使用主题模型和古老的人类推理进行无监督文本分类
一、说明
????????我在日常工作中不断遇到的一项挑战是在无法访问黄金标准标签的情况下标记文本数据。这绝不是一项微不足道的任务,在本文中,我将向您展示一种相对准确地完成此任务的方法,同时保持管道的可解释性和易于调整。
????????一些读者可能已经开始考虑使用基于变压器的零样本模型来完成此任务(或LLM),但在这里我将提出几个原因来说明为什么这可能会出现问题:
????????——零样本学习是一个黑匣子。理解提示/类标签选择的含义相当困难,而且您很少对所有看似随意的选择会影响什么有很好的直觉。
????????— Transformer 和 LLM 速度慢且成本高。使用 OpenAI 的 API 需要花费大量金钱,而且由于速度相当慢而可能不切实际。您当然可以自行托管一个较小的变压器模型,但如果您希望事情变得敏捷且响应迅速(这通常是生产中的要求),它仍然需要大量计算资源。
????????在这种情况下,我想说主题模型是一个非常合理的折衷方案。它们可能不如零样本变压器模型那么智能,并且您将必须做更多的体力劳动才能在实践中使用它们,但它们可以让您对过程进行更细粒度的控制,并给出更可解释的结果,更不用说性能优势了。
二、工作流程
????????在本文中,我将引导您完成创建机器学习管道的工作流程,以使用主题模型和良好的旧冷硬算法规则来标记小说文本。
2.1 数据
????????为了证明我的观点,我将做一些作弊,我将使用带标签的数据集来证明我提出的方法的有效性。不过,我只会使用标签进行评估,创建管道的整个过程将基于无监督学习和我们自己的人类直觉。该数据集有 20 个新闻组,您可以使用 scikit-learn 轻松加载。
pip install scikit-learnfrom sklearn.datasets import fetch_20newsgroups
import numpy as np
newsgroups = fetch_20newsgroups(subset="all")
corpus = newsgroups.data
# Sklearn gives the labels back as integers, we have to map them back to
# the actual textual label.
group_labels = [newsgroups.target_names[label] for label in newsgroups.target]
print(np.unique(group_labels))
------------------------------------------------------------------
array(['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware',
'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles',
'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt',
'sci.electronics', 'sci.med', 'sci.space',
'soc.religion.christian', 'talk.politics.guns',
'talk.politics.mideast', 'talk.politics.misc',
'talk.religion.misc'], dtype='<U24')假设我想根据文本是否与空间相关来标记文本,以便我们可以将无监督分类性能与实际标签进行比较。我什至会将数据分成训练集和测试集,这样我们就可以确保我们不会获知模型正在测试的信息(又名主题模型不会在测试中进行训练)放)。
from sklearn.model_selection import train_test_split
is_about_space = np.array(group_labels) == "sci.space"
X_train, X_test, y_train, y_test = train_test_split(corpus, is_about_space)>2.2 无监督模型
????????我们可以使用topicwizard创建易于使用的主题管道,然后解释主题。
pip install topicwizard????????在 topicwizard 中创建主题管道被认为是将矢量化器和分解模型链接在一起。
????????作为矢量化器,我们将使用 scikit-learn 内置的 CountVectorizer 并设置一些看起来合理的默认频率截止值,并将过滤英语停用词。
????????我们将使用非负矩阵分解作为我们的主题模型,因为它非常快(训练和推理)并且通常工作得相当好。我将确定 30 个主题,这是一个完全任意的数字。
from sklearn.decomposition import NMF
from sklearn.feature_extraction.text import CountVectorizer
from topicwizard.pipeline import make_topic_pipeline
# Setting up topic modelling pipeline
vectorizer = CountVectorizer(max_df=0.5, min_df=10, stop_words="english")
# NMF topic model with 20 topics
nmf = NMF(n_components=30)
topic_pipeline = make_topic_pipeline(vectorizer, nmf)
topic_pipeline.fit(X_train)2.3 模型解读
????????topicwizard 附带了许多内置的可视化来解释主题模型。现在我们主要感兴趣的是哪些主题可能包含大部分与空间相关的单词。
????????为此,我们将使用 topicwizard 的图形 API。首先,我们通过创建一组条形图来查看与每个主题最相关的单词。
from topicwizard.figures import topic_barcharts
topic_barcharts(X_train, pipeline=topic_pipeline, top_n=5)
不幸的是,其中大部分都是垃圾,我们可能应该更好地清理数据集,但23_satellite_space_launch_nasa看起来相当有前途。
让我们看一下主题模型中的单词映射,以了解它们彼此之间的位置关系。
from topicwizard.figures import word_map
word_map(X_train, pipeline=topic_pipeline, top_n=5)
我们可以看到,有一组单词非常空旷,而且它们的位置也与某些与技术相关的单词非常接近。

我们还可以检查“space”和“astro”这两个词属于哪些主题,以及它们最接近的 20 个关联。我们只会显示前 8 个主题。
from topicwizard.figures import word_association_barchart
fig = word_association_barchart(
