吗? ——nginx,可以容器化部署 | |

④重启策略never

8、cronjob:周期性任务、定时执行
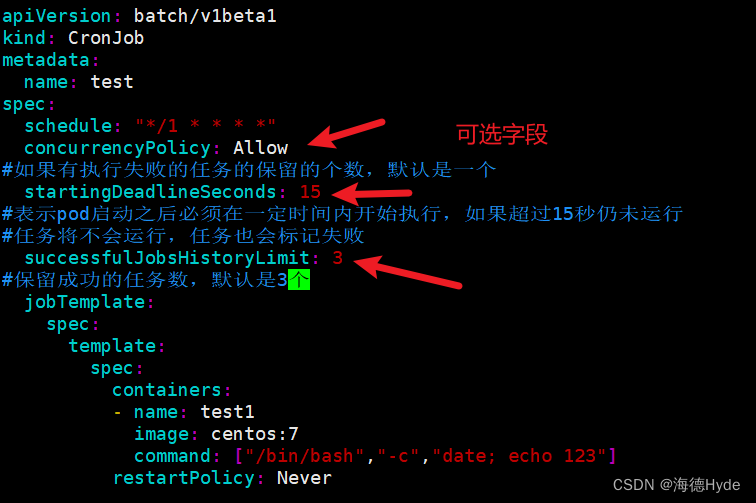
(1)和Linux的crontab语法一样(分时日月周)
(2)应用场景:定时备份、通知作用(定时检测,结合探针一起)
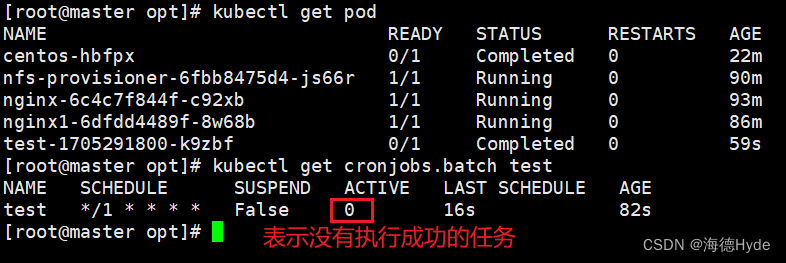
(3)实例



9、总结
(1)五个都是控制器创建的pod,都是依赖于控制器
(2)deployment:无状态应用,最好用的、也是最多的
(3)statefulset:有状态应用,有序的、独立的pod
(4)daemonset:无状态应用,不能定义副本数,每个节点都运行一个pod,也可以指定节点
(5)job:执行一次性的任务,必须要有重启策略,同时默认失败次数是6次,只有失败次数达到,重启策略才会生效
(6)cronjob:定时任务,通知、备份、探针
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- k8s的图形化工具---rancher
- AI数字人:定制个性化、低成本、可控性的品牌形象
- MSPM0L1306例程学习-UART部分(3)
- Linux xxd命令分析视频文件Box教程(box分析box、视频box、分析atom分析)(xdd指令)
- 超声波清洗机能洗干净吗?四款热门超声波清洗机清洁力实测!
- 提升Win11开始菜单体验,推荐使用StartAllBack增强工具
- 云服务器3M固定带宽速度快吗?够用吗
- ES6 面试题 | 02.精选 ES6 面试题
- ssm/php/node/python智慧社区人员管理系统
- 【Java定时任务】SpringBoot+@Schedule注解