["space", "astro"],
corpus=X_train,
pipeline=topic_pipeline,
n_association=20,
top_n=8
)
????????我们可以看到,到目前为止,最主要的主题是我们已经确定的主题,从现在开始,我将在我们的分析中只关注这一主题。
????????让我们转换我们的训练语料库并查看该主题的重要性分布,以便我们可以选择合理的阈值。
首先,我将主题模型的输出设置为数据框,然后我们可以通过绘图直方图看到分布。
import plotly.express as px
topic_pipeline.set_output(transform="pandas")
topic_df = topic_pipeline.transform(X_train)
px.histogram(topic_df["23_satellite_space_launch_nasa"])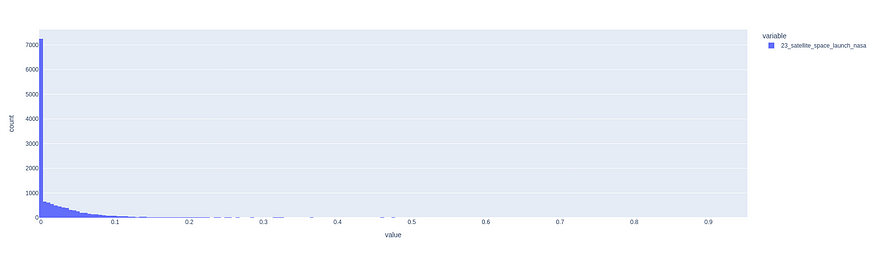
我们可以看到绝大多数文本都在0.1以下。我说我们尝试将阈值设置为 0.05,然后查看从中得到的随机文本样本。
topic_df["content"] = X_train
sample = topic_df[topic_df["23_satellite_space_launch_nasa"] > 0.05].content.sample(10)
for text in sample:
print(text[:200])From: CPKJP@vm.cc.latech.edu (Kevin Parker)
Subject: Insurance Rates on Performance Cars SUMMARY
Organization: Louisiana Tech University
Lines: 244
NNTP-Posting-Host: vm.cc.latech.edu
X-Newsreader: NN
From: pjs@euclid.JPL.NASA.GOV (Peter J. Scott)
Subject: Re: Did Microsoft buy Xhibition??
Organization: Jet Propulsion Laboratory, NASA/Caltech
Lines: 8
Distribution: world
Reply-To: pjs@euclid.jpl.na
From: ml@chiron.astro.uu.se (Mats Lindgren)
Subject: Re: Comet in Temporary Orbit Around Jupiter?
Organization: Uppsala University
Lines: 14
Distribution: world
NNTP-Posting-Host: chiron.astro.uu.se
From: mike@gordian.com (Michael A. Thomas)
Subject: Re: The Role of the National News Media in Inflaming Passions
Organization: Gordian; Costa Mesa, CA
Distribution: ca
Lines: 13
In article <1qjtmjIN
From: leech@cs.unc.edu (Jon Leech)
Subject: Space FAQ 04/15 - Calculations
Supersedes: <math_730956451@cs.unc.edu>
Organization: University of North Carolina, Chapel Hill
Lines: 334
Distribution: worl
From: wls@calvin.usc.edu (Bill Scheding)
Subject: Re: "Full page" PB screen
Organization: University of Southern California, Los Angeles, CA
Lines: 14
Distribution: world
NNTP-Posting-Host: calvin.usc
From: ghelf@violet.berkeley.edu (;;;;RD48)
Subject: Re: Soyuz and Shuttle Comparisons
Organization: University of California, Berkeley
Lines: 11
NNTP-Posting-Host: violet.berkeley.edu
Are you guys ta
From: gsh7w@fermi.clas.Virginia.EDU (Greg Hennessy)
Subject: Re: Keeping Spacecraft on after Funding Cuts.
Organization: University of Virginia
Lines: 13
In article <1r6aqr$dnv@access.digex.net> prb@
From: oeth6050@iscsvax.uni.edu
Subject: ****COMIC BOOK SALE****
Organization: University of Northern Iowa
Lines: 36
Hello,
my name is John and I have the following comic books for sale - plea
From: shafer@rigel.dfrf.nasa.gov (Mary Shafer)
Subject: Re: Inner Ear Problems from Too Much Flying?
Article-I.D.: rigel.SHAFER.93Apr6095951
Organization: NASA Dryden, Edwards, Cal.
Lines: 33
In-Reply
Hmm some of these texts do not seem to have much to do with space, let’s set a higher threshold.
topic_df["content"] = X_train
sample = topic_df[topic_df["23_satellite_space_launch_nasa"] > 0.15].content.sample(10)
for text in sample:
print(text[:200])嗯,其中一些文本似乎与空间没有太大关系,让我们设置一个更高的阈值。
topic_df["content"] = X_train
sample = topic_df[topic_df["23_satellite_space_launch_nasa"] > 0.15].content.sample(10)
for text in sample:
print(text[:200])rom: gene@theporch.raider.net (Gene Wright)
Subject: NASA Special Publications for Voyager Mission?
Organization: The MacInteresteds of Nashville, Tn.
Lines: 12
I have two books, both NASA Special P
From: 18084TM@msu.edu (Tom)
Subject: Billsats
X-Added: Forwarded by Space Digest
Organization: [via International Space University]
Original-Sender: isu@VACATION.VENARI.CS.CMU.EDU
Distribution: sci
Li
From: pww@spacsun.rice.edu (Peter Walker)
Subject: Re: The Universe and Black Holes, was Re: 2000 years.....
Organization: I didn't do it, nobody saw me, you can't prove a thing.
Lines: 28
In article
From: da709@cleveland.Freenet.Edu (Stephen Amadei)
Subject: Project Help
Organization: Case Western Reserve University, Cleveland, Ohio (USA)
Lines: 17
NNTP-Posting-Host: hela.ins.cwru.edu
Hello,
From: dbm0000@tm0006.lerc.nasa.gov (David B. Mckissock)
Subject: Washington Post Article on SSF Redesign
News-Software: VAX/VMS VNEWS 1.41
Nntp-Posting-Host: tm0006.lerc.nasa.gov
Organization: NAS
From: u920496@daimi.aau.dk (Hans Erik Martino Hansen)
Subject: Commercials on the Moon
Organization: DAIMI: Computer Science Department, Aarhus University, Denmark
Lines: 16
I have often thought abou
From: wb8foz@skybridge.SCL.CWRU.Edu (David Lesher)
Subject: Re: No. Re: Space Marketing would be wonderfull.
Organization: NRK Clinic for habitual NetNews abusers - Beltway Annex
Lines: 11
Reply-To: w
From: 18084TM@msu.edu (Tom)
Subject: Solid state vs. tube/analog
X-Added: Forwarded by Space Digest
Organization: [via International Space University]
Original-Sender: isu@VACATION.VENARI.CS.CMU.EDU
D
From: pgf@srl03.cacs.usl.edu (Phil G. Fraering)
Subject: Re: Gamma Ray Bursters. positional stuff.
Organization: Univ. of Southwestern Louisiana
Lines: 24
belgarath@vax1.mankato.msus.edu writes:
>
From: rnichols@cbnewsg.cb.att.com (robert.k.nichols)
Subject: Re: Permanaent Swap File with DOS 6.0 dbldisk
Summary: PageOverCommit=factor
Organization: AT&T
Lines: 50
In article <93059@hydra.gatech.这些似乎确实与空间相关,所以让我们保留 0.15 作为阈值。
2.4 分类管道
????????现在我们已经有了如何查看哪些文本与空间相关的规则,我们应该将这些知识合并到机器学习管道中,以便我们可以在未来的工作或生产中轻松使用。
????????为此,我们将使用令人惊叹的人类学习库,您可以在其中创建基于规则的组件,甚至可以绘制东西(这真的很棒)。
????????为此,我们必须冻结主题模型,以便在管道上调用 fit() 时不会对其进行训练
pip install human-learnfrom hulearn.classification import FunctionClassifier
from sklearn.pipeline import make_pipeline
# Creating rule for classifying something as a space document
def space_rule(df, threshold=0.15):
return df["23_satellite_space_launch_nasa"] > threshold
# Freezing topic pipeline
topic_pipeline.freeze = True
classifier = FunctionClassifier(space_rule)
cls_pipeline = make_pipeline(topic_pipeline, classifier).fit(X_train)????????我们现在有了一个与空间相关的文本的分类器,不是很漂亮吗?请记住,我们甚至还没有触及标签,只是使用了主题模型和我们自己的人类直觉。
三、评估
????????为了检查这是否确实是一种有效的方法,让我们根据测试数据评估我们的分类管道。
from sklearn.metrics import classification_report
y_pred = cls_pipeline.predict(X_test)
print(classification_report(y_test, y_pred)) precision recall f1-score support
False 0.98 0.98 0.98 4475
True 0.65 0.70 0.68 237
accuracy 0.97 4712
macro avg 0.82 0.84 0.83 4712
weighted avg 0.97 0.97 0.97 4712????????考虑到我们对标签的查看绝对为零,并且数据集非常不平衡,这些结果非常好!
????????我怀疑我们仍然可以调整这一点,并通过更干净的数据、更明智的主题模型选择和潜在的更多主题来获得更好的结果,以便我们可以捕获数据中的更多差异。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【2022《网络技术》样题】求1+2+3+...+100的值。
- C++面向对象语法总结(三)
- Mysql查询与更新语句的执行
- 【JaveWeb教程】(4)Web前端基础:JavaScript入门不再难:一篇文章教你轻松搞定JavaScript事件与事件绑定 附详细案例示例详解
- 【JAVA】在 Queue 中 poll()和 remove()有什么区别
- 编程江湖:Python探秘之旅-----数据结构的迷宫(四)
- AG16KDDF256 User Manual
- NodeJs 第六章 简单了解数据库(MySql)
- 【深度学习目标检测】十一、基于深度学习的电网绝缘子缺陷识别(python,目标检测,yolov8)
- C++(12)——